编码和加密
文章目录
- 转义
-
- 第一种转义场景
- 第二种转义场景
- 转义的总结
- 编码
-
- 生活化地理解编码
- 技术相关的编码
-
- 什么是乱码
- 字符编码
-
- ASCII 码
- 非 ASCII 编码
- Unicode
- Unicode 的问题
- UTF-8
- Unicode 与 UTF-8 之间的转换
- Base64编码原理
-
- Base64具体转换步骤
- 示例说明
- 位数不足情况
- 注意事项
- 验证
- Url编码 (百分号编码)
-
- 哪些字符需要编码?
-
- 1、URL特殊字符转义,URL中一些字符的特殊含义,基本编码规则如下:
- 2、不需要编码的字符:
- 3、需要编码的字符:
- 如何对Url中的非法字符进行编码
- URL具体编码处理方法
- 案例
- 加密
-
- 加密算法
- 哈希
转义
第一种转义场景
绝大多数的开发者都曾经在自己学习第一个编程语言时,就遇到了这个概念。以经典的 C 语言中字符串中的字符转义为例。
如果在一个字符串中存在一个 ",那么就需要在 " 前添加 ** 才能够正常的表示,比如下面这样。
char* universal_law = "月老板说:\"世界上本也不存在'银弹'。一套框架解决不了所有问题。\""
之所以需要这样,是因为对于字符串来说," 本身就是表示一个字符串的起止符号。如果不进行转义,那么编译器将无法正确的识别其中的 " 哪些是分隔符,哪些是字符串内部的 "。
所以,第一种需要转义的场景就是:如果不进行转义就可能与语法规定的某些内容产生混淆,所以这些内容都被设计为需要转义。
基于这种场景,可以在很多的编程语言和概念中找到这种场景的体现:
- java
String honor = "月老板-\"赛博坦首席技术官\"";
对 " 进行转义
- C#
var proverbs = "月老板:\"这里不要写死,下次需求必改\"";
对 " 进行转义
- XML
<nb>月老板的衬衫价格>99磅6便士</nb>
> 是对 > 的转义,> 是 XML 的边界符
- 正则表达式
\d+\\\.\d+
. 表示一个.,因为在正则表达式中. 表示匹配除 \n 和 \r 之外的任何单个字符。
\ 表示一个 \,转义字符的转义表示。
第二种转义场景
当然,另外还有一种场景,同样还是以 C 语言为例,看一下下面这个例子:
char* hammurabi_no1 = "月落大佬:\"业务复杂度不会因为系统设计变化而减少,\r\n它只是从一个地方转移到了另外的地方。\""
其中的 \r 和 \n 也是一种转义场景的使用。他们分别表示一个回车符和换行符。之所以要转义,是因为正常情况下,这样的字符是不可见的,对于这种字符,不过不采用转义的形式进行表达,那么会比较困难,因为语言设计者设计了这种转义的方式来表达不容易表达的字符。
因此,可以总结出第二种需要转义的场景:转义可以使得表达内容的方式更加容易,更加容易理解,所以设计了这类转义规则。
基于这种场景,也可以在很多编程语言和概念中找到对应的体现:
- C#
var colorOfYueluoShirt = 0xFFFFFF;
0xFFFFFF 表示一个十六进制数,对应的十进制数是 16777215。0xFFFFFF 的表达形式更容易阅读。
- HTML
<nb>月老板的衬衫价格>966¥</nb>
¥;是对¥的转义,因为在期初的 HTML 中,只能用 ASCII 表中的字符进行表达,所以当时设计了这种方式。
除了在 IT 领域,在其他领域其实也存在类似第二场景的应用。例如在中国的航空领域,对于数字的念法有特殊的处理:7 读作拐,0 读作洞,1 读作幺,2 读作两。经过这样的 “转义” 处理,可以避免误听而造成的困扰。
转义的总结
总结来说,转义规则的设计,主要解决了两种场景下对代码的表达问题:
- 如果不进行转义就可能与语法规定的某些内容产生混淆,所以这些内容都被设计为需要转义。
- 转义可以使得表达内容的方式更加容易,更加容易理解,所以设计了这类转义规则。
值得一提的是,很多名称中包含有 escape 或者 unescape 的函数或者方法都表明了它们与转义有关。
编码
编码(encode)是信息从一种形式或格式转换为另一种形式的过程。相应的,解码(decode)是编码的逆过程。
比如经常会听到 ASCII 编码、UTF8 编码、GBK 编码、Base64 编码、URL 编码、HTML 编码、摩斯电码等等一些和编码有关的概念。
生活化地理解编码
在了解编码之前,首先通过一个生活化的例子来了解一下 “什么是信息,什么是信息的载体”。
全世界,对于 “我爱你” 这样一句话的表达方式千差万别。口头表达,书面表达,肢体表达,普通话表达,英语表达,音乐表达,绘画表达。甚至有生之年我们可以脑电波表达。但不论表达方式是如何的,其中包含的信息可以是一致的。都是为了传达 “我爱你” 这样的一个核心价值。
在以上这段表述中,可以将 “我爱你” 这样的概念理解为 “信息”。而各种表达方式理解为这个信息的各种载体。
那么,回到编程的世界中来。计算机中的信息主要的载体是以电磁信号的物理载体存在于计算机世界中。那么如果要将现实世界复杂的内容都依靠这种载体来表达,就需要进行转化,我们可以将这种转化理解为编码。结合前文生活化的例子,使用普通话来表达 “我爱你” 这个信息,就可以理解为使用普通话来编码这个信息。
因此,编码,其可以理解为,采用一种新的载体来表示前一个载体所表达的信息。
可以套用类似这样一个公式来理解:XX 编码,将 A 编码为 B,以实现通过 B 进行存储或传输传输的目的。
技术相关的编码
那么,采用这样的概念,我们来理解一下以往见到的各种技术概念:
文本文件编码,将 “文本数据” 编码为 “二进制数据”,以实现通过 “二进制数据” 进行存储或者传输的目的
文本文件在计算机中,最终的载体是二进制文件的形式存在。早起,由于计算机诞生在美国,文本内容也只包含有英文内容。因此当时只要使用 ASCII 进行编码就可以了。但是后来随着计算机的普及,需要表达的信息越来越多了。因此诞生了 Unicode、GB2312 等等编码形式。但不论如何,这些编码其实都是对文本信息的编码形式。
Base64 编码,将 “二进制数据” 编码为 “64 个可打印字符的组合”,以实现通过 “可打印字符的形式” 进行存储或者传输的目的
在 Web 场景中,在有些地方限制了数据传输的方式。例如,在 URL,只能传递文本。因此,如果想要传输一组二进制数据。那么可以选用 Base64 编码,将二进制数据编码为可打印的字符串。这样才能完成 URL 上二进制数据的传输。
URL 编码,将 “非数字字母字符” 编码为 “十六进制转义序列”,以实现通过 “十六进制转义序列” 进行传输的目的。
如果需要在 URL 中传递中文作为参数,或者需要在 URL 中传递空格、&、?、= 等等特殊符号。这个时候就需要进行 URL 编码。例如月老板会被编码为 %E6%9C%88%E8%80%81%E6%9D%BF。编码的目的 HTTP 协议的内在要求,通过这种形式,可以浏览器表单数据的打包。
总的来说,通过编码,可以转化信息表达的载体。这样就可以利用新载体带来的好处。这里也有一些生活化的例子:
摩斯电码,将 “文本数据” 编码为 “点横组成的电信号”,以实现通过 “电报” 进行传输的目的。
例如:
-·-- ··- · ·-·· ··- --- ·· ··· - ···· · -- --- ··· - ··-· ·- -- --- ··- ··· -·· ·- ·-·· ·- ---
值得一提的是,很多名称中包含有 encode 或者 decode 的函数或者方法都表明了它们与编码有关。
什么是乱码
根据上文提到的公式,编码是完成 A->B 的载体转化过程。那么同样可以定义 A->B 的逆过程 B->A 为 “解码”。
一般,如果解码之后无法正确还原原来 A 所表达的信息,我们会说出现了乱码。例如,使用 GB2312 的方式去解码一个 UTF8 编码的文件,那么就会出现乱码。
当然,更加常见的情况是,当开发者,特别是初入的新晋工程师,看到自己无法理解的文本,就说:“这是乱码。”
总的来说,乱码通常来说只是因为选用的解码方式和编码方式不同,而导致信息失真的情况。选用正确的编码就能够解读出正确的信息。
字符编码
字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。

因此,Unicode字符集应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
现在,捋一捋ASCII编码和Unicode编码的区别:
- ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符’0’和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:
- 如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会**被编码成4-6个字节。**如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:

从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:

浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:

所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。
ASCII 码
我们知道,计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
ASCII 码一共规定了128个字符的编码,比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
非 ASCII 编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0–127表示的符号是一样的,不一样的只是128–255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 256 x 256 = 65536 个符号。
中文编码的问题需要专文讨论,这篇笔记不涉及。这里只指出,虽然都是用多个字节表示一个符号,但是GB类的汉字编码与后文的 Unicode 和 UTF-8 是毫无关系的。
Unicode
正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
Unicode 的问题
需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,
-
第一个问题是,如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
-
第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode
统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:
- 1)出现了 Unicode 的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 Unicode。
- 2)Unicode 在很长一段时间内无法推广,直到互联网的出现。
UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8 是 Unicode 的实现方式之一。
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
- 1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII
码是相同的。 - 2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n +
1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。

跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是以汉字严为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
Unicode 与 UTF-8 之间的转换
通过上一节的例子,可以看到严的 Unicode码 是4E25,UTF-8 编码是E4B8A5,两者是不一样的。它们之间的转换可以通过程序实现。
有一个最简单的转化方法,就是使用内置的记事本小程序notepad.exe。打开文件后,点击文件菜单中的另存为命令,会跳出一个对话框,在最底部有一个编码的下拉条。
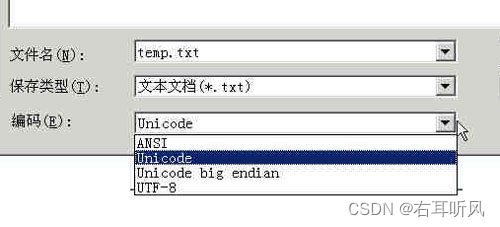
里面有四个选项:ANSI,Unicode,Unicode big endian和UTF-8。
- 1)ANSI是默认的编码方式。对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对 Windows简体中文版,如果是繁体中文版会采用 Big5 码)。
- 2)Unicode编码这里指的是notepad.exe使用的 UCS-2 编码方式,即直接用两个字节存入字符的 Unicode码,这个选项用的 little endian 格式。
- 3)Unicode big endian编码与上一个选项相对应。我在下一节会解释 little endian 和 big endian
的涵义。 - 4)UTF-8编码,也就是上一节谈到的编码方法。
Base64编码原理
目前Base64已经成为网络上常见的传输8Bit字节代码的编码方式之一。在做支付系统时,系统之间的报文交互都需要使用Base64对明文进行转码,然后再进行签名或加密,之后再进行(或再次Base64)传输。那么,Base64到底起到什么作用呢?
在参数传输的过程中经常遇到的一种情况:使用全英文的没问题,但一旦涉及到中文就会出现乱码情况。与此类似,网络上传输的字符并不全是可打印的字符,比如二进制文件、图片等。Base64的出现就是为了解决此问题,它是基于64个可打印的字符来表示二进制的数据的一种方法。
电子邮件刚问世的时候,只能传输英文,但后来随着用户的增加,中文、日文等文字的用户也有需求,但这些字符并不能被服务器或网关有效处理,因此Base64就登场了。随之,Base64在URL、Cookie、网页传输少量二进制文件中也有相应的使用。
Base64的原理比较简单,每当我们使用Base64时都会先定义一个类似这样的数组:
[‘A’, ‘B’, ‘C’, … ‘a’, ‘b’, ‘c’, … ‘0’, ‘1’, … ‘+’, ‘/’]
上面就是Base64的索引表,字符选用了"A-Z、a-z、0-9、+、/" 64个可打印字符,这是标准的Base64协议规定。在日常使用中我们还会看到“=”或“==”号出现在Base64的编码结果中,“=”在此是作为填充字符出现,后面会讲到。
Base64具体转换步骤
- 第一步,将待转换的字符串每三个字节分为一组,每个字节占8bit,那么共有24个二进制位。
- 第二步,将上面的24个二进制位每6个一组,共分为4组。
- 第三步,在每组前面添加两个0,每组由6个变为8个二进制位,总共32个二进制位,即四个字节。
- 第四步,根据Base64编码对照表(见下图)获得对应的值。
0 A 17 R 34 i 51 z
1 B 18 S 35 j 52 0
2 C 19 T 36 k 53 1
3 D 20 U 37 l 54 2
4 E 21 V 38 m 55 3
5 F 22 W 39 n 56 4
6 G 23 X 40 o 57 5
7 H 24 Y 41 p 58 6
8 I 25 Z 42 q 59 7
9 J 26 a 43 r 60 8
10 K 27 b 44 s 61 9
11 L 28 c 45 t 62 +
12 M 29 d 46 u 63 /
13 N 30 e 47 v
14 O 31 f 48 w
15 P 32 g 49 x
16 Q 33 h 50 y
从上面的步骤我们发现:
- Base64字符表中的字符原本用6个bit就可以表示,现在前面添加2个0,变为8个bit,会造成一定的浪费。因此,Base64编码之后的文本,要比原文大约三分之一。
- 为什么使用3个字节一组呢?因为6和8的最小公倍数为24,三个字节正好24个二进制位,每6个bit位一组,恰好能够分为4组。
示例说明
以下图的表格为示例,我们具体分析一下整个过程。

- 第一步:“M”、“a”、"n"对应的ASCII码值分别为77,97,110,对应的二进制值是01001101、01100001、01101110。如图第二三行所示,由此组成一个24位的二进制字符串。
- 第二步:如图红色框,将24位每6位二进制位一组分成四组。
- 第三步:在上面每一组前面补两个0,扩展成32个二进制位,此时变为四个字节:00010011、00010110、00000101、00101110。分别对应的值(Base64编码索引)为:19、22、5、46。
- 第四步:用上面的值在Base64编码表中进行查找,分别对应:T、W、F、u。因此“Man”Base64编码之后就变为:TWFu。
位数不足情况
上面是按照三个字节来举例说明的,如果字节数不足三个,那么该如何处理?
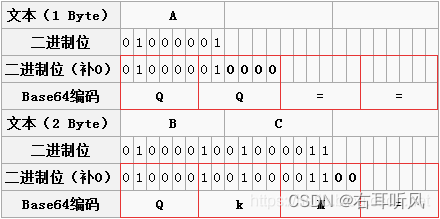
- 两个字节:两个字节共16个二进制位,依旧按照规则进行分组。此时总共16个二进制位,每6个一组,则第三组缺少2位,用0补齐,得到三个Base64编码,第四组完全没有数据则用“=”补上。因此,上图中“BC”转换之后为“QKM=”;
- 一个字节:一个字节共8个二进制位,依旧按照规则进行分组。此时共8个二进制位,每6个一组,则第二组缺少4位,用0补齐,得到两个Base64编码,而后面两组没有对应数据,都用“=”补上。因此,上图中“A”转换之后为“QQ==”;
注意事项
大多数编码都是由字符串转化成二进制的过程,而Base64的编码则是从二进制转换为字符串。与常规恰恰相反,
Base64编码主要用在传输、存储、表示二进制领域,不能算得上加密,只是无法直接看到明文。也可以通过打乱Base64编码来进行加密。
中文有多种编码(比如:utf-8、gb2312、gbk等),不同编码对应Base64编码结果都不一样。
验证
上面我们已经看到了Base64就是用6位(2的6次幂就是64)表示字符,因此成为Base64。同理,Base32就是用5位,Base16就是用4位。
最后,我们用一段Java代码来验证一下上面的转换结果:
import sun.misc.BASE64Encoder;
/**
* @author zzs
*/
public class Base64Utils {
public static void main(String[] args) {
String man = "Man";
String a = "A";
String bc = "BC";
BASE64Encoder encoder = new BASE64Encoder();
System.out.println("Man base64结果为:" + encoder.encode(man.getBytes()));
System.out.println("BC base64结果为:" + encoder.encode(bc.getBytes()));
System.out.println("A base64结果为:" + encoder.encode(a.getBytes()));
}
}
打印结果为:
Man base64结果为:TWFu
BC base64结果为:QkM=
A base64结果为:QQ==
Url编码 (百分号编码)
为什么要编码转义?
通常如果一样东西需要编码,说明这样东西并不适合传输。原因多种多样,如Size过大,包含隐私数据,对于Url来说,之所以要进行编码,是因为Url中有些字符会引起歧义。
例如Url参数字符串中使用key=value键值对这样的形式来传参,键值对之间以&符号分隔,如/s?q=abc&ie=utf-8。如果你的value字符串中包含了=或者&,那么势必会造成接收Url的服务器解析错误,因此必须将引起歧义的&和=符号进行转义,也就是对其进行编码。
又如,Url的编码格式采用的是ASCII码,而不是Unicode,这也就是说你不能在Url中包含任何非ASCII字符,例如中文。否则如果客户端浏览器和服务端浏览器支持的字符集不同的情况下,中文可能会造成问题。
Url编码的原则就是使用安全的字符(没有特殊用途或者特殊意义的可打印字符)去表示那些不安全的字符。

表明浏览器只对url中的非ASCII码字符进行编码
哪些字符需要编码?
1、URL特殊字符转义,URL中一些字符的特殊含义,基本编码规则如下:
- 1、空格换成加号(+)
- 2、正斜杠(/)分隔目录和子目录
- 3、问号(?)分隔URL和查询
- 4、百分号(%)制定特殊字符
- 5、#号指定书签
- 6、&号分隔参数
2、不需要编码的字符:
RFC3986文档对Url的编解码问题做出了详细的建议,指出了哪些字符需要被编码才不会引起Url语义的转变,以及对为什么这些字符需要编码做出了相应的解释。
1、在US-ASCII字符集中没有的可打印字符:Url中只允许使用可打印字符。US-ASCII码中的10-7F字节全都表示控制字符,这些字符都不能直接出现在Url中。同时,对于80-FF字节(ISO-8859-1),由于已经超出了US-ACII定义的字节范围,因此也不可以放在Url中。
2、保留字符:Url可以划分成若干个组件,协议、主机、路径等。有一些字符(?#[]@)是用作分隔不同组件的。例如:冒号用于分隔协议和主机,/用于分隔主机和路径,?用于分隔路径和查询参数,等等。还有一些字符(!$&'()*+,;=)用于在每个组件中起到分隔作用的,如=用于表示查询参数中的键值对,&符号用于分隔查询多个键值对。当组件中的普通数据包含这些特殊字符时,需要对其进行编码。
RFC3986文档规定,Url中只允许包含以下四种:
1、英文字母(a-zA-Z)
2、数字(0-9)
3、-_.~ 4个特殊字符
4、所有保留字符,RFC3986中指定了以下字符为保留字符(英文字符): ! * ' ( ) ; : @ & = + $ , / ? # [ ]
3、需要编码的字符:
如果需要在URL中用到特殊字符,需要将这些特殊字符换成相应的十六进制的值.
不安全字符:有一些字符,当他们直接放在Url中的时候,可能会引起解析程序的歧义。这些字符被视为不安全字符,原因有很多。
- 空格:Url在传输的过程,或者用户在排版的过程,或者文本处理程序在处理Url的过程,都有可能引入无关紧要的空格,或者将那些有意义的空格给去掉。
- 引号以及<>:引号和尖括号通常用于在普通文本中起到分隔Url的作用
- #:通常用于表示书签或者锚点
- %:百分号本身用作对不安全字符进行编码时使用的特殊字符,因此本身需要编码
- {}|^[]`~:某一些网关或者传输代理会篡改这些字符
需要注意的是,对于Url中的合法字符,编码和不编码是等价的,但是对于上面提到的这些字符,如果不经过编码,那么它们有可能会造成Url语义的不同。因此对于Url而言,只有普通英文字符和数字,特殊字符$-_.+!*'()还有保留字符,才能出现在未经编码的Url之中。其他字符均需要经过编码之后才能出现在Url中。
但是由于历史原因,目前尚存在一些不标准的编码实现。例如对于~ 符号,虽然RFC3986文档规定,对于波浪符号~,不需要进行Url编码,但是还是有很多老的网关或者传输代理会。
如何对Url中的非法字符进行编码
Url编码通常也被称为百分号编码(Url Encoding,also known as percent-encoding),是因为它的编码方式非常简单,使用%百分号加上两位的字符——0123456789ABCDEF——代表一个字节的十六进制形式。Url编码默认使用的字符集是US-ASCII。例如a在US-ASCII码中对应的字节是0x61,那么Url编码之后得到的就是%61,我们在地址栏上输入http://g.cn/search?q=%61%62%63,实际上就等同于在google上搜索abc了。又如@符号在ASCII字符集中对应的字节为0x40,经过Url编码之后得到的是%40。
对于非ASCII字符,需要使用ASCII字符集的超集进行编码得到相应的字节,然后对每个字节执行百分号编码。对于Unicode字符,RFC文档建议使用utf-8对其进行编码得到相应的字节,然后对每个字节执行百分号编码。如"中文"使用UTF-8字符集得到的字节为0xE4 0xB8 0xAD 0xE6 0x96 0x87,经过Url编码之后得到"%E4%B8%AD%E6%96%87"。
如果某个字节对应着ASCII字符集中的某个非保留字符,则此字节无需使用百分号表示。例如"Url编码",使用UTF-8编码得到的字节是0x55 0x72 0x6C 0xE7 0xBC 0x96 0xE7 0xA0 0x81,由于前三个字节对应着ASCII中的非保留字符"Url",因此这三个字节可以用非保留字符"Url"表示。最终的Url编码可以简化成"Url%E7%BC%96%E7%A0%81" ,当然,如果你用"%55%72%6C%E7%BC%96%E7%A0%81"也是可以的。
列举带有特殊字符的参数替换成另一些代替的参数,如下所示 :
字符 - URL编码值
空格 - %20 (URL中的空格可以用+号或者编码值表示)
" - %22
# - %23
% - %25
& - %26
( - %28
) - %29
+ - %2B
, - %2C
/ - %2F
: - %3A
; - %3B
< - %3C
= - %3D
> - %3E
? - %3F
@ - %40
\ - %5C
| - %7C
{ - %7B
} - %7D
URL具体编码处理方法
用URLEncode先对你原始url做个编码,然后使用编码后的String。
encodeURIComponent(JSON.stringify(files)) 加一下encodeURIComponen 处理即可。
web端:Javascript的escape(),encodeURIComponent(),encodeURI ()这三个函数进行URL编码,防止特殊字符接收不到。
案例
在将tomcat升级到7.0.81版后,发现系统的有些功能不能使用了,查询日志发现是有些地址直接被tomcat认为存在不合法字符,返回HTTP 400错误响应,错入信息如下:

1、原因分析
经了解,这个问题是高版本tomcat中的新特性:就是严格按照 RFC 3986规范进行访问解析,而 RFC 3986规范定义了Url中只允许包含英文字母(a-zA-Z)、数字(0-9)、-_.~4个特殊字符以及所有保留字符(RFC3986中指定了以下字符为保留字符:! * ’ ( ) ; : @ & = + $ , / ? # [ ])。而我们的系统在通过地址传参时,在url中传了一段json,传入的参数中有"{"不在RFC3986中的保留字段中,所以会报这个错。
根据(https://bz.apache.org/bugzilla/show_bug.cgi?id=60594) ,从以下版本开始,有配置项能够关闭/配置这个行为:
8.5.x系列的:8.5.12 onwards
8.0.x系列的:8.0.42 onwards
7.0.x系列的:7.0.76 onwards
2、处理方法
…/conf/catalina.properties中,找到最后注释掉的一行 #tomcat.util.http.parser.HttpParser.requestTargetAllow=| ,改成tomcat.util.http.parser.HttpParser.requestTargetAllow=|{},表示把{}放行
Ps:当然也可以在参数传递前对URL先编码。
加密
加密很好理解,在日常生活中也不乏加密的使用场景。特别是在以前的战争中的无线电技术应用历史中,确保己方军事信息不被敌方破解,采用优秀的加密算法是极为重要的军事内容。
加密,可以这样概括:按照一定的算法,将需要表达的信息进行处理,以达到除了信息的发送者和接收者之外,其他人无法识别信息真实内容的目的。
技术上所说加密,加密(encryption)是将明文(plaintext,cleartext)信息改变为难以读取的密文(ciphertext)内容,使之不可读。只有拥有解密方法的对象,经由解密(decryption)过程,才能将密文还原为正常可读的内容。
技术上,有需要使用加密的场景:
- HTTPS,安全的 HTTP 通信通道,通过加密算法来确保浏览器接收到的数据没有被篡改,未被泄露
- SSH,为建立在应用层基础上的安全协议。SSH 是较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH
协议可以有效防止远程管理过程中的信息泄露问题。 - SSR。SSR 是各种集换式卡牌游戏中,卡牌稀有度级别分类的一种。(大雾)
这里需要特别说的是编码和加密的区别和联系:
- 编码的目的是为了转换信息的载体,使得转换后的载体更好传输或者存储。但是加密是为了安全,防止被识别。
- 加密需要一个或者一份密钥进行加密和解密处理。安全是加密算法,在没有密钥的情况下,几乎不可能被破解。但是编码并不需要密钥。
所以要简单区分是编码还是加密,可以简单套用这个理解:在算法完全公开的情况下,如果还需要密钥,那么是加密。如果不需要密钥,只能算是编码。
结合生活例子理解一下加密和编码的区别:存在这样一段字符串Мистер Мун, Навсегда Бог. 这并不是加密,因为这是一段正常的俄语。不能因为看不懂就说他是加密,因为如果懂俄语,会用俄语解码这段信息,就能知道他表达的意思是:“月先生,永远的神”。
值得一提的是,很多名称中包含有 encrypt 或者 decrypt 的函数或者方法都表明了它们与加密有关。
加密算法
现代密码学中的加密算法可以分为两类:对称加密(Symmetric encryption)和非对称加密(Asymmetric encryption)。
对称加密就是将信息使用一个密钥进行加密,解密时使用同样的密钥,同样的算法进行解密。
非对称加密,又称公开密钥加密,是加密和解密使用不同密钥的算法,一个是公开密钥,一个是私有密钥,一个用作加密的时候,另一个则用作解密,虽然两个密钥在数学上相关,但如果知道了其中一个,并不能凭此计算出另外一个。在通信中,加密通常使用的是对方的公钥,当对方收到密文后可以使用自己的私钥解密。如果加密使用的是自己的私钥,则密文可由任何人解密,由此可验证该文件必定出自该用户,这亦称作数字签名(Digital Signature)。
跑题一下,实际上为了性能,数字签名并不是直接使用私钥加密明文,而是使用私钥加密明文的哈希值。
常见的对称加密算法有 DES、3DES、AES、RC5 等。
常见的非对称加密算法有 RSA、DSA、ECDSA、Elgamal 等。
非对称加密在计算上相当复杂,速度远远比不上对称加密,因此,在一般实际情况下,往往通过非对称加密来随机创建临时的对称密钥,亦即对话键,然后才通过对称加密来传输大量、主体的数据。
加密算法实质上是密码算法中的一种,另一种则是哈希(hash)算法。
哈希
哈希算法,又称为散列算法,就是把任意长度的输入变换成固定长度的输出,是一种不可逆的算法,也就是说不能通过密文(即哈希值)反算出明文,这是一种单向加密的算法。另外,多个不同的明文可能会得到同一个密文,因为值域是有限的,这种情况称为冲突。一个优秀的哈希算法会尽量的减少这种冲突性。
常见的哈希算法有 MD5、SHA-1、SHA-256、CRC-32、CRC-64 等。
注意:
- 密码学建议,不要使用任何自己创造的私有加密算法,应该使用广泛使用的公开加密算法,这些都是已被证明安全的。
- 编码与加密主要的区别在于,所用的 Key 是否是公共所知的,或者说,编码根本就没有 Key。