在google colab上利用yolov4(darknet版)训练自定义数据集(详细版)
目录
一、前言
二、数据集架构介绍
三、在Google Colab上配置darknet环境
四、训练yolov4模型
1. 文件修改
2. 训练和测试效果
一、前言
由于很多小伙伴没有好的电脑显卡配置或者服务器,跑深度学习算法相对会很困难。我最近在Google colab上用yolov4算法训练了自己的数据集,最终模型在测试集下的平均精度mAP达到了92.6%。该平台可以较方便地训练中小型数据量的深度学习算法,不用配置深度学习环境。免费版每天可以连续使用数个小时,只不过中途会有中断的现象。大家如果想更稳定地训练模型,可以考虑开一个会员哟。
YOLOv4: Optimal Speed and Accuracy of Object Detection论文地址:https://arxiv.org/pdf/2004.10934.pdf
yolov4作者的github:https://github.com/AlexeyAB/darknet
二、数据集架构介绍
建立VOC2007格式数据集,VOC2007数据集文件夹下包含images(图片)和Annotations(图片对应的标签,格式是.xml)两个文件夹。打标YOLO格式的数据标签并制作数据集可参考我的这篇博客:
https://blog.csdn.net/weixin_49929808/article/details/120661388?spm=1001.2014.3001.5501
支持yolov4算法训练的的数据集架构包括:images(图片+yolo格式标签)和test.txt、train.txt、val.txt(图片路径信息)。
运行shengc_txt.py文件,生成ImageSets文件夹,并在ImageSets下生成test.txt,train.txt,trainval.txt,val.txt 四个文件夹(存放图片的文件名)。shengc_txt.py代码如下(路径需要自己修改哟):
import os
import random
trainval_percent = 0.2
train_percent = 0.8
xmlfilepath = '/content/drive/MyDrive/yolov4/VOC2007/Annotations'
txtsavepath = '/content/drive/MyDrive/yolov4/VOC2007/ImageSets'
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('/content/drive/MyDrive/yolov4/VOC2007/ImageSets/trainval.txt', 'w')
ftest = open('/content/drive/MyDrive/yolov4/VOC2007/ImageSets/test.txt', 'w')
ftrain = open('/content/drive/MyDrive/yolov4/VOC2007/ImageSets/train.txt', 'w')
fval = open('/content/drive/MyDrive/yolov4/VOC2007/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()生成的4个.txt文件格式如下:

接下来执行VOC_yolo.py文件,在VOC2007文件夹下生成test.txt、train.txt、val.txt(包含图片路径信息),还会产生一个labels文件夹(.xml格式转化为.txt格式),我们需要将labels里的文件全部复制进images文件里。VOC_yolo.py代码如下(修改目标类别和路径):
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ["orange"] # 数据集目标类别
# 将xml数据格式转化为YOLO数据格式(.txt)
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('/content/drive/MyDrive/yolov4/VOC2007/Annotations/%s.xml' % (image_id))
out_file = open('/content/drive/MyDrive/yolov4/VOC2007/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('/content/drive/MyDrive/yolov4/VOC2007/labels/'):
os.makedirs('/content/drive/MyDrive/yolov4/VOC2007/labels/')
image_ids = open('/content/drive/MyDrive/yolov4/VOC2007/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('/content/drive/MyDrive/yolov4/VOC2007/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('/content/drive/MyDrive/yolov4/VOC2007/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close() 到目前为止,yolov4的数据集VOC2007就构建好了,包括:images(图片+yolo格式标签)和test.txt、train.txt、val.txt(图片路径信息)。生成的test.txt、train.txt、val.txt格式如下 :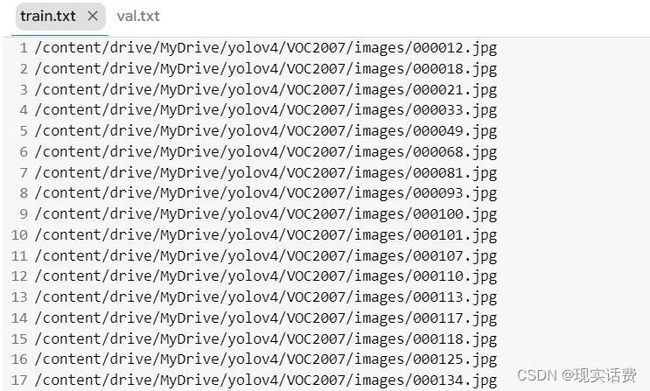
三、在Google Colab上配置darknet环境
1. 需要一个谷歌账号,登录google colab平台: https://drive.google.com
2. 在我的云端硬盘中新建一个yolov4文件夹,用于放VOC2007数据集和darknet源码。将VOC2007数据集上传到该yolov4文件夹下,darknet源码是之后git clone下载到该文件夹下。

3. 鼠标右击空白处,点更多,新建一个Google colab。

4. 新建的google colab如下:

5. 需要在平台服务器上挂载我们自己的云端硬盘,这样我们就可以在服务器上方便访问我们的云端硬盘。挂载成功后,右端会出现MyDrive文件夹。
挂载硬盘的指令如下:
import os
from google.colab import drive
drive.mount('/content/drive')
6. 设置服务器电脑GPU,并Save。

7. 运行shengc_txt.py和VOC_yolo.py代码,生成test.txt、train.txt、val.txt(图片路径信息)。
%cd /content/drive/MyDrive/yolov4/VOC2007 # shengc_txt.py,VOC_yolo.py在VOC2007文件夹下
!python shengc_txt.py
!python VOC_yolo.py
8. 在google colab上下载github上的darknet源码。
%cd /content/drive/MyDrive/yolov4 # darknet源码下载到yolov4文件夹下
!git clone https://github.com/AlexeyAB/darknet9. 执行以下指令修改darknet/Makefile文件参数(opencv,GPU, CUDNN)
%cd /content/drive/MyDrive/yolov4/darknet #进入路径
!sed -i 's/OPENCV=0/OPENCV=1/' Makefile
!sed -i 's/GPU=0/GPU=1/' Makefile
!sed -i 's/CUDNN=0/CUDNN=1/' Makefile10. 验证CUDA版本
#验证CUDA版本
!/usr/local/cuda/bin/nvcc --version11. 编译darknet,在darknet文件下生成darknet。
!make
12. 执行以下指令,解决/bin/bash: ./darknet: Permission denied问题(没有权限)
!chmod +x ./darknet四、训练yolov4模型(darknet版)
1. 文件修改
(1)修改darknet/data/coco.names,修改为自己的目标类别。(或者自己新建一个.names)

(2)制作数据配置文件 yolo.data。
classes=1 #目标类别个数
train=/content/drive/MyDrive/yolov4/VOC2007/train.txt
valid=/content/drive/MyDrive/yolov4/VOC2007/val.txt
names=/content/drive/MyDrive/yolov4/darknet/data/coco.names
backup=backup/(3) 修改yolov4.cfg
A)max_batches:2000*类别数,steps = 0.8*max_batches,0.9*max_batches。由于我的项目数据集只有一类,所以设置为max_batches=2000,steps=1600,1800。

B)修改3处(convolutional和yolo层)
filters=(5+classes)* 3, classes=类别数

2. 训练和测试效果
(1)基于预训练权重yolov4.conv.137训练:
%cd /content/drive/MyDrive/yolov4/darknet #进入项目路径
!./darknet detector train data/yolo.data cfg/yolov4.cfg yolov4.conv.137 -dont_show(2) 接着上次训练断开的位置训练:
!./darknet detector train data/yolo.data cfg/yolov4.cfg backup/yolov4_last.weights -dont_show
(3)用训练好的模型测试测试集的mAP(将yolo.data里的val.txt路径改为test.txt路径)
!./darknet detector map data/yolo.data cfg/yolov4.cfg /content/drive/MyDrive/yolov4/darknet/backup/yolov4_final.weights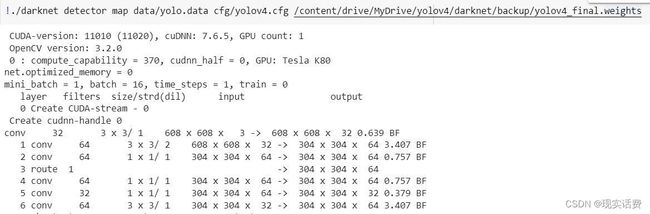
(4)测试单张图片的检测效果:
!./darknet detector test data/yolo.data cfg/yolov4.cfg /content/drive/MyDrive/yolov4/darknet/backup/yolov4_final.weights /content/drive/MyDrive/yolov4/VOC2007/images/000061.jpg -thresh 0.5
更多详细介绍可参考yolov4作者的github:https://github.com/AlexeyAB/darknet
有小伙伴需要预训练模型的话,评论区留言哟!