神经网络深度学习个人笔记 第一章·识别手写数字(持续更新中...)
神经网络与深度学习
Ⅰ.使用神经网络识别手写数字
1.1.感知器
工作方式:
个感知器接受几个二进制输⼊,x1, x2,……,并产生⼀个二进制输出:
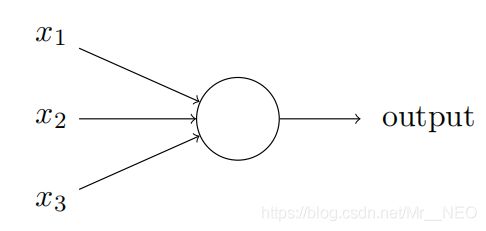
Rosenblatt引⼊权重,w1,w2,w3,……,表示相应输⼊对于输出重要性的实数。神经元的输出(0 、1)则由分配权重后的总和
∑ j w j x j \sum_{j}{w_jx_j} j∑wjxj
⼩于或者⼤于⼀些阈值决定。
阈值是实数,⼀个神经元的参数,代数形式:
O U T P U T = { 0 , if ∑ j w j x j ≤ t h r e s h o l d 1 , if ∑ j w j x j > t h r e s h o l d OUTPUT = \begin{cases} 0, & \text{if }\sum_{j}{w_jx_j}\leq threshold \\ 1, & \text{if }\sum_{j}{w_jx_j}> threshold \end{cases} OUTPUT={0,1,if ∑jwjxj≤thresholdif ∑jwjxj>threshold
e.g
周末就要来了,你听说你所在的城市有个奶酪节。你喜欢奶酪,正试着决定是否去参加。你也许会通过给三个因素设置权重来作出决定:
1 天⽓好吗?
2 你的男朋友或者⼥朋友会不会陪你去?
3 这个节⽇举办的地点是否靠近交通站点?(你没有⻋)
把这三个因素对应地⽤⼆进制变量 x1*, x*2 和x3 来表⽰。例如,如果天⽓好,我们把x1 = 1,如果不好x1 = 0。类似地,如果你的男朋友或⼥朋友同去,x2 = 1,否则 x2 = 0。x3也类似地表示交通情况。
现在,假设你是个嗜好奶酪的吃货,以⾄于即使你的男朋友或⼥朋友不感兴趣,也不管路有多难⾛都乐意去。但是也许你确实厌恶糟糕的天⽓,⽽且如果天⽓太糟你也没法出⻔。你可以使⽤感知器来给这种决策建⽴数学模型。⼀种⽅式是给天⽓权重选择为 w1 = 6 ,其它条件为w2 = 2 和 w3 = 2。w1 被赋予更⼤的值,表⽰天⽓对你很重要,⽐你的男朋友或⼥朋友陪你,或者最近的交通站重要的多。
随着权重和阈值的变化,你可以得到不同的决策模型。例如,假设我们把阈值改为 3 。那么感知器会按照天⽓好坏,或者结合交通情况和你男朋友或⼥朋友同⾏的意愿,来得出结果。换句话说,它变成了另⼀个不同的决策模型。降低阈值则表⽰你更愿意去。
感知器网络
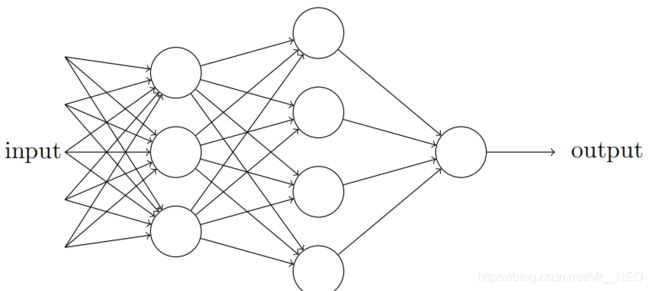
第⼀列感知器 (第⼀层感知器)通过权衡输⼊依据做出三个⾮常简单的决定。第⼆层的感知器呢每⼀个都在权衡第⼀层的决策结果并做出决定。以这种⽅式,⼀个第⼆层中的感知器可以⽐第⼀层中的做出更复杂和抽象的决策。在第三层中的感知器甚⾄能进⾏更复杂的决策。以这种方式,⼀个多层的感知器⽹络可以从事复杂巧妙的决策。
现将感知器重写: ∑ j w j x j \sum_{j}{w_jx_j} j∑wjxj = w·x,b ≡ −threshold,则规则改写为
O U T P U T = { 0 , if w ⋅ x + b ≤ 0 1 , if w ⋅ x + b > 0 OUTPUT = \begin{cases} 0, & \text{if }w·x+b\leq 0 \\ 1, & \text{if }{w·x+b}> 0 \end{cases} OUTPUT={0,1,if w⋅x+b≤0if w⋅x+b>0
偏置b代表了激活感知器的容易程度。若b很大显然更可能输出1。对二元输入,当取 w = ( − 2 , − 2 ) T w=(-2,-2)^T w=(−2,−2)T,b = 3时感知器实际相当于实现了一个与非门 ¬ ( x 1 ⋀ x 2 ) \neg(x1\bigwedge x2) ¬(x1⋀x2)。因此,可以设计一个加法器:
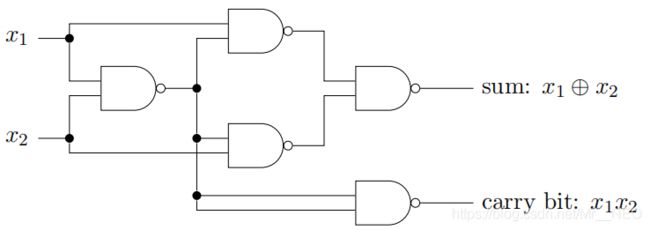
而这实际上相当于感知器网络:
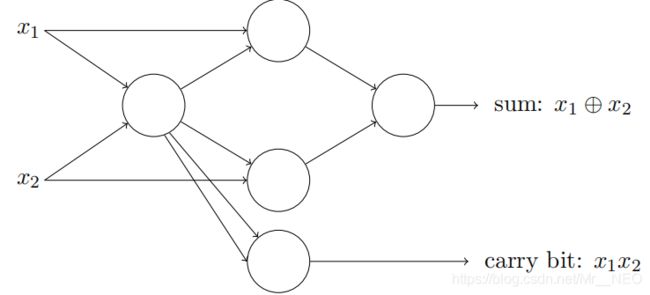
也可以合并底部的两条线,为x1 x2添加输出变成简单的形态:

1.2.S型神经元
S 型神经元和感知器类似,但是被修改为权重和偏置的微⼩改动只引起输出的微⼩变化。
S 型神经元有多个输⼊,x1, x2, . . .。但是这些输⼊可以取 0 和 1 中的任意值,⽽不仅仅是 0 或 1。例如,0.638 . . . 是⼀个 S 型神经元的有效输⼊。同样,S 型神经元对每个输⼊有权重,w1, w2, . . .,和⼀个总的偏置,b。但是输出不是 0 或 1。相反,它现在是 σ(w·x+b),这⾥ σ 被称为 S 型函数。定义为 σ ( z ) = 1 1 + e − z \sigma(z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1。放在一起的输出即为:
O U T P U T = 1 1 + e − ∑ j w j x j − b OUTPUT = \frac{1}{1+e^{-\sum_{j}{w_jx_j}-b}} OUTPUT=1+e−∑jwjxj−b1

如图可见σ函数的情况,在 z → + ∞ z\to+\infin z→+∞时输出1, z → − ∞ z\to-\infin z→−∞时输出0。
σ的平滑意味着权重和偏置的微⼩变化,即 ∆ w j ∆w_j ∆wj 和 ∆b,会使神经元产⽣⼀个微⼩的输出变化 ∆output。
且实际上由微积分的斜率一阶导可知,∆output可以近似为:
Δ o u t p u t ≈ ∑ j ∂ o u t p u t ∂ w j Δ w j + ∂ o u t p u t ∂ b Δ b \Delta{output} \approx \sum\limits_{j}{\frac{\partial output}{\partial w_j}\Delta w_j}+\frac{\partial output}{\partial b}\Delta b Δoutput≈j∑∂wj∂outputΔwj+∂b∂outputΔb
S 型神经元的输出可以用一个约定来控制:例如约定任何至少为 0.5 的输出表示为1
1.3.神经网络的架构
⽹络中最左边的称为输⼊层,其中的神经元称为输⼊神经元。最右边的,即输出层,包含有输出神经元。中间层,这层中的神经元既不是输⼊也不是输出,则被称为隐藏层。多层⽹络有时被称为多层感知器或者MLP。
神经网络大都是以上⼀层的输出作为下⼀层的输⼊。这种网络被称为前馈神经⽹络。这意味着网络中是没有回路的 —— 信息总是向前传播,从不反向回馈。
⼀些⼈工神经⽹络模型,反馈环路是可行的。这些模型被称为递归神经⽹络。这种模型的设计思想,是具有休眠前会在⼀段有限的时间内保持激活状态的神经元。这种激活状态可以刺激其它神经元,使其随后被激活并同样保持⼀段有限的时间。这样会导致更多的神经元被激活,随着时间的推移,我们得到⼀个级联的神经元激活系统。因为⼀个神经元的输出只在⼀段时间后⽽不是即刻影响它的输⼊,在这个模型中回路并不会引起问题。
1.4.⼀个简单的分类手写数字的网络
![]()
假设现在由一个数字图片如上,我们需要做分割、数字的分类。则工作可以着重放在分类上,因为分割可通过不断切分和分类器置信度打分最高的获得。
训练数据会有很多扫描得到的 28 × 28 的手写数字的图像组成,所有输⼊层包含有 784 = 28 × 28个神经元。为了简化忽略 784 中⼤部分的输⼊神经元。输入像素是灰度级的,值为 0.0 表示白色,值为 1.0 表示黑色,中间数值表示逐渐暗淡的灰色。
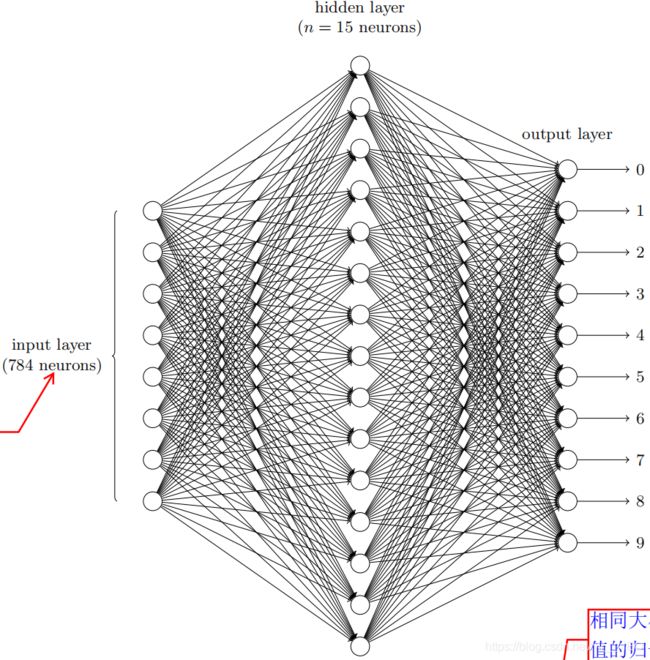
输出采用10个输出神经元而不是4个
2 4 = 16 > 10 2^4=16>10 24=16>10
是因为我们很容易把识别特定数字与10个单元联系,却不容易将其与最高位联系起来。
从十进制到二进制网络转换
通过在上述的三层神经网络加⼀个额外的⼀层就可以实现按位表⽰数字。额外的⼀层把原来的输出层转化为⼀个⼆进制表⽰,如下图所⽰。为新的输出层寻找⼀些合适的权重和偏置。假定原先的 3 层神经⽹络在第三层得到正确输出(即原来的输出层)的激活值⾄少是0.99,得到错误的输出的激活值⾄多是 0.01。
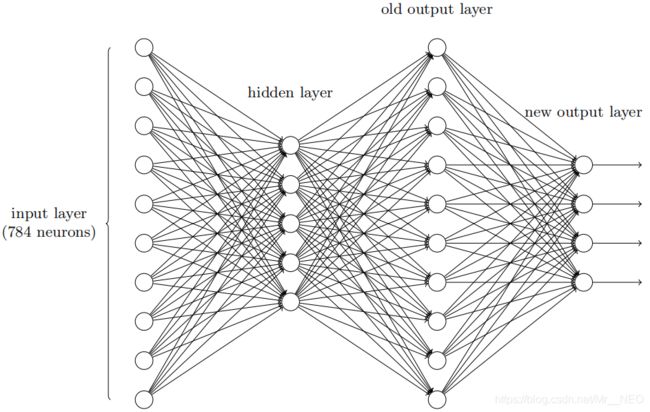
解答:为此我们必须考虑各个数位的情况,看他们的二进制四位表示:
| 原数字 | 二进制表示 | w·x(第一个神经元) |
|---|---|---|
| 0 | 0000 | 0.02 |
| 1 | 0001 | 0.02 |
| 2 | 0010 | 0.02 |
| 3 | 0011 | 0.02 |
| 4 | 0100 | 0.02 |
| 5 | 0101 | 0.02 |
| 6 | 0110 | 0.02 |
| 7 | 0111 | 0.02 |
| 8 | 1000 | 1.00 |
| 9 | 1001 | 1.00 |
然后是理解如何设置权重,我们现在按题意直到输出被激活的值为0.99,没被激活的最大0.01,所以一种最直观的方案就是以0,1为权重:考虑第一位也就是最上面一个神经元,它负责第一位,只有8,9时为1。因此可以考虑用 [ 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 1 , 1 ] T [0,0,0,0,0,0,0,0,1,1]^T [0,0,0,0,0,0,0,0,1,1]T作为第一个神经元的权重,类似定义其它三位。
按照这一情况,我们计算以下所有数字的结果可以得到w·x,以第一个神经元为例在表格中。可见误差为0.02,即我们希望0.02以下的可以不被激发,一个好办法就是把偏置设为-0.02,约定0.98为激发
类似地可以设第二个神经元 [ 0 , 0 , 0 , 0 , 1 , 1 , 1 , 1 , 0 , 0 ] T [0,0,0,0,1,1,1,1,0,0]^T [0,0,0,0,1,1,1,1,0,0]T,第三个神经元 [ 0 , 0 , 1 , 1 , 0 , 0 , 1 , 1 , 0 , 0 ] T [0,0,1,1,0,0,1,1,0,0]^T [0,0,1,1,0,0,1,1,0,0]T,第四个神经元 [ 0 , 1 , 0 , 1 , 0 , 1 , 0 , 1 , 0 , 1 ] T [0,1,0,1,0,1,0,1,0,1]^T [0,1,0,1,0,1,0,1,0,1]T。
那么可以算出一个w·x的结果:
| 数字 | 第二个神经元 | 第三个神经元 | 第四个神经元 |
|---|---|---|---|
| 0 | 0.04 | 0.04 | 0.05 |
| 1 | 0.04 | 0.04 | 1.03 |
| 2 | 0.04 | 1.02 | 0.05 |
| 3 | 0.04 | 1.02 | 1.03 |
| 4 | 1.02 | 0.04 | 0.05 |
| 5 | 1.02 | 0.04 | 1.03 |
| 6 | 1.02 | 1.02 | 0.05 |
| 7 | 1.02 | 1.02 | 1.03 |
| 8 | 0.04 | 0.04 | 0.05 |
| 9 | 0.04 | 0.04 | 1.03 |
可以看出还有一个办法是设计一个总偏置:为它们中最大的非激发下值之上,比如-0.06就可以消去误差,然后规定至少大于0激活。
1.5.使用梯度下降算法进行学习
代价函数
符号x代表训练输入,为了方便,把每个训练输入x看作⼀个28×28 = 784维的向量。每个向量中的项⽬代表图像中单个像素的灰度值。我们用y = y(x)表示对应的期望输出。y是⼀个10维的向量(特定的画成6的训练图像 y ( x ) = ( 0 , 0 , 0 , 0 , 0 , 0 , 1 , 0 , 0 , 0 ) T y(x) = (0,0,0,0,0,0,1,0,0,0)^T y(x)=(0,0,0,0,0,0,1,0,0,0)T 就是⽹络的期望输出)。
为找到合适的偏置与权重来用y(x)拟合所有的x,我们需要一个指标,即代价函数(目标函数,LOSS损失函数):
C ( w , b ) = 1 2 n ∑ x ∣ ∣ y ( x ) − a ∣ ∣ 2 C(w,b) = \frac{1}{2n}\sum_{x}||y(x)-a||^2 C(w,b)=2n1x∑∣∣y(x)−a∣∣2
这里w表示所有的网络中权重的集合,b是所有的偏置,n是训练输⼊数据的个数,a是表示当输⼊为x时输出的向量,求和则是在总的训练输⼊x上进⾏的。C为二次代价函数,也称为均方误差(MSE)。
如果C为0就是最好的情况,它完美拟合了所有图像答案。因此学习过程实际就是一个不断最小化权重和偏置的代价函数C(w, b)的过程
梯度下降法
为了最小化某些函数,比如C(v),v = v1,v2,v3,……,vn,通过导数求极值点是基本不可能的,变量太多。
一种方法是分步为一个不断下降的过程:即一个梯度下降的过程。以两个变量v1,v2为例,则微小变动下:
Δ C ≈ ∂ C ∂ v 1 Δ v 1 + ∂ C ∂ v 2 Δ v 2 \Delta C \approx \frac{\partial C}{\partial v1}\Delta v1+\frac{\partial C}{\partial v2}\Delta v2 ΔC≈∂v1∂CΔv1+∂v2∂CΔv2
重写为向量形式得到: ▽ C = ( ∂ C ∂ v 1 , ∂ C ∂ v 2 ) \bigtriangledown C = (\frac{\partial C}{\partial v1},\frac{\partial C}{\partial v2}) ▽C=(∂v1∂C,∂v2∂C),此为梯度向量, Δ C ≈ ▽ C ⋅ Δ v \Delta C \approx \bigtriangledown C \cdot \Delta v ΔC≈▽C⋅Δv。
现在为了让 Δ C \Delta C ΔC为负数,取 Δ v = − η ▽ C \Delta v = -\eta \bigtriangledown C Δv=−η▽C,则 Δ C ≈ − η ∣ ∣ ▽ C ∣ ∣ 2 \Delta C \approx -\eta ||\bigtriangledown C||^2 ΔC≈−η∣∣▽C∣∣2。这里 η \eta η是一个很小的正数,称为学习速率。
于是通过不断迭代, v ′ = v − η ▽ C v' = v - \eta \bigtriangledown C v′=v−η▽C,我们实现了C的不断缩小,直到全局最小值。
推广到n元同理: Δ v = ( Δ v 1 , Δ v 2 , . . . , Δ v n ) \Delta v = (\Delta v1, \Delta v2, ... , \Delta vn) Δv=(Δv1,Δv2,...,Δvn), ▽ C = ( ∂ C ∂ v 1 , ∂ C ∂ v 2 , . . . , ∂ C ∂ v n ) \bigtriangledown C = (\frac{\partial C}{\partial v1},\frac{\partial C}{\partial v2},...,\frac{\partial C}{\partial vn}) ▽C=(∂v1∂C,∂v2∂C,...,∂vn∂C),且 Δ C ≈ ▽ C ⋅ Δ v \Delta C \approx \bigtriangledown C \cdot \Delta v ΔC≈▽C⋅Δv,取 Δ v = − η ▽ C \Delta v = -\eta \bigtriangledown C Δv=−η▽C,即可。
现在回到二次代价函数,我们的目标就是不断修改权重w和偏置b来让C尽可能小,故现在用它们取代v,此时的C分为两部分:
▽ C = ( ∂ C ∂ w , ∂ C ∂ b ) \bigtriangledown C = (\frac{\partial C}{\partial w},\frac{\partial C}{\partial b}) ▽C=(∂w∂C,∂b∂C)
Δ v = ( Δ w , Δ b ) T \Delta v = (\Delta w, \Delta b)^T Δv=(Δw,Δb)T
故而我们也知道了调整方法: w k ′ = w k − η ∂ C ∂ w k w_k' = w_k-\eta \frac{\partial C}{\partial w_k} wk′=wk−η∂wk∂C, b l ′ = b l − η ∂ C ∂ b l b_l'=b_l-\eta\frac{\partial C}{\partial b_l} bl′=bl−η∂bl∂C。
但是问题是为每个变量求一次偏导后再求平均值会花费巨大时间导致学习很慢,因此可以估算 ▽ C \bigtriangledown C ▽C。
随机梯度下降是通过随机选取少量的m个训练输入作为小批量数据mini-batch来近似,假设样本数量m足够大,期望 ▽ C m \bigtriangledown C_m ▽Cm的平均值大致等于整个 ▽ C \bigtriangledown C ▽C的平均值:
∑ j = 1 m ▽ C X j m ≈ ∑ X ▽ C X n = ▽ C \frac{\sum_{j = 1}^{m}{\bigtriangledown C_{X_j}}}{m} \approx \frac{\sum_{X}{\bigtriangledown C_{X}}}{n} = \bigtriangledown C m∑j=1m▽CXj≈n∑X▽CX=▽C
此时,调整方法也改变为 w k ′ = w k − η m ∂ C X j ∂ w k w_k' = w_k-\frac{\eta}{m} \frac{\partial C_{X_j}}{\partial w_k} wk′=wk−mη∂wk∂CXj
b l ′ = b l − η m ∂ C X j ∂ b l b_l' = b_l-\frac{\eta}{m} \frac{\partial C_{X_j}}{\partial b_l} bl′=bl−mη∂bl∂CXj
完成一次迭代后,再挑选另一随机选定样本数据进行训练直到全部用完,这一周期称为训练迭代期(epoch)
有时,对于方程 C ( w , b ) = 1 2 n ∑ x ∣ ∣ y ( x ) − a ∣ ∣ 2 C(w,b) = \frac{1}{2n}\sum_{x}||y(x)-a||^2 C(w,b)=2n1x∑∣∣y(x)−a∣∣2我们会忽略前面的n,这在对未知数据规模时非常有效。
但注意对于调整法中的m不能随意忽略,因为相当于在改变学习速率。
e.g.
梯度下降算法⼀个极端的版本是把⼩批量数据的⼤⼩设为1。即,假设⼀个训练输⼊x,我们按照规则为
w k ′ = w k − η ∂ C X ∂ w k w_k' = w_k-\eta \frac{\partial C_{X}}{\partial w_k} wk′=wk−η∂wk∂CX
b l ′ = b l − η ∂ C X ∂ b l b_l' = b_l-\eta \frac{\partial C_{X}}{\partial b_l} bl′=bl−η∂bl∂CX更新我们的权重和偏置。然后我们选取另⼀个训练输⼊,再⼀次更新权重和偏置。如此重复。这个过程被称为在线、online、on-line、或者递增学习。在online 学习中,神经⽹络在⼀个时刻只学习⼀个训练输⼊(正如⼈类做的)。对⽐具有⼀个小批量输⼊大小为20 的随机梯度下降。
优点:一个时刻只学习一个训练输入,能让模型迅速的学习到当前时刻的数据。如根据用户浏览的商品,实时的推荐相关的商品;根据行用卡使用行为数据,实时的预测出欺诈行为。速度快了20倍
缺点:对比具有一个小批量输入大小为 20 的随机梯度下降,online 学习的实际上的学习率太大,偶然突发性的噪音数据会极大的影响原本的模型。代表性不够强。
1.6. 实现网络来分类数字
定义一个神经网络类
初始函数
首先需要numpy,快速线性代数用于计算
import numpy as np
class Network(object):
def __init__(self, sizes):
"""The list sizes contains the number of neurons in the respective layers of the network. For example, if the list was [2, 3, 1] then it would be a three-layer network, with the first layer containing 2 neurons, the second layer 3 neurons, and the third layer 1 neuron. The biases and weights for the network are initialized randomly, using a Gaussian distribution with mean 0, and variance 1. Note that the first layer is assumed to be an input layer, and by convention we won't set any biases for those neurons, since biases are only ever used in computing the outputs from later layers."""
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]
神经网络类中初始化的sizes是一个列表,用于存放各层的神经元个数,比如[2,3,1]就是一个有2个神经元的输入层,1个隐藏层和一层的输出神经元。初始时,因为我们不知道偏置改设多少,权重该设多少,因此完全就是随机的,但是这里满足了高斯(正态)分布均值为0方差为1。这个初始化只是提供一种起点而非必要的分布。
深度解析一下numpy的使用:
[np.random.randn(y, 1) for y in sizes[1:]]中外层[]是用于将生成的多个数组处理成列表的格式,而内部可以看到sizes切片去掉了第一层输入层,这是因为输入不需要作偏置和权重,它前面没有层,而for y in sizes[1:]实际上表达的就是从sizes中顺次取出数字y(比如我们举例[2,3,1]就第一个取3,y=3),然后用np.random.randn(y, 1)生成一个满足分布的y×1矩阵组成的列表,这样的话,实际上例子中就是得到两个列表。比如我这里得到的self.biases = [[1.95291,-0.47505,-1.44775],[2.13397]](准确来说是两个矩阵,一个3x1,一个1x1)。所以我们直到,biases[0]存的是第一层到第二层的,biases[1]存第二层到第三层的。
类似地,在设置权重时也是,这里zip()是将数组打包成元组(因为x,y读取要元组格式),很显然权重矩阵是一个y×x的矩阵,其中y对应后面层的神经元个数,x对应前一层,比如[2,3,1]就是一个3×2的矩阵和一个1×3的矩阵,因此x需要刨去最后一层的神经元,y是刨去第一层。
σ的计算
下面可以定义类内函数:
def sigmoid(z):
"""The sigmoid function."""
return 1.0/(1.0+np.exp(-z))
用于做S型函数计算,只要传入wx+b即可获得σ()的输出。
SGD学习函数
最关键的函数是学习函数,即梯度下降函数:
def SGD(self, training_data, epochs, mini_batch_size, eta,
test_data=None):
"""Train the neural network using mini-batch stochastic gradient descent. The training_data is a list of tuples (x, y) representing the training inputs and the desired outputs. The other non-optional parameters are self-explanatory. If test_data is provided then the network will be evaluated against the test data after each epoch, and partial progress printed out. This is useful for tracking progress, but slows things down substantially."""
training_data = list(training_data)
n = len(training_data)
if test_data:
test_data = list(test_data)
n_test = len(test_data)
for j in range(epochs):
random.shuffle(training_data)
mini_batches = [
training_data[k:k+mini_batch_size]
for k in range(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
if test_data:
print("Epoch {} : {} / {}".format(j,self.evaluate(test_data),n_test));
else:
print("Epoch {} complete".format(j))
training_data是训练集,是一个(x,y)元组的列表,x是输入,y是期望输出。x是一个1×784的数组,y是一个1×10的数组,期望的位置为1.0。test_data为测试数据,若给出了则会解析成列表后进行评估。epochs是迭代次数,mini_batch_size是小批量数据的大小,eta是学习速率,对应η。
在每个迭代期内,我们主要做三件事——打乱后生成小批量全覆盖的数据集用于降梯度,不断更新小批量数据集以不断修改网络参数,最终评估。
第一步很简单,就是一个置乱算法shufffle将训练集打乱顺序,然后切片数据
training_data[k:k+mini_batch_size] for k in range(0,n,mini_batch_size)
即切成长度为mini_batch_size的 [ n m i n i _ b a t c h _ s i z e ] [\frac{n}{mini\_batch\_size}] [mini_batch_sizen]个小批量数据集。
第二步进入调整阶段,将数据代入计算下降梯度,我们需要η的学习速率和小数据集以修改我们的权重和偏置,故传入:
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
其具体过程后面会继续分析。
第三步进入评估阶段,即这样的权重和偏置能解释测试集中的多少数据,我们需要知道学习的一个大致进度。所以打印当前迭代期的解释比例:
if test_data:
print("Epoch {} : {} / {}".format(j,self.evaluate(test_data),n_test));
else:
print("Epoch {} complete".format(j))
调整权重和偏置
在单次梯度下降过程中,需要修改偏置与权重,主要依赖于我们的公式:
def update_mini_batch(self, mini_batch, eta):
"""Update the network's weights and biases by applying gradient descent using backpropagation to a single mini batch.The mini_batch is a list of tuples(x, y), and eta is the learning rate."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]
这里np.zeros(shape, dtype=float, order=‘C’)生成一个全0的shape形状的矩阵,这样好方便我们呆会儿可以使用其中的数据而不会出类型错误。delta_nabla_b, delta_nabla_w = self.backprop(x, y)采用了反向传播,但会在第二章讨论。
评估函数
def evaluate(self, test_data):
"""Return the number of test inputs for which the neural network outputs the correct result. Note that the neural network's output is assumed to be the index of whichever neuron in the final layer has the highest activation."""
test_results = [(np.argmax(self.feedforward(x)), y)
for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
这里将已经调整好的权重与偏置代入测试数据进行计算和比对,主要函数是feedforward将输入不断计算传递到输出层网络。argmax是回传括号内列表最大的数据的索引,显然这里就是我们输出1对应的位置。(比如x输出[0.0001,0.02,0.03,0.104,0.998,0.01,0.02,0.01,0.03,0.04]则argmax返回为4,这就是我们识别的目标)
然后,通过把它与右边的期望比对,凡是满足的都加起来布尔值(被强制转换为int类型,真值为1,假为0),得到完全解释部分数据量返回
前向传播的计算函数
def feedforward(self, a):
"""Return the output of the network if a is input."""
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return a
刚刚我们在评估中用了前向传播算出了最终结果,这里就是一个迭代的过程,a是输入,经过第一轮迭代得到的a就是第二层的输出,再把输出这样一直迭代下去,最后就是最后输出层的值,于是我们返回。这里返回的就是一个长度10的数组列表。
至此,所有工作就都完成了。
数据包的解析
使用了MNIST的数据集,载入数据函数打开压缩文件并解析:
def load_data():
f = gzip.open('mnist.pkl.gz', 'rb')
training_data, validation_data, test_data = pickle.load(f, encoding="latin1")
f.close()
return (training_data, validation_data, test_data)
而打包数据则需要做一些处理,将刚刚得到的生数据制作成向量或矩阵的形式,这样才能统一格式后进行计算。
def load_data_wrapper():
tr_d, va_d, te_d = load_data()
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = zip(validation_inputs, va_d[1])
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
def vectorized_result(j):
e = np.zeros((10, 1))
e[j] = 1.0
return e
进行测试
测试分成三步,先载入数据:
training_data, validation_data, test_data = load_data_wrapper()
然后创建神经网络,比如这里是三层的网络(注意头尾必须是784和10)
net = network.Network([784, 30, 10])
然后开始SGD梯度下降:
net.SGD(training_data, 30, 10, 3.0, test_data=test_data)
在这个过程中,我们就可以轻松看到情况了:
Epoch 0 : 9066 / 10000
Epoch 1 : 9265 / 10000
Epoch 2 : 9331 / 10000
Epoch 3 : 9396 / 10000
Epoch 4 : 9412 / 10000
Epoch 5 : 9423 / 10000
Epoch 6 : 9450 / 10000
Epoch 7 : 9474 / 10000
Epoch 8 : 9489 / 10000
Epoch 9 : 9482 / 10000
Epoch 10 : 9516 / 10000
Epoch 11 : 9490 / 10000
Epoch 12 : 9487 / 10000
Epoch 13 : 9498 / 10000
Epoch 14 : 9540 / 10000
Epoch 15 : 9532 / 10000
Epoch 16 : 9506 / 10000
Epoch 17 : 9522 / 10000
Epoch 18 : 9557 / 10000
Epoch 19 : 9552 / 10000
Epoch 20 : 9545 / 10000
Epoch 21 : 9539 / 10000
Epoch 22 : 9567 / 10000
Epoch 23 : 9536 / 10000
Epoch 24 : 9530 / 10000
Epoch 25 : 9530 / 10000
Epoch 26 : 9541 / 10000
Epoch 27 : 9533 / 10000
Epoch 28 : 9527 / 10000
Epoch 29 : 9582 / 10000
(这是我用四层跑的,不过也差不多,95%解释率)
这里主要分析几点:第一,每个人跑出来不一样,因为初始化权重偏置会干扰到结果;第二,提升各层(不含首尾)的神经元数量是一定会提高效果的,但是迭代数量,η的选择也能影响到结果,这是一个综合评价体系;第三,学习速率是一个需要调控找到最优位置的过程:选太小运行会很漫长,而且逐步变好,意味着我们应该调高,但是选太大会导致效果很差,意味着该调小。这点很想我们的学习过程,学太慢的话虽然有起色但是一直会落后,如果epochs设太小就好比期末考试时间太早学不完了;学得太急功近利又会导致囫囵吞枣完全没理解,进而考试吃瘪。