天池龙珠计划_金融风控训练营——Task2 EDA探索性数据分析学习打卡
目录
- 1.学习任务
-
- 天池龙珠计划_金融风控训练营
- Task2 EDA探索性数据分析学习打卡
- 1.1学习目的
- 1.2 学习目标
- 2 学习内容
-
- 2.1 读取文件的拓展知识
-
- 2.1.1 设置chunksize参数
- 2.2 缺失值
-
- 2.2.1 缺失值可视化
- 2.2.2 数据缺失值处理之missingno库
- 2.3 数值特征分析
-
- 2.3.1 数值特征分类
- 2.3.2 数值连续型变量分析
- 2.4 时间格式数据处理
- 2.5 透视表的使用
- 2.6 使用pandas_profiling生成数据报告
- 3 学习总结
- 参考链接
1.学习任务
天池龙珠计划_金融风控训练营
天池龙珠计划_金融风控训练营链接
Task2 EDA探索性数据分析学习打卡
学习文章链接
1.1学习目的
- EDA价值主要在于熟悉了解整个数据集的基本情况(缺失值,异常值),对数据集进行验证是否可以进行接下来的机器学习或者深度学习建模.
- 了解变量间的相互关系、变量与预测值之间的存在关系。
- 为特征工程做准备
1.2 学习目标
- 学习如何对数据集整体概况进行分析,包括数据集的基本情况(缺失值,异常值)
- 学习了解变量间的相互关系、变量与预测值之间的存在关系
- 完成相应学习打卡任务
2 学习内容
从本篇文章中学习到了许多第一次接触到的知识点。
2.1 读取文件的拓展知识
- pandas读取数据时相对路径载入报错时,尝试使用os.getcwd()查看当前工作目录。
- TSV与CSV的区别:
- 从名称上即可知道,TSV是用制表符(Tab,’\t’)作为字段值的分隔符;CSV是用半角逗号(’,’)作为字段值的分隔符;
- Python对TSV文件的支持: Python的csv模块准确的讲应该叫做dsv模块,因为它实际上是支持范式的分隔符分隔值文件(DSV,delimiter-separated values)的。 delimiter参数值默认为半角逗号,即默认将被处理文件视为CSV。当delimiter=’\t’时,被处理文件就是TSV。
- 读取文件的部分(适用于文件特别大的场景)
- 通过nrows参数,来设置读取文件的前多少行,nrows是一个大于等于0的整数。
- 分块读取
2.1.1 设置chunksize参数
使用设置chunksize参数的方法,尽量避免直接对过大的dataframe直接操作,以从csv文件读取数据为例,可以通过read_csv方法的chunksize参数,设定读取的行数,返回一个固定行数的迭代器,每次读取只消耗相应行数对应的dataframe的内存,从而可以有效的解决内存消耗过多的问题。
data_train_sample = pd.read_csv("train.csv",nrows=5)
#设置chunksize参数,来控制每次迭代数据的大小
i = 0 # 控制输出
chunker = pd.read_csv("train.csv",chunksize=5)
for item in chunker:
print(type(item))
#2.2 缺失值
data.isnull()#查看所有缺失值
data.isnull().any()#获取含有缺失值的列
data.isnull().all()#获取全部为NA的列
data.isnull().sum()#获取缺失值合集
data.dropna() #删除缺失值
此外,可以使用pandas 或sklearn 替换缺失值,还可以使用lgb模型可以自动处理缺失值。
2.2.1 缺失值可视化
文章中使用的方法
#nan可视化
missing = data_train.isnull().sum()/len(data_train)
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar()

2.2.2 数据缺失值处理之missingno库
missingno库可以将数据中的缺失值可视化展示,而且使用起来非常简单。
import missingno as msno
msno.matrix(data, labels=True)#无效数据密度显示(矩阵显示)
msno.bar(data)#条形图显示
msno.heatmap(data)#热图相关性显示
msno.dendrogram(data)#树状图显示
2.3 数值特征分析
2.3.1 数值特征分类
特征一般都是由类别型特征和数值型特征组成,而数值型特征又分为连续型和离散型。
#过滤数值型类别特征
def get_numerical_serial_fea(data,feas):
numerical_serial_fea = []
numerical_noserial_fea = []
for fea in feas:
temp = data[fea].nunique()
if temp <= 10:
numerical_noserial_fea.append(fea)
continue
numerical_serial_fea.append(fea)
return numerical_serial_fea,numerical_noserial_fea
numerical_serial_fea,numerical_noserial_fea = get_numerical_serial_fea(data_train,numerical_fea)
通过get_numerical_serial_fea函数将数据过滤分类为连续型和离散型。
2.3.2 数值连续型变量分析
#每个数字特征得分布可视化
f = pd.melt(data_train, value_vars=numerical_serial_fea)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False)
g = g.map(sns.distplot, "value")
- 查看某一个数值型变量的分布,查看变量是否符合正态分布,如果不符合正太分布的变量可以log化后再观察下是否符合正态分布。
- 如果想统一处理一批数据变标准化 必须把这些之前已经正态化的数据提出
- 正态化的原因:一些情况下正态非正态可以让模型更快的收敛,一些模型要求数据正态(eg. GMM、KNN),保证数据不要过偏态即可,过于偏态可能会影响模型预测结果。
2.4 时间格式数据处理
#转化成时间格式 issueDateDT特征表示数据日期离数据集中日期最早的日期(2007-06-01)的天数
data_train['issueDate'] = pd.to_datetime(data_train['issueDate'],format='%Y-%m-%d')
startdate = datetime.datetime.strptime('2007-06-01', '%Y-%m-%d')
data_train['issueDateDT'] = data_train['issueDate'].apply(lambda x: x-startdate).dt.days
- 使用pd.to_datetime处理日期数据
- 用户输入的日期和时间是字符串,要处理日期和时间,首先必须把str转换为datetime。转换方法是通过datetime.strptime()实现,需要一个日期和时间的格式化字符串:
>>> from datetime import datetime
>>> cday = datetime.strptime('2017-8-1 18:20:20', '%Y-%m-%d %H:%M:%S')
>>> print(cday)
2017-08-01 18:20:20
2.5 透视表的使用
透视表是一种可以对数据动态排布并且分类汇总的表格格式。或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table。
pivot_table(data, values=None, index=None, columns=None,aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
#pivot_table有四个最重要的参数index、values、columns、aggfunc
#透视图 索引可以有多个,“columns(列)”是可选的,聚合函数aggfunc最后是被应用到了变量“values”中你所列举的项目上。
pivot = pd.pivot_table(data_train, index=['grade'], columns=['issueDateDT'], values=['loanAmnt'], aggfunc=np.sum)
利用好数据透视表能更好地进行数据分析。
2.6 使用pandas_profiling生成数据报告
pandas_profiling,这个库只需要一行代码就可以生成数据EDA报告。
pandas_profiling基于pandas的DataFrame数据类型,可以简单快速地进行探索性数据分析。
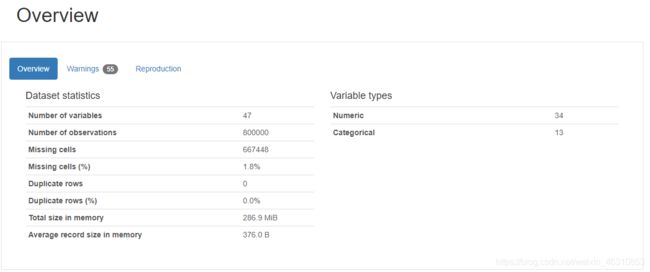
对于数据集的每一列,pandas_profiling会提供以下统计信息:
1、概要:数据类型,唯一值,缺失值,内存大小
2、分位数统计:最小值、最大值、中位数、Q1、Q3、最大值,值域,四分位
3、描述性统计:均值、众数、标准差、绝对中位差、变异系数、峰值、偏度系数
4、最频繁出现的值,直方图/柱状图
5、相关性分析可视化:突出强相关的变量,Spearman, Pearson矩阵相关性色阶图
并且这个报告可以导出为HTML,非常方便查看。
import pandas_profiling
pfr = pandas_profiling.ProfileReport(data_train)
pfr.to_file("./example.html")
3 学习总结
在本次学习打卡中,我了解到了很多新的知识点以及实用的库。例如:
- 了解到EDA的重要性,这个阶段的主要工作还是借助于各个简单的统计量来对数据整体的了解,分析各个类型变量相互之间的关系,以及用合适的图形可视化出来直观观察。
- 读取大数据文件时,使用chunksize参数 ,可以有效的解决内存消耗过多的问题。
- 了解到了对缺失值的处理,可以使用可视化的方法,展示数据,方便之后对缺失值的处理。在自学的过程中了解到了实用的missingno库。
- 在数值特征分析中,需要对连续型数值和分类型数值进行区分,然后对其分别进行相应的数据处理。连续型特征数据需要观察其是否是正态分布,如果不是,需要对其进行log化处理,防止数据过偏态,对预测结果产生影响。
- 了解到了日期数据的处理方式.
- 了解与学习了透视表的使用。
- 从文章中了解到了pandas_profiling库,使用pandas_profiling生成数据报告,可以很方便地生成数据EDA报告。下图是我使用pandas_profiling库对本次赛题数据生成的数据报告。
当然在学习的过程中,也发现了不足之处,例如对matplotlib和seaborn库的可视化绘图操作掌握不是很熟练,还需继续学习。
参考链接
[1] pandas性能提升之利用chunksize参数对大数据分块处理
[2] missingno官方文档
[3] 一文看懂pandas的透视表pivot_table
[4] pandas_profiling :教你一行代码生成数据分析报告