Java应用调优实战-性能优化方法论
衡量指标有哪些?
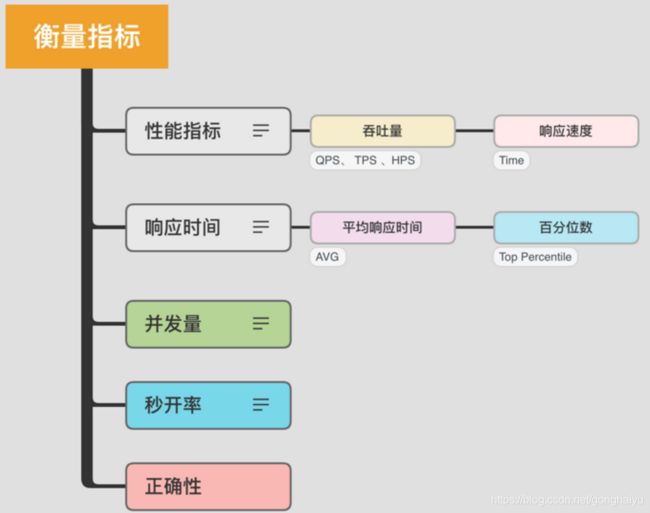
1. 吞吐量和响应速度
分布式的高并发应用并不能把单次请求作为判断依据,它往往是一个统计结果。其中最常用的衡量指标就是吞吐量和响应速度,而这两者也是考虑性能时非常重要的概念。
像我们平常开发中经常提到的,QPS 代表每秒查询的数量,TPS 代表每秒事务的数量,HPS 代表每秒的 HTTP 请求数量等,这都是常用的与吞吐量相关的量化指标。
在性能优化的时候,我们要搞清楚优化的目标,到底是吞吐量还是响应速度。 有些时候,虽然响应速度比较慢,但整个吞吐量却非常高,比如一些数据库的批量操作、一些缓冲区的合并等。虽然信息的延迟增加了,但如果我们的目标就是吞吐量,那么这显然也可以算是比较大的性能提升。
一般情况下,我们认为:
- 响应速度是串行执行的优化,通过优化执行步骤解决问题;
- 吞吐量是并行执行的优化,通过合理利用计算资源达到目标。
我们平常的优化主要侧重于响应速度,因为一旦响应速度提升了,那么整个吞吐量自然也会跟着提升。
但对于高并发的互联网应用来说,响应速度和吞吐量两者都需要。这些应用都会标榜为高吞吐、高并发的场景,用户对系统的延迟忍耐度很差,我们需要使用有限的硬件资源,从中找到一个平衡点。
2. 响应时间衡量
既然响应时间这么重要,我们就着重看一下响应时间的衡量方法。
(1)平均响应时间
我们最常用的指标,即平均响应时间(AVG),该指标能够体现服务接口的平均处理能力。它的本质是把所有的请求耗时加起来,然后除以请求的次数。举个最简单的例子,有 10 个请求,其中有 2 个 1ms、3 个 5ms、5 个 10ms,那么它的平均耗时就是(21+35+5*10)/10=6.7ms。
除非服务在一段时间内出现了严重的问题,否则平均响应时间都会比较平缓。因为高并发应用请求量都特别大,所以长尾请求的影响会被很快平均,导致很多用户的请求变慢,但这不能体现在平均耗时指标中。
为了解决这个问题,另外一个比较常用的指标,就是百分位数(Percentile)。
(2)百分位数

这个也比较好理解。我们圈定一个时间范围,把每次请求的耗时加入一个列表中,然后按照从小到大的顺序将这些时间进行排序。这样,我们取出特定百分位的耗时,这个数字就是 TP 值。可以看到,TP 值(Top Percentile)和中位数、平均数等是类似的,都是一个统计学里的术语。
它的意义是,超过 N% 的请求都在 X 时间内返回。比如 TP90 = 50ms,意思是超过 90th 的请求,都在 50ms 内返回。
这个指标也是非常重要的,它能够反映出应用接口的整体响应情况。比如,某段时间若发生了长时间的 GC,那它的某个时间段之上的指标就会产生严重的抖动,但一些低百分位的数值却很少有变化。
我们一般分为 TP50、TP90、TP95、TP99、TP99.9 等多个段,对高百分位的值要求越高,对系统响应能力的稳定性要求越高。
在这些高稳定性系统中,目标就是要干掉严重影响系统的长尾请求。这部分接口性能数据的收集,我们会采用更加详细的日志记录方式,而不仅仅靠指标。比如,我们将某个接口,耗时超过 1s 的入参及执行步骤,详细地输出在日志系统中。
3. 并发量
并发量是指系统同时能处理的请求数量,这个指标反映了系统的负载能力。
在高并发应用中,仅仅高吞吐是不够的,它还必须同时能为多个用户提供服务。并发高时,会导致很严重的共享资源争用问题,我们需要减少资源冲突,以及长时间占用资源的行为。
针对响应时间进行设计,一般来说是万能的。因为响应时间减少,同一时间能够处理的请求必然会增加。值得注意的是,即使是一个秒杀系统,经过层层过滤处理,最终到达某个节点的并发数,大概也就五六十左右。我们在平常的设计中,除非并发量特别低,否则都不需要太过度关注这个指标。
4. 秒开率
在移动互联网时代,尤其对于 App 中的页面,秒开是一种极佳的用户体验。如果能在 1 秒内加载完成页面,那用户可以获得流畅的体验,并且不会产生更多的焦虑感。
通常而言,可以根据业务情况设定不同的页面打开标准,比如低于 1 秒内的数据占比是秒开率。业界优秀的公司,比如手淘,其页面的秒开率基本可达到 80% 以上。
5. 正确性
说一个比较有意思的事情。我们有个技术团队,在进行测试的时候,发现接口响应非常流畅,把并发数增加到 20 以后,应用接口响应依旧非常迅速。
但等应用真正上线时,却发生了重大事故,这是因为接口返回的都是无法使用的数据。
其问题原因也比较好定位,就是项目中使用了熔断。在压测的时候,接口直接超出服务能力,触发熔断了,但是压测并没有对接口响应的正确性做判断,造成了非常低级的错误。
所以在进行性能评估的时候,不要忘记正确性这一关键要素。
有哪些理论方法?
木桶理论
一只木桶若想要装最多的水,则需要每块木板都一样长而且没有破损才行。如果有一块木板不满足条件,那么这只桶就无法装最多的水。
能够装多少水,取决于最短的那块木板,而不是最长的那一块。
木桶效应在解释系统性能上,也非常适合。组成系统的组件,在速度上是良莠不齐的。系统的整体性能,就取决于系统中最慢的组件。
比如,在数据库应用中,制约性能最严重的是落盘的 I/O 问题,也就是说,硬盘是这个场景下的短板,我们首要的任务就是补齐这个短板。
基准测试、预热
基准测试(Benchmark)并不是简单的性能测试,是用来测试某个程序的最佳性能。
应用接口往往在刚启动后都有短暂的超时。在测试之前,我们需要对应用进行预热,消除 JIT 编译器等因素的影响。而在 Java 里就有一个组件,即 JMH,就可以消除这些差异。
注意点

- 依据数字而不是猜想
有些同学对编程有很好的感觉,能够靠猜测列出系统的瓶颈点,这种情况固然存在,但却非常不可取。复杂的系统往往有多个影响因素,我们应将性能分析放在第一位,把性能优化放在次要位置,直觉只是我们的辅助,但不能作为下结论的工具。
进行性能优化时,我们一般会把分析后的结果排一个优先级(根据难度和影响程度),从大处着手,首先击破影响最大的点,然后将其他影响因素逐一击破。
有些优化会引入新的性能问题,有时候这些新问题会引起更严重的性能下降,你需要评估这个连锁反应,确保这种优化确实需要,同时需要使用数字去衡量这个过程,而不是靠感觉猜想。
- 个体数据不足信
你是否有这样的经历:某个知名网站的访问速度真慢,光加载就花费了 x 秒。其实,仅凭一个人的一次请求,就下了“慢”这个结论,是不合适的,而在我们进行性能评估的时候,也往往会陷入这样的误区。
这是因为个体请求的小批量数据,可参考价值并不是非常大。响应时间可能因用户的数据而异,也可能取决于设备和网络条件。
合理的做法,是从统计数据中找到一些规律,比如上面所提到的平均响应时间、TP 值等,甚至是响应时间分布的直方图,这些都能够帮我们评估性能质量。
- 不要过早优化和过度优化
虽然性能优化有这么多好处,但并不代表我们要把每个地方都做到极致,性能优化也是要有限度的。程序要运行地正确,要比程序运行得更快还要困难。
计算机科学的鼻祖"Donald Knuth" 曾说:“过早的优化是万恶之源”,就是这个道理。
如果一项改进并不能产生明显的价值,那我们为什么还要花大力气耗在上面呢?比如,某个应用已经满足了用户的吞吐量需求和响应需求,但有的同学热衷于 JVM 的调优,依然花很大力气在参数测试上,这种优化就属于过度优化。
时间要花在刀刃上,我们需要找到最迫切需要解决的性能点,然后将其击破。比如,一个系统主要是慢在了数据库查询上,结果你却花了很大的精力去优化 Java 编码规范,这就是偏离目标的典型情况。
一般地,性能优化后的代码,由于太过于追求执行速度,读起来都比较晦涩,在结构上也会有很多让步。很显然,过早优化会让这种难以维护的特性过早介入到你的项目中,等代码重构的时候,就会花更大的力气去解决它。
正确的做法是,项目开发和性能优化,应该作为两个独立的步骤进行,要做性能优化,要等到整个项目的架构和功能大体进入稳定状态时再进行。
- 保持良好的编码习惯
我们上面提到,不要过早地优化和过度优化,但并不代表大家在编码时就不考虑这些问题。
比如,保持好的编码规范,就可以非常方便地进行代码重构;使用合适的设计模式,合理的划分模块,就可以针对性能问题和结构问题进行聚焦、优化。
在追求高性能、高质量编码的过程中,一些好的习惯都会积累下来,形成人生道路上优秀的修养和品质,这对我们是大有裨益的。
性能优化的切入点
性能优化的 7 类技术手段
性能优化根据优化的类别,分为业务优化和技术优化。业务优化产生的效果也是非常大的,但它属于产品和管理的范畴。同作为程序员,在平常工作中,我们面对的优化方式,主要是通过一系列的技术手段,来完成对既定的优化目标。这一系列的技术手段,我大体归纳为如图以下 7 类:

可以看到,优化方式集中在对计算资源和存储资源的规划上。优化方法中有多种用空间换时间的方式,但只照顾计算速度,而不考虑复杂性和空间问题,也是不可取的。我们要做的,就是在照顾性能的前提下,达到资源利用的最优状态。
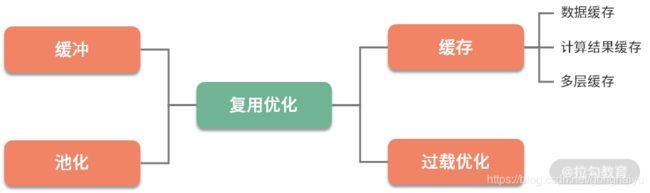
复用优化
在写代码的时候,你会发现有很多重复的代码可以提取出来,做成公共的方法。这样,在下次用的时候,就不用再费劲写一遍了。
这种思想就是复用。上面的描述是编码逻辑上的优化,对于数据存取来说,有同样的复用情况。无论是在生活中还是编码中,重复的事情一直在发生,如果没有复用,工作和生活就会比较累。
在软件系统中,谈到数据复用,我们首先想到的就是缓冲和缓存。
(1)缓冲(Buffer),常见于对数据的暂存,然后批量传输或者写入。多使用顺序方式,用来缓解不同设备之间频繁地、缓慢地随机写,缓冲主要针对的是写操作。
(2)缓存(Cache),常见于对已读取数据的复用,通过将它们缓存在相对高速的区域,缓存主要针对的是读操作。
与之类似的,是对于对象的池化操作,比如数据库连接池、线程池等,在 Java 中使用得非常频繁。由于这些对象的创建和销毁成本都比较大,我们在使用之后,也会将这部分对象暂时存储,下次用的时候,就不用再走一遍耗时的初始化操作了。
计算优化
(1)并行执行
现在的 CPU 发展速度很快,绝大多数硬件,都是多核。要想加快某个任务的执行,最快最优的解决方式,就是让它并行执行。并行执行有以下三种模式。
第一种模式是多机,采用负载均衡的方式,将流量或者大的计算拆分成多个部分,同时进行处理。比如,Hadoop 通过 MapReduce 的方式,把任务打散,多机同时进行计算。
第二种模式是采用多进程。比如 Nginx,采用 NIO 编程模型,Master 统一管理 Worker 进程,然后由 Worker 进程进行真正的请求代理,这也能很好地利用硬件的多个 CPU。
第三种模式是使用多线程,这也是 Java 程序员接触最多的。比如 Netty,采用 Reactor 编程模型,同样使用 NIO,但它是基于线程的。Boss 线程用来接收请求,然后调度给相应的 Worker 线程进行真正的业务计算。
像 Golang 这样的语言,有更加轻量级的协程(Coroutine),协程是一种比线程更加轻量级的存在,但目前在 Java 中还不太成熟,就不做过多介绍了,但本质上,它也是对于多核的应用,使得任务并行执行。
(2)变同步为异步
再一种对于计算的优化,就是变同步为异步,这通常涉及编程模型的改变。同步方式,请求会一直阻塞,直到有成功,或者失败结果的返回。虽然它的编程模型简单,但应对突发的、时间段倾斜的流量,问题就特别大,请求很容易失败。
异步操作可以方便地支持横向扩容,也可以缓解瞬时压力,使请求变得平滑。
(3)惰性加载
最后一种,就是使用一些常见的设计模式来优化业务,提高体验,比如单例模式、代理模式等。举个例子,在绘制 Swing 窗口的时候,如果要显示比较多的图片,就可以先加载一个占位符,然后通过后台线程慢慢加载所需要的资源,这就可以避免窗口的僵死。
结果集优化
接下来介绍一下对结果集的优化。举个比较直观的例子,我们都知道 XML 的表现形式是非常好的,那为什么还有 JSON 呢?除了书写要简单一些,一个重要的原因就是它的体积变小了,传输效率和解析效率变高了,像 Google 的 Protobuf,体积就更小了一些。虽然可读性降低,但在一些高并发场景下(如 RPC),能够显著提高效率,这是典型的对结果集的优化。
这是由于我们目前的 Web 服务,都是 C/S 模式。数据从服务器传输到客户端,需要分发多份,这个数据量是急剧膨胀的,每减少一小部分存储,都会有比较大的传输性能和成本提升。
像 Nginx,一般都会开启 GZIP 压缩,使得传输的内容保持紧凑。客户端只需要一小部分计算能力,就可以方便解压。由于这个操作是分散的,所以性能损失是固定的。
了解了这个道理,我们就能看到对于结果集优化的一般思路,你要尽量保持返回数据的精简。一些客户端不需要的字段,那就在代码中,或者直接在 SQL 查询中,就把它去掉。
对于一些对时效性要求不高,但对处理能力有高要求的业务。我们要吸取缓冲区的经验,尽量减少网络连接的交互,采用批量处理的方式,增加处理速度。
结果集合很可能会有二次使用,你可能会把它加入缓存中,但依然在速度上有所欠缺。这个时候,就需要对数据集合进行处理优化,采用索引或者 Bitmap 位图等方式,加快数据访问速度。
资源冲突优化
我们在平常的开发中,会涉及很多共享资源。这些共享资源,有的是单机的,比如一个 HashMap;有的是外部存储,比如一个数据库行;有的是单个资源,比如 Redis 某个 key 的Setnx;有的是多个资源的协调,比如事务、分布式事务等。
现实中的性能问题,和锁相关的问题是非常多的。大多数我们会想到数据库的行锁、表锁、Java 中的各种锁等。在更底层,比如 CPU 命令级别的锁、JVM 指令级别的锁、操作系统内部锁等,可以说无处不在。
只有并发,才能产生资源冲突。也就是在同一时刻,只能有一个处理请求能够获取到共享资源。解决资源冲突的方式,就是加锁。再比如事务,在本质上也是一种锁。
按照锁级别,锁可分为乐观锁和悲观锁,乐观锁在效率上肯定是更高一些;按照锁类型,锁又分为公平锁和非公平锁,在对任务的调度上,有一些细微的差别。
对资源的争用,会造成严重的性能问题,所以会有一些针对无锁队列之类的研究,对性能的提升也是巨大的。

算法优化
算法能够显著提高复杂业务的性能,但在实际的业务中,往往都是变种。由于存储越来越便宜,在一些 CPU 非常紧张的业务中,往往采用空间换取时间的方式,来加快处理速度。
算法属于代码调优,代码调优涉及很多编码技巧,需要使用者对所使用语言的 API 也非常熟悉。有时候,对算法、数据结构的灵活使用,也是代码优化的一个重要内容。比如,常用的降低时间复杂度的方式,就有递归、二分、排序、动态规划等。
一个优秀的实现,比一个拙劣的实现,对系统的影响是非常大的。比如,作为 List 的实现,LinkedList 和 ArrayList 在随机访问的性能上,差了好几个数量级;又比如,CopyOnWriteList 采用写时复制的方式,可以显著降低读多写少场景下的锁冲突。而什么时候使用同步,什么时候是线程安全的,也对我们的编码能力有较高的要求。
高效实现
在平时的编程中,尽量使用一些设计理念良好、性能优越的组件。比如,有了 Netty,就不用再选择比较老的 Mina 组件。而在设计系统时,从性能因素考虑,就不要选 SOAP 这样比较耗时的协议。再比如,一个好的语法分析器(比如使用 JavaCC),其效率会比正则表达式高很多。
总之,如果通过测试分析,找到了系统的瓶颈点,就要把关键的组件,使用更加高效的组件进行替换。在这种情况下,适配器模式是非常重要的。这也是为什么很多公司喜欢在现有的组件之上,再抽象一层自己的;而当在底层组件进行切换的时候,上层的应用并无感知。
JVM 优化
因为 Java 是运行在 JVM 虚拟机之上,它的诸多特性,就要受到 JVM 的制约。对 JVM 虚拟机进行优化,也能在一定程度上能够提升 JAVA 程序的性能。如果参数配置不当,甚至会造成 OOM 等比较严重的后果。
目前被广泛使用的垃圾回收器是 G1,通过很少的参数配置,内存即可高效回收。CMS 垃圾回收器已经在 Java 14 中被移除,由于它的 GC 时间不可控,有条件应该尽量避免使用。
JVM 性能调优涉及方方面面的取舍,往往是牵一发而动全身,需要全盘考虑各方面的影响。所以了解 JVM 内部的一些运行原理,还是特别重要的,它有益于我们加深对代码更深层次的理解,帮助我们书写出更高效的代码。