【Linux操作系统】--理解文件系统inode
目录
磁盘的理解
inode
Block group
Super Block和Group Descriptor Table
inode Table和Data Blocks
Block Bitmap和inode Bitmap
软连接和硬链接
软连接
硬链接
acm
acm的用处
磁盘的理解
文件=文件内容+文件属性
如果一个文件没有被打开,它的内容和属性在哪放着呢?
它们是在磁盘上放着的。磁盘是我们计算机中的一个机械设备(现在很多都是SSD,FLASH卡,USB,但是现在不考虑这些例外)。其实固态硬盘写入有固定次数,比如一万次或两万此,再写就击穿了,最后就坏掉了。
比如说有两个盘片,有四面,所以有四个磁头
盘片在寻址:我们所有的数据都在盘片上放着,都是一些硬件电路,这些硬件电路都在盘片上放好,具体在什么位置,磁头来回摆动,他在摆动的时候是在圆心和半径摆动,而盘片在不断转动,通过摆动+转动来找到磁盘上特定的位置。
磁盘中有一个扇区,一小块一小块的扇区组成了磁道,盘片是一摞的,所有的磁道加起来变成了柱面。
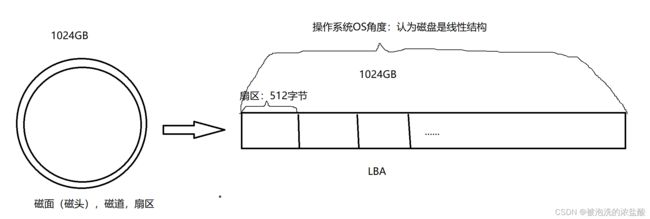
磁盘写入的基本单位是:扇区,一个扇区是512字节。如果我向找到磁盘中的某个扇区,那么我得先找到它属于的那个盘面,盘面和磁头一一对应,所以要找到对应的磁头,通过磁头找到磁道,通过磁道找到扇区。
曾经我们用的磁带,里面的带都是缠起来的,如果它展开就是线性结构。所以我们也可以将磁盘想象成一个线性结构将它展开。展开后里面的内容都是一个一个的大数组,每个数组都是一个扇区,都是512字节 。站在OS角度,认为磁盘是线性结构。
加入磁盘的大小是1024GB,展开的线性结构大小也是1024GB.。如果我们要访问上面的某一个扇区,我们就要找到扇区对应的数组下标,我们称这个下标为LBA,LBA就是特定磁盘的地址,他是一个抽象出来的地址。
inode
那么这么大的磁盘,它的管理成本非常高。
一个国家的管理需要分很多的省,同样一个大磁盘的管理需要划分很多的空间,分区就是把大磁盘变成小空间。分区要写入文件系统。就好比一个省内有很多领导来管理,如果这个领导班子没有把这个省管理好,那么就要换掉,这个就是格式化,所以格式化就是写入文件系统。
所以要使用磁盘1.分区;2。格式化:写入文件系统。
我们已经把大空间分成小空间,这样空间就在我们可控范围内,我们把大磁盘分成四个小空间,也就是四个分区。用一个小空间为例,理想情况下只要管理好一块区域,那么其它区域直接复制文件系统就可以管理好,因为在计算机看来这些区域都是一样的,就相当于这四个空间的领导班子是一样的。所以只要把小空间管理好,那么大空间就可以管理好。
Block group
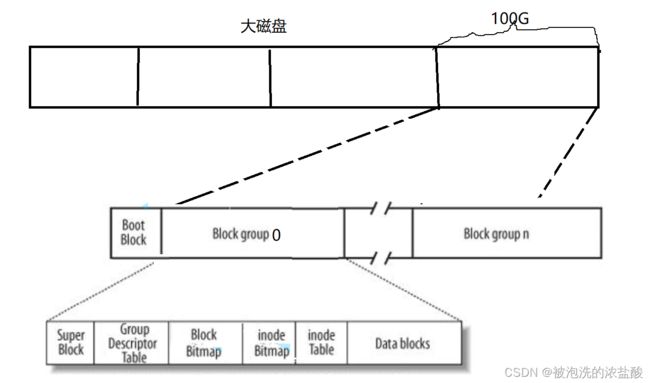
比如100GB空间等价于上面这个结构,其中它的结构中有Boot Block,它是与启动相关的。每个分区都有Boot Block且可能不止一个,如果每个分区都有这个Boot Block就相当于做了一个备份。而实际上100GB也很大,所以除了Boot Block,还分了许多其他的区域,分成了很多Block group0,1,2...n。所以我们可以把剩下的空间拆分成9-10个空间,此时只要把一个Block group0管理好,那么其它就可以管理好。
Super Block和Group Descriptor Table
Super Block代表的是整个Block group0空间的使用情况,包括文件系统相关的。它记录了整个分区中block group块的使用情况以及其它一些信息,那么一个block group块的super Block中包含了整个组的信息,那么每个Block group是否有必要都存在一个block group组来存放同样的信息呢?其实每个Block group组都有一个super block,为了以防磁盘被刮坏了,某一个组的super Block丢失了,这样其他组的super block就是一个备份。
而Group Descriptor Table描述的是组相关信息,比如说当前这块空间是Block Group0,那么我怎么知道这块空间是Block Group0呢,还包括了组的标识符,组有多大,组的起始位置和结束位置等等这样的概念。
inode Table和Data Blocks
磁盘中文件=文件属性+文件数据。那么inode Table存放的是文件的属性,Data Blocks存放的就是文件的数据。我们可以把Data Blocks想象成一个大空间,它的空间包含很多数据块,每个数据块都是一个block,每个数据块都有自己的编号;inode Table想象成一个表,里面也有数据块,它包含的是文件属性,每个小块都是一个inode。
inode
当我们创建一个file.txt文件,我们找到一个空inode将file.txt文件属性填进去,当我们往file.txt中写入一个hello world数据,我们再找到一个空block将数据填进去,此时文件就被创建好了。创建好文件后,要将inode和block关联起来,方便查找,那么现在我怎么知道inode和哪一个数据块关联 呢?
Linux中文件名在系统层面没有意义,文件名是给用户使用的。Linux中真正标识一个文件的,是通过文件的inode编号的。它都有一个为一个编号,一个文件一个inode。
在inode Table中每一个inode都会存放一个文件属性,这些属性是一个结构体,里面包含了文件的所有属性,还有数据int inode_number(inode在inode Table的位置)。然后当我们创建文件后找到对应的inode,向文件中写入内容,会给你分配一个block,它是整存整取的,一次就给你一块block。所以inode的结构体中还包括一个int blocks[]的数组,用来存储与inode关联的block的编号,一个inode可能包含很多block块,所以用数组。但是这个数组并不是固定大小,如果这个数组有32个空间,当这个空间被占满,如果还想再加入其它block数据块,可以将数组和之后的block链接起来,当然这个内部细节就比较复杂了。
当我们访问文件时,我们先根据inode编号,找到对应的文件属性结构体,然后通过结构体中block数组,找到inode和block的映射关系,然后找到对应block块,然后找到文件的内容。

Block Bitmap和inode Bitmap
当我们要找一个空inode给一个新文件建立属性关系,那么我们是要遍历整个inode Table来找一个空Inode存放新文件属性吗?这样的话查找效率会大大降低。所以这时候就出现了Block Bitmap和inode Bitmap。inode Bitmap是一个位图,那么它是一个二进制

所以当我们要找一个没有被使用的inode,只需要把inode Bitmap加载到内存,然后位操作遍历这一串位图,找到为0的位置,直接把刚刚创建的文件属性放进这块没有被使用的inode,然后把位图所对应的位置由0变1。同样我们怎样找到没有被使用的block数据块呢?我们使用block bitmap数据块位图,找到0没有被使用的位置,然后把数据放进这块空间,然后把位图置1。
以上都是linux特有的EXT系列的文件系统。
用户如何找到对应的inode
那么在用户层面,我们怎么知道一个文件对应的inode呢?目录是否也有它自己的Inode呢?
目录也有它的inode和属性,目录的inode里放什么呢,存放的是目录的大小,权限,拥有者,所属组等。
[wjy@VM-24-9-centos 30]$ mkdir tmp
[wjy@VM-24-9-centos 30]$ ll
total 4
drwxrwxr-x 2 wjy wjy 4096 Apr 30 15:42 tmp
[wjy@VM-24-9-centos 30]$ ls -di tmp/
658210 tmp/
那么目录有数据吗?目录也一定有数据块block
那么目录的数据块里面放什么呢?到目前来看,我们所创建的所有文件,都在一个特定的目录下。所以目录的数据块里存放的是目录下的文件名和文件所对应的inode编号,存放的是文件和inode的映射关系。
现在来看下面这段操作在干什么。

首先touch 一个文件,要在inode Bitmap位图中找0,在inode table中到一个没有被使用的inode属性块。将hello.c文件的属性写进这个inode块中。第二部echo要向Data Block块中写入hello world数据,那么先在Block bitmap数据位图中找到0,然后把数据写入空的block块中,然后将block块的位置写入inode块与文件属性建立映射关系。这就是创建和写入。
当我们在创建文件后,它会建立一个文件和它所对应的inode,并将这个inode和文件名写入当前文件目录下的数据块中。
那么cat是怎么找到文件内容呢?当cat hello.c,先查看hello.c文件的目录30(如图所示),然后找到该目录的data block数据块,然后从数据块中找到存放hello.c文件的inode和文件名,获取到hello.c的inode后,然后从这个inode找到对应的数组,然后从数组中找到对应的映射关系,找到最终hello.c的block数据块,从中读取数据,将数据打印到显示器上。

rm操作,先找到当前文件的目录,然后找到目录对应的block数据块,从中获取到hello.c的inode和文件名,获取到inode后,找到inode对应的文件hello.c。删文件不需要删inode table,而是将inode bitmap的1置0,然后inode映射对应的数据块删除,直接将block bitmap位图对应的数据块由1置0,这样就达到删除目的。
如果要恢复这个文件,那么就将inode和block位图对应的位置由0置1,就可以恢复。
软连接和硬链接
软连接
创建软连接的方法:ln -s [文件名] [新建软连接名]
[wjy@VM-24-9-centos 30]$ ll
total 4
-rw-rw-r-- 1 wjy wjy 0 Apr 30 16:25 log.txt
drwxrwxr-x 2 wjy wjy 4096 Apr 30 15:42 tmp
[wjy@VM-24-9-centos 30]$ ln -s log.txt log_s
[wjy@VM-24-9-centos 30]$ ll
total 4
lrwxrwxrwx 1 wjy wjy 7 Apr 30 16:26 log_s -> log.txt
-rw-rw-r-- 1 wjy wjy 0 Apr 30 16:25 log.txt
drwxrwxr-x 2 wjy wjy 4096 Apr 30 15:42 tmp
那么软连接在什么情况下应用呢?
我们创建一个目录:
[wjy@VM-24-9-centos 30]$ mkdir -p bin/sbin/hello/test
[wjy@VM-24-9-centos 30]$ ll
total 8
drwxrwxr-x 3 wjy wjy 4096 Apr 30 16:29 bin
lrwxrwxrwx 1 wjy wjy 7 Apr 30 16:26 log_s -> log.txt
-rw-rw-r-- 1 wjy wjy 0 Apr 30 16:25 log.txt
drwxrwxr-x 2 wjy wjy 4096 Apr 30 15:42 tmp
[wjy@VM-24-9-centos 30]$ tree bin/
bin/
`-- sbin
`-- hello
`-- test
3 directories, 0 files进入最底层目录并写一个脚本:
[wjy@VM-24-9-centos 30]$ cd bin/sbin/hello/test/
[wjy@VM-24-9-centos test]$ touch test.sh
[wjy@VM-24-9-centos test]$ chmod +x test.sh
[wjy@VM-24-9-centos test]$ vim test.sh
[wjy@VM-24-9-centos test]$ ./test.sh
0
1
2
3
4
5
6
7
8
9
10
[wjy@VM-24-9-centos test]$ cat test.sh
#!/bin/bash
count=0
while [ $count -le 10 ]
do
echo $count
let count++
done写完之后载回到原来的目录,此时如果我们想要执行刚才的test.sh脚本,我们需要先进入到test.sh文件的目录再执行./bin/sbin/hello/test/test.sh,这样太麻烦了,所以我们可以创建一个软连接,然后就可以直接运行了。这时候我们直接可以用myexe找到可执行程序。

所以软连接特别向我们在window下的快捷方式。
硬链接
硬链接的写入方式其实就是把软连接的选项去掉
创建软链接的方法:ln [文件名] [新建软连接名]

那么软硬链接有什么区别呢?
当我们用i选项查看各个文件的inode,发现软链的原本的文件log.txt有一个inode是...211,新建名字文件log_s又是另一个inode是...212。而硬链接原来文件和新文件都是同一个inode,redir.c和hard都是同一个inode...219。

所以软连接是有自己的独立的inode!软链接是一个独立的文件!它的文件有自己inode有自己的属性,也有自己的数据块。只不过它的数据块里保存的是指向文件的所在路径+路径名。
所以硬链接本质上根本就不是一个独立的文件,而是一个文件名和inode编号的映射关系,因为自己没有独立的inode。
创建硬链接本质是在特定的目录下填写一对文件名和inode的映射关系。它就像一个重命名。
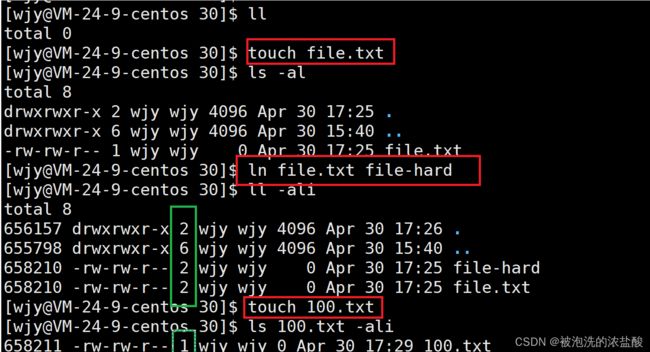
当我们在空文件创建一个硬链接,并创建一个空文件100.txt。
绿色部分就是我们硬链接数量。当只有一个文件的时候,如100.txt,它的硬链接数是1,就代表100.txt文件对应的inode658211链接的文件只有一个是100.txt。那么当创建硬链接,因为file-hard是file.txt文件的硬链接,二者的inode是一样的,所以有两个inode和文件建立映射关系,在同一个inode658210下链接的文件数量是2,这个就是引用计数。而2这个数字保存在inode的数据块block当中。
硬链接有什么用呢?
当我们创建一个目录dir,发下目录本身的硬链接数量就是2,dir目录本身和inode658210建立映射关系。当我们进入dir目录里面,里面有两个文件,一个是当前文件'.',一个是上一级文件"..",观察发现当前目录的inode值也是658210,和刚才的dir目录本身是一样的,这两个构成了两个硬链接。这个就是典型的硬链接的应用。

当在dir里面再创建一个目录tmp,dir目录的硬链接数量变成3,dir链接了658210;进入到dir文件里面,当前文件连接了658210;进入到新创建的tmp目录下,发现“..”上级目录也链接了658210。因为tmp目录的上一级是dir文件,这三个文件都是dir文件,都指向一个inode吧,并且它们的硬链接数量都是3。

acm
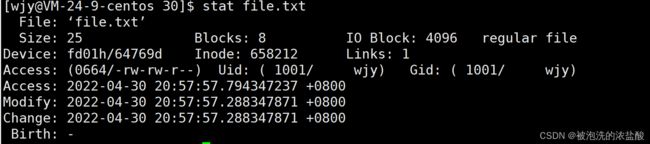
当一个文件被创建出来,有access,modify,change三个属性。我们简称为acm
- access:文件最近被读取的时间
- modify:最近一次修改文件内容的时间
- change:对文件属性的改写时间

当向file.txt文件写入内容后,再观察acm,发现都改变了。我们只修改了一个文件内容,为什么文件属性也改变了呢?这是因为当修改文件内容的同时,也会修改文件的属性,可能会更改文件的大小和属性。

但是cat查看file.txt内容后,再查看状态,又没有改变。其实再较新的Linux内核中,Access时间不会被立即更新,而是会有一定的时间间隔,OS才会自动更新。频繁更新时间可能会导致Linux大量刷盘的问题,这样Linux的系统会变得很慢。操作系统自动更新时间,也是为了防止和磁盘有过度的交互而导致的系统效率降低,这是一个优化。
修改文件属性Modify时间改变。
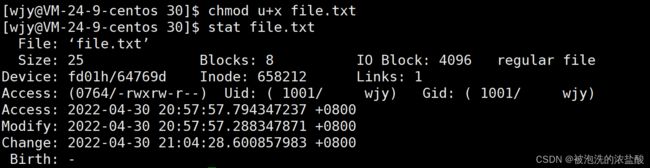
acm的用处
我们写一个test.c可执行文件,和它的makefile文件
[wjy@VM-24-9-centos 30]$ cat test.c
#include
int main()
{
printf("hello world\n");
printf("hello world\n");
return 0;
}
[wjy@VM-24-9-centos 30]$ cat makefile
mytest:test.c
gcc -o $@ $^
.PHONY:clean
clean:
rm -f mytest 分别查看test.c和mytest的状态,mytest是test.c的编译文件,在make编译之后生成。我们发现mytest的生成时间是35秒,而test.c的改变时间是29秒,当我们再次make的时候,它不能更新mytest了。这是因为当make要生成新的mytest编译文件时,看test.c的更新时间,如果test.c的改变时间是在上一次mytest文件之后,说明test.c更新了,mytest也要更新,所以make编译会成功。当test.c的修改时间在mytest编译文件之前,那么说明test.c源文件已经编译过一次了,因为编译的mytest文件的最新更新时间比源文件要晚,这时makefile编译文件需要对比旧的,看到mytest文件比源文件晚,不会更新。所以第二次make会说make: `mytest' is up to date。
当再次改变test.c文件,这时test.c文件的修改时间比mytest修改时间晚,mytest没有经过make编译还是以前的时间,test.c是最新时间。这时候再次make就编译成功。
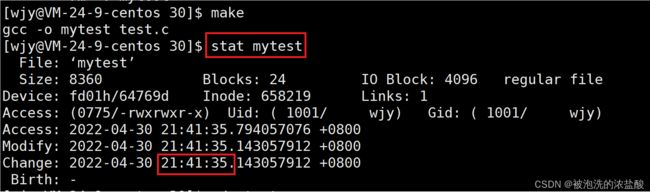
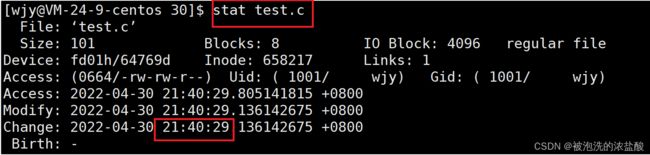
如果想要再一次更新mytest文件,我们可以用touch命令,touch叫做更新文件指令。即便test.c没有做任何修改,它还是可以编译成功。
[wjy@VM-24-9-centos 30]$ make
make: `mytest' is up to date.
[wjy@VM-24-9-centos 30]$ touch test.c
[wjy@VM-24-9-centos 30]$ make
gcc -o mytest test.c
总结:makefile与gcc会根据时间问题,来判定源文件和可执行程序谁更新,从而指导系统哪些源文件需要被重新编译。