『pyspark』〇:spark的安装、配置和使用
1、PySpark安装配置
操作系统:Ubuntu 18.04, 64位
所需软件:Java 8 +, Python 3.6.5, Scala 2.13.1, spark 2.4.8
安装步骤:
1.1 安装Java 8
sudo apt-get update
sudo apt-get install openjdk-8-jdk # 如果apt-get无法安装,看这里https://blog.csdn.net/weixx3/article/details/94109337
java -version
1.2 安装Scala
wget https://downloads.lightbend.com/scala/2.13.8/scala-2.13.8.tgz
sudo tar xvf scala-2.13.8.tgz
mv scala-2.13.8 scala
配置:
vim /etc/profile
# 文件中加入这两行
SCALA_HOME=/home/zh/scala # 改为自己的scala安装路径,通过pwd查看scala所在路径
PATH=$SCALA_HOME/bin:$PATH
# 让配置文件生效,激活环境变量
source /etc/profile
1.3 安装 py4j
Py4J在驱动程序上用于Python和Java SparkContext对象之间的本地通信,大型数据传输是通过不同的机制执行的。
pip install py4j
1.4 安装 Spark
wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.8/spark-2.4.8-bin-hadoop2.7.tgz
tar xvf spark-2.4.8-bin-hadoop2.7.tgz
mv spark-2.4.8-bin-hadoop2.7.tgz spark
如发生wget ERROR 404: Not Found.错误,我们需要手动在浏览器中打开网址,看看能不能访问,如果不能访问,我们可以退回到该下载地址的上一层或者上二层目录,这样说不定就可以访问了(由于版本更新,老版本路径失效)。当确定可以访问后,我们就可以直接用wget下载了。
配置:
vim /etc/profile
# 文件中加入这两行
SPARK_HOME=/home/zh/spark # 改为自己的spark安装路径,通过pwd查看spark所在路径
PATH=$SPARK_HOME/bin:$PATH
source /etc/profile
安装过程中没有截图,如果每个步骤都没有报错,应该就不会有问题,如有报错,可以根据报错信息查找解决方法,一般都是些小问题,肯定都能找到。
1.5 启动pyspark
命令行运行pyspark,输出界面如下:
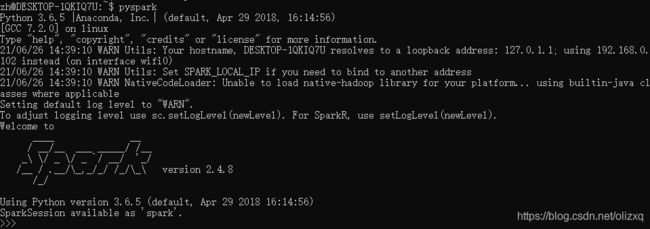
验证Spark是否正常运行:
cd ./spark
./bin/run-example SparkPi 10
运行之后,输出结果太多,我们还需要配置下环境,降低log4j.properties中log4j记录器的详细级别
cp conf/log4j.properties.template conf/log4j.properties
vim conf/log4j.properties
打开文件 ‘log4j.properties’ 后,作如下修改:
log4j.rootCategory=INFO, console
替换为
log4j.rootCategory=ERROR, console
再次运行
./bin/run-example SparkPi 10
可以查看到输出结果:

2、使用PySpark
2.1 命令行
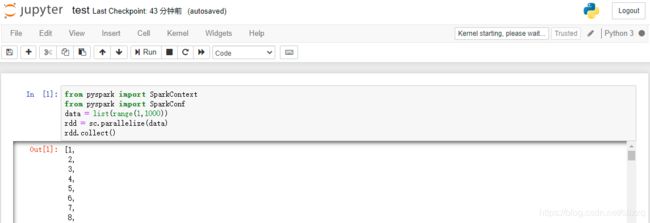
进入spark环境,直接使用:
from pyspark import SparkContext
from pyspark import SparkConf
data = list(range(1,1000))
rdd = sc.parallelize(data)
rdd.collect()
在命令行中写pyspark有点麻烦,我们是不是也能像python一样在jupyter中写pyspark,当然可以。
2.2 jupyter
在jupyter中使用pyspark有两种方式:
(1)修改环境变量
更新PySpark驱动程序环境变量:将下面两行添加到~/.bashrc文件中
配置如下:
vim /etc/profile
# 文件中加入这两行
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS='notebook'
source /etc/profile
重新启动终端,再次进入PySpark:

将网址复制到浏览器中即可使用jupyter:
(2)使用findSpark
在Jupyter Notebook中使用PySpark还有另一种更通用的方法:使用findSpark包在代码中提供Spark Context。
findSpark包不是特定于Jupyter Notebook,你也可以在你喜欢的IDE中使用这个技巧。使用前要先安装findspark:
pip install findspark
然后就可以使用jupyter notebook。
(3)pycharm使用pyspark
PyCharm 安装配置 Pyspark环境