基于EasyExcel实现百万级数据导入导出
基于EasyExcel实现百万级数据导入导出
在项目开发中往往需要使用到数据的导入和导出,导入就是从Excel中导入到DB中,而导出就是从DB中查询数据然后使用POI写到Excel上。
大数据的导入和导出,相信大家在日常的开发、面试中都会遇到。
很多问题只要这一次解决了,总给复盘记录,后期遇到同样的问题就好解决了。好啦,废话不多说开始正文!
1.传统POI的的版本优缺点比较
其实想到数据的导入导出,理所当然的会想到apache的poi技术,以及Excel的版本问题。
- HSSFWorkbook
这个实现类是我们早期使用最多的对象,它可以操作Excel2003以前(包含2003)的所有Excel版本。在2003以前Excel的版本后缀还是.xls
- XSSFWorkbook
这个实现类现在在很多公司都可以发现还在使用,它是操作的Excel2003–Excel2007之间的版本,Excel的扩展名是.xlsx
- SXSSFWorkbook
这个实现类是POI3.8之后的版本才有的,它可以操作Excel2007以后的所有版本Excel,扩展名是.xlsx
HSSFWorkbook
它是POI版本中最常用的方式,不过:
- 它的缺点是 最多只能导出 65535行,也就是导出的数据函数超过这个数据就会报错;
- 它的优点是 不会报内存溢出。(因为数据量还不到7w所以内存一般都够用,首先你得明确知道这种方式是将数据先读取到内存中,然后再操作)
XSSFWorkbook
- 优点:这种形式的出现是为了突破
HSSFWorkbook的65535行局限,是为了针对Excel2007版本的1048576行,16384列,最多可以导出104w条数据; - 缺点:伴随的问题来了,虽然导出数据行数增加了好多倍,但是随之而来的内存溢出问题也成了噩梦。因为你所创建的book,Sheet,row,cell等在写入到Excel之前,都是存放在内存中的(这还没有算Excel的一些样式格式等等),可想而知,内存不溢出就有点不科学了!!!
SXSSFWorkbook
从POI 3.8版本开始,提供了一种基于XSSF的低内存占用的SXSSF方式:
优点:
- 这种方式不会一般不会出现内存溢出(它使用了硬盘来换取内存空间,
- 也就是当内存中数据达到一定程度这些数据会被持久化到硬盘中存储起来,而内存中存的都是最新的数据),
- 并且支持大型Excel文件的创建(存储百万条数据绰绰有余)。
缺点:
- 既然一部分数据持久化到了硬盘中,且不能被查看和访问那么就会导致,
- 在同一时间点我们只能访问一定数量的数据,也就是内存中存储的数据;
sheet.clone()方法将不再支持,还是因为持久化的原因;- 不再支持对公式的求值,还是因为持久化的原因,在硬盘中的数据没法读取到内存中进行计算;
- 在使用模板方式下载数据的时候,不能改动表头,还是因为持久化的问题,写到了硬盘里就不能改变了;
2.使用方式哪种看情况
经过了解也知道了这三种Workbook的优点和缺点,那么具体使用哪种方式还是需要看情况的:
我一般会根据这样几种情况做分析选择:
1、当我们经常导入导出的数据不超过7w的情况下,可以使用 HSSFWorkbook 或者 XSSFWorkbook都行;
2、当数据量查过7w并且导出的Excel中不牵扯对Excel的样式,公式,格式等操作的情况下,推荐使用SXSSFWorkbook;
3、当数据量查过7w,并且我们需要操做Excel中的表头,样式,公式等,这时候我们可以使用 XSSFWorkbook 配合进行分批查询,分批写入Excel的方式来做;
3.百万数据导入导出
想要解决问题我们首先要明白自己遇到的问题是什么?
1、 我遇到的数据量超级大,使用传统的POI方式来完成导入导出很明显会内存溢出,并且效率会非常低;
2、 数据量大直接使用select * from tableName肯定不行,一下子查出来300w条数据肯定会很慢;
3、 300w 数据导出到Excel时肯定不能都写在一个Sheet中,这样效率会非常低;估计打开都得几分钟;
4、 300w数据导出到Excel中肯定不能一行一行的导出到Excel中。频繁IO操作绝对不行;
5、 导入时300万数据存储到DB如果循环一条条插入也肯定不行;
6、导入时300w数据如果使用Mybatis的批量插入肯定不行,因为Mybatis的批量插入其实就是SQL的循环;一样很慢。
解决思路:
- 针对1 :
其实问题所在就是内存溢出,我们只要使用对上面介绍的POI方式即可,主要问题就是原生的POI解决起来相当麻烦。
经过查阅资料翻看到阿里的一款POI封装工具EasyExcel,上面问题等到解决;
- 针对2:
不能一次性查询出全部数据,我们可以分批进行查询,只不过时多查询几次的问题,况且市面上分页插件很多。此问题好解决。
- 针对3:
可以将300w条数据写到不同的Sheet中,每一个Sheet写一百万即可。
- 针对4:
不能一行一行的写入到Excel上,我们可以将分批查询的数据分批写入到Excel中。
- 针对5:
导入到DB时我们可以将Excel中读取的数据存储到集合中,到了一定数量,直接批量插入到DB中。
- 针对6:
不能使用Mybatis的批量插入,我们可以使用JDBC的批量插入,配合事务来完成批量插入到DB。即 Excel读取分批+JDBC分批插入+事务。
3.1 模拟500w数据导出
需求:使用EasyExcel完成500w数据的导出。
500w数据的导出解决思路:
- 首先在查询数据库层面,需要分批进行查询(比如每次查询20w)
- 每查询一次结束,就使用EasyExcel工具将这些数据写入一次;
- 当一个Sheet写满了100w条数据,开始将查询的数据写入到另一个Sheet中;
- 如此循环直到数据全部导出到Excel完毕。
ps:我们需要计算Sheet个数,以及循环写入次数。特别是最后一个Sheet的写入次数
因为你不知道最后一个Sheet会写入多少数据,可能是100w,也可能是25w因为我们这里的500w只是模拟数据,有可能导出的数据比500w多也可能少
ps:我们需要计算写入次数,因为我们使用的分页查询,所以需要注意写入的次数。
其实查询数据库多少次就是写入多少次
准备工作
1.基于maven搭建springboot工程,引入easyexcel依赖,这里我是用的时3.0版本
<dependency>
<groupId>com.alibabagroupId>
<artifactId>easyexcelartifactId>
<version>3.0.5version>
dependency>
2.创建海量数据的sql脚本
CREATE TABLE dept( /*部门表*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT "",
loc VARCHAR(13) NOT NULL DEFAULT ""
) ;
#创建表EMP雇员
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/
job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/
hiredate DATE NOT NULL,/*入职时间*/
sal DECIMAL(7,2) NOT NULL,/*薪水*/
comm DECIMAL(7,2) NOT NULL,/*红利*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/
) ;
#工资级别表
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
);
#测试数据
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
delimiter $$
#创建一个函数,名字 rand_string,可以随机返回我指定的个数字符串
create function rand_string(n INT)
returns varchar(255) #该函数会返回一个字符串
begin
#定义了一个变量 chars_str, 类型 varchar(100)
#默认给 chars_str 初始值 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
# concat 函数 : 连接函数mysql函数
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end $$
#这里我们又自定了一个函数,返回一个随机的部门号
create function rand_num( )
returns int(5)
begin
declare i int default 0;
set i = floor(10+rand()*500);
return i;
end $$
#创建一个存储过程, 可以添加雇员
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
#set autocommit =0 把autocommit设置成0
#autocommit = 0 含义: 不要自动提交
set autocommit = 0; #默认不提交sql语句
repeat
set i = i + 1;
#通过前面写的函数随机产生字符串和部门编号,然后加入到emp表
insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand_num());
until i = max_num
end repeat;
#commit整体提交所有sql语句,提高效率
commit;
end $$
#添加8000000数据
call insert_emp(100001,8000000)$$
#命令结束符,再重新设置为;
delimiter ;
3.实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Emp implements Serializable {
@ExcelProperty(value = "员工编号")
private Integer empno;
@ExcelProperty(value = "员工名称")
private String ename;
@ExcelProperty(value = "工作")
private String job;
@ExcelProperty(value = "主管编号")
private Integer mgr;
@ExcelProperty(value = "入职日期")
private Date hiredate;
@ExcelProperty(value = "薪资")
private BigDecimal sal;
@ExcelProperty(value = "奖金")
private BigDecimal comm;
@ExcelProperty(value = "所属部门")
private Integer deptno;
}
4.vo类
@Data
public class EmpVo {
@ExcelProperty(value = "员工编号")
private Integer empno;
@ExcelProperty(value = "员工名称")
private String ename;
@ExcelProperty(value = "工作")
private String job;
@ExcelProperty(value = "主管编号")
private Integer mgr;
@ExcelProperty(value = "入职日期")
private Date hiredate;
@ExcelProperty(value = "薪资")
private BigDecimal sal;
@ExcelProperty(value = "奖金")
private BigDecimal comm;
@ExcelProperty(value = "所属部门")
private Integer deptno;
}
导出核心代码
@Resource
private EmpService empService;
/**
* 分批次导出
*/
@GetMapping("/export")
public void export() throws IOException {
StopWatch stopWatch = new StopWatch();
stopWatch.start();
empService.export();
stopWatch.stop();
System.out.println("共计耗时: " + stopWatch.getTotalTimeSeconds()+"S");
}
public class ExcelConstants {
//一个sheet装100w数据
public static final Integer PER_SHEET_ROW_COUNT = 1000000;
//每次查询20w数据,每次写入20w数据
public static final Integer PER_WRITE_ROW_COUNT = 200000;
}
@Override
public void export() throws IOException {
OutputStream outputStream =null;
try {
//记录总数:实际中需要根据查询条件进行统计即可
//LambdaQueryWrapper lambdaQueryWrapper = new QueryWrapper().lambda().eq(Emp::getEmpno, 1000001);
Integer totalCount = empMapper.selectCount(null);
//每一个Sheet存放100w条数据
Integer sheetDataRows = ExcelConstants.PER_SHEET_ROW_COUNT;
//每次写入的数据量20w,每页查询20W
Integer writeDataRows = ExcelConstants.PER_WRITE_ROW_COUNT;
//计算需要的Sheet数量
Integer sheetNum = totalCount % sheetDataRows == 0 ? (totalCount / sheetDataRows) : (totalCount / sheetDataRows + 1);
//计算一般情况下每一个Sheet需要写入的次数(一般情况不包含最后一个sheet,因为最后一个sheet不确定会写入多少条数据)
Integer oneSheetWriteCount = sheetDataRows / writeDataRows;
//计算最后一个sheet需要写入的次数
Integer lastSheetWriteCount = totalCount % sheetDataRows == 0 ? oneSheetWriteCount : (totalCount % sheetDataRows % writeDataRows == 0 ? (totalCount / sheetDataRows / writeDataRows) : (totalCount / sheetDataRows / writeDataRows + 1));
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder.getRequestAttributes();
HttpServletResponse response = requestAttributes.getResponse();
outputStream = response.getOutputStream();
//必须放到循环外,否则会刷新流
ExcelWriter excelWriter = EasyExcel.write(outputStream).build();
//开始分批查询分次写入
for (int i = 0; i < sheetNum; i++) {
//创建Sheet
WriteSheet sheet = new WriteSheet();
sheet.setSheetName("测试Sheet1"+i);
sheet.setSheetNo(i);
//循环写入次数: j的自增条件是当不是最后一个Sheet的时候写入次数为正常的每个Sheet写入的次数,如果是最后一个就需要使用计算的次数lastSheetWriteCount
for (int j = 0; j < (i != sheetNum - 1 ? oneSheetWriteCount : lastSheetWriteCount); j++) {
//分页查询一次20w
Page<Emp> page = empMapper.selectPage(new Page(j + 1 + oneSheetWriteCount * i, writeDataRows), null);
List<Emp> empList = page.getRecords();
List<EmpVo> empVoList = new ArrayList<>();
for (Emp emp : empList) {
EmpVo empVo = new EmpVo();
BeanUtils.copyProperties(emp, empVo);
empVoList.add(empVo);
}
WriteSheet writeSheet = EasyExcel.writerSheet(i, "员工信息" + (i + 1)).head(EmpVo.class)
.registerWriteHandler(new LongestMatchColumnWidthStyleStrategy()).build();
//写数据
excelWriter.write(empVoList, writeSheet);
}
}
// 下载EXCEL
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
response.setCharacterEncoding("utf-8");
// 这里URLEncoder.encode可以防止浏览器端导出excel文件名中文乱码 当然和easyexcel没有关系
String fileName = URLEncoder.encode("员工信息", "UTF-8").replaceAll("\\+", "%20");
response.setHeader("Content-disposition", "attachment;filename*=utf-8''" + fileName + ".xlsx");
excelWriter.finish();
outputStream.flush();
} catch (IOException e) {
e.printStackTrace();
} catch (BeansException e) {
e.printStackTrace();
}finally {
if (outputStream != null) {
outputStream.close();
}
}
}
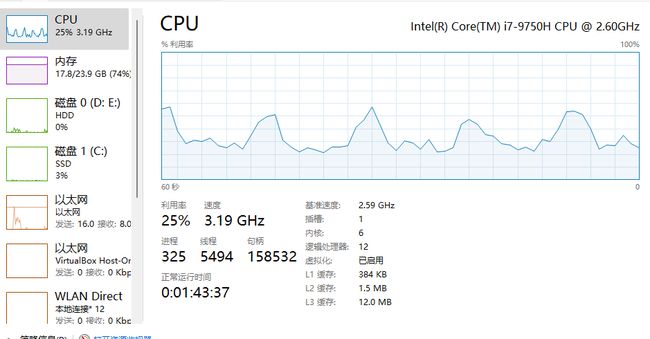
这是我电脑测试时内存占用和CPU使用情况,当然开了其他一些应用。
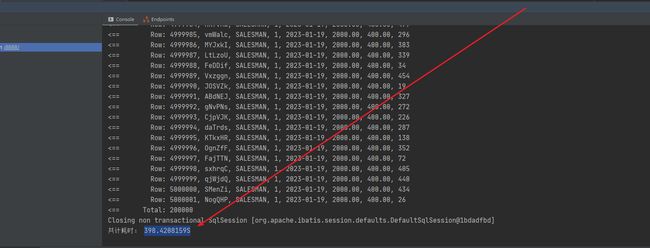
导出500w数据共计耗时,可以看到差不多400s左右,当然还要考虑业务复杂度已经电脑配置,我这里只是一个导出的demo并不涉及其他业务逻辑,在实际开发中可能时间会比这个更长一些
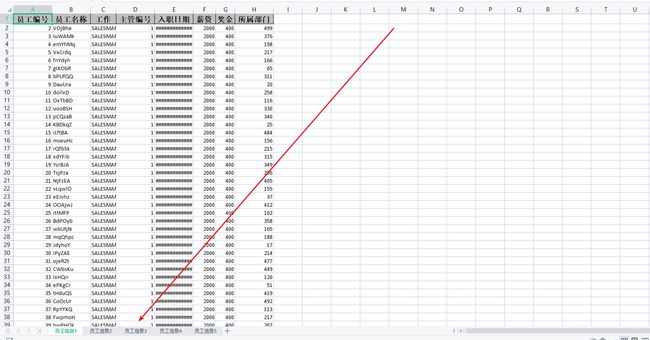
看下导出效果,我上面的脚本向插入了500w数据,100w一个sheet因此正好五个

3.2模拟500w数据导入
500W数据的导入解决思路
1、首先是分批读取读取Excel中的500w数据,这一点EasyExcel有自己的解决方案,我们可以参考Demo即可,只需要把它分批的参数5000调大即可。
2、其次就是往DB里插入,怎么去插入这20w条数据,当然不能一条一条的循环,应该批量插入这20w条数据,同样也不能使用Mybatis的批量插入语,因为效率也低。
3、使用JDBC+事务的批量操作将数据插入到数据库。(分批读取+JDBC分批插入+手动事务控制)
代码实现
controller层测试接口
@Resource
private EmpService empService;
@GetMapping("/importData")
public void importData() {
String fileName = "C:\\Users\\asus\\Desktop\\员工信息.xlsx";
//记录开始读取Excel时间,也是导入程序开始时间
long startReadTime = System.currentTimeMillis();
System.out.println("------开始读取Excel的Sheet时间(包括导入数据过程):" + startReadTime + "ms------");
//读取所有Sheet的数据.每次读完一个Sheet就会调用这个方法
EasyExcel.read(fileName, new EasyExceGeneralDatalListener(empService)).doReadAll();
long endReadTime = System.currentTimeMillis();
System.out.println("------结束读取Excel的Sheet时间(包括导入数据过程):" + endReadTime + "ms------");
System.out.println("------读取Excel的Sheet时间(包括导入数据)共计耗时:" + (endReadTime-startReadTime) + "ms------");
}
Excel导入事件监听
// 事件监听
public class EasyExceGeneralDatalListener extends AnalysisEventListener<Map<Integer, String>> {
/**
* 处理业务逻辑的Service,也可以是Mapper
*/
private EmpService empService;
/**
* 用于存储读取的数据
*/
private List<Map<Integer, String>> dataList = new ArrayList<Map<Integer, String>>();
public EasyExceGeneralDatalListener() {
}
public EasyExceGeneralDatalListener(EmpService empService) {
this.empService = empService;
}
@Override
public void invoke(Map<Integer, String> data, AnalysisContext context) {
//数据add进入集合
dataList.add(data);
//size是否为100000条:这里其实就是分批.当数据等于10w的时候执行一次插入
if (dataList.size() >= ExcelConstants.GENERAL_ONCE_SAVE_TO_DB_ROWS) {
//存入数据库:数据小于1w条使用Mybatis的批量插入即可;
saveData();
//清理集合便于GC回收
dataList.clear();
}
}
/**
* 保存数据到DB
*
* @param
* @MethodName: saveData
* @return: void
*/
private void saveData() {
empService.importData(dataList);
dataList.clear();
}
/**
* Excel中所有数据解析完毕会调用此方法
*
* @param: context
* @MethodName: doAfterAllAnalysed
* @return: void
*/
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
saveData();
dataList.clear();
}
}
核心业务代码
public interface EmpService {
void export() throws IOException;
void importData(List<Map<Integer, String>> dataList);
}
/*
* 测试用Excel导入超过10w条数据,经过测试发现,使用Mybatis的批量插入速度非常慢,所以这里可以使用 数据分批+JDBC分批插入+事务来继续插入速度会非常快
*/
@Override
public void importData(List<Map<Integer, String>> dataList) {
//结果集中数据为0时,结束方法.进行下一次调用
if (dataList.size() == 0) {
return;
}
//JDBC分批插入+事务操作完成对20w数据的插入
Connection conn = null;
PreparedStatement ps = null;
try {
long startTime = System.currentTimeMillis();
System.out.println(dataList.size() + "条,开始导入到数据库时间:" + startTime + "ms");
conn = JDBCDruidUtils.getConnection();
//控制事务:默认不提交
conn.setAutoCommit(false);
String sql = "insert into emp (`empno`, `ename`, `job`, `mgr`, `hiredate`, `sal`, `comm`, `deptno`) values";
sql += "(?,?,?,?,?,?,?,?)";
ps = conn.prepareStatement(sql);
//循环结果集:这里循环不支持lambda表达式
for (int i = 0; i < dataList.size(); i++) {
Map<Integer, String> item = dataList.get(i);
ps.setString(1, item.get(0));
ps.setString(2, item.get(1));
ps.setString(3, item.get(2));
ps.setString(4, item.get(3));
ps.setString(5, item.get(4));
ps.setString(6, item.get(5));
ps.setString(7, item.get(6));
ps.setString(8, item.get(7));
//将一组参数添加到此 PreparedStatement 对象的批处理命令中。
ps.addBatch();
}
//执行批处理
ps.executeBatch();
//手动提交事务
conn.commit();
long endTime = System.currentTimeMillis();
System.out.println(dataList.size() + "条,结束导入到数据库时间:" + endTime + "ms");
System.out.println(dataList.size() + "条,导入用时:" + (endTime - startTime) + "ms");
} catch (Exception e) {
e.printStackTrace();
} finally {
//关连接
JDBCDruidUtils.close(conn, ps);
}
}
}
jdbc工具类
//JDBC工具类
public class JDBCDruidUtils {
private static DataSource dataSource;
/*
创建数据Properties集合对象加载加载配置文件
*/
static {
Properties pro = new Properties();
//加载数据库连接池对象
try {
//获取数据库连接池对象
pro.load(JDBCDruidUtils.class.getClassLoader().getResourceAsStream("druid.properties"));
dataSource = DruidDataSourceFactory.createDataSource(pro);
} catch (Exception e) {
e.printStackTrace();
}
}
/*
获取连接
*/
public static Connection getConnection() throws SQLException {
return dataSource.getConnection();
}
/**
* 关闭conn,和 statement独对象资源
*
* @param connection
* @param statement
* @MethodName: close
* @return: void
*/
public static void close(Connection connection, Statement statement) {
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 关闭 conn , statement 和resultset三个对象资源
*
* @param connection
* @param statement
* @param resultSet
* @MethodName: close
* @return: void
*/
public static void close(Connection connection, Statement statement, ResultSet resultSet) {
close(connection, statement);
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/*
获取连接池对象
*/
public static DataSource getDataSource() {
return dataSource;
}
}
druid.properties配置文件
这里我将文件创建在类路径下,需要注意的是连接mysql数据库时需要指定rewriteBatchedStatements=true批处理才会生效,否则还是逐条插入效率较低,allowMultiQueries=true表示可以使sql语句中有多个insert或者update语句(语句之间携带分号),这里可以忽略。
# druid.properties配置
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/llp?autoReconnect=true&useUnicode=true&useSSL=false&serverTimezone=GMT%2B8&allowMultiQueries=true&rewriteBatchedStatements=true
username=root
password=root
initialSize=10
maxActive=50
maxWait=60000
测试结果
------开始读取Excel的Sheet时间(包括导入数据过程):1674181403555ms------
200000条,开始导入到数据库时间:1674181409740ms
2023-01-20 10:23:29.943 INFO 18580 --- [nio-8888-exec-1] com.alibaba.druid.pool.DruidDataSource : {dataSource-1} inited
200000条,结束导入到数据库时间:1674181413252ms
200000条,导入用时:3512ms
200000条,开始导入到数据库时间:1674181418422ms
200000条,结束导入到数据库时间:1674181420999ms
200000条,导入用时:2577ms
.....
200000条,开始导入到数据库时间:1674181607405ms
200000条,结束导入到数据库时间:1674181610154ms
200000条,导入用时:2749ms
------结束读取Excel的Sheet时间(包括导入数据过程):1674181610155ms------
------读取Excel的Sheet时间(包括导入数据)共计耗时:206600ms------
这里我删除里部分日志,从打印结果可以看出,在我的电脑上导入500w数据差不多需要20多秒的时间,还是很快的。当然公司的业务逻辑很复杂,数据量也比较多,表的字段也比较多,导入和导出的速度会比现在测试的要慢一点。
4.总结
1.如此大批量数据的导出和导入操作,会占用大量的内存实际开发中还应限制操作人数。
2.在做大批量的数据导入时,可以使用jdbc手动开启事务,批量提交。