基于自适应降噪的深度神经网络对抗图像检测【论文阅读】
近年来,许多研究表明,深度神经网络(DNN)分类器可能会被对抗性示例所欺骗,这种对抗性示例是通过对原始样本引入一些扰动来设计的。据此,提出了一些强大的防御技术。然而,现有的防御技术往往需要修改目标模型或依赖于攻击的先验知识。在本文中,我们提出了一种直接的方法来检测对抗图像的例子,它可以直接部署到现成的DNN模型未经修改。我们把对图像的扰动看作是一种噪声,并引入标量量化和平滑空间滤波两种经典的图像处理技术来降低其影响。采用图像熵作为度量,对不同类型的图像进行自适应降噪。因此,通过比较给定样本的分类结果和去噪后的版本,可以有效地检测出对抗样本,而无需参考任何攻击的先验知识。 针对一些最先进的DNN模型,使用了超过20,000个对抗实例来评估所提出的方法,这些方法由不同的攻击技术设计而成。实验表明,我们的检测方法可以获得96.39%的F1总分,这无疑提高了defense-aware攻击的门槛。
引入
在dnn中,提出了一些防御技术。其中大多数都需要修改目标模型。例如,对抗训练是一种简单的防御技术,它在训练过程中使用尽可能多的对抗例子作为一种正则化。 Papernot et al.[16]介绍了一种防御技术——防御蒸馏。其中,第一个网络生成概率向量来标记原始数据集,另一个网络使用新标记的数据集进行训练。 因此,对抗性例子的效力可以大大降低。最近的一些研究,[17],[18],[19],[20]关注于直接发现对抗样本。类似地,这些技术也需要修改模型或获取足够的对抗样本,如训练新的子模型[17],使用已知的对抗样本[18]重新训练修改后的模型作为检测器,对大量的对抗和良性样本[19]进行统计检验,或使用大量的对抗实例及其对应的良性实例[20]训练关键检测参数。
不幸的是,重新培训现有模型或更改其架构将引入昂贵的培训成本。为训练或统计测试提供适当的对抗样本也需要很高的费用,而且依赖于对各种潜在的对抗技术的非常全面的先验知识。 更糟糕的是,攻击者可以用防御者所不知道的技术来设计对抗样本。在这种情况下,对抗例子有很好的机会避开分类器。此外,用一种新兴的攻击技术训练分类器需要一些时间。攻击者总有机会制造出有效的对抗例子。此外,大多数现有的防御技术是特定于模型的。为了将防御技术应用于不同的模型,它们需要单独重建或重新训练。对一个模型的安全性增强不能直接应用于其他模型。 为了解决上述挑战,我们在本文中提出了一种新的技术,能够有效地捕获adversarial examlpes,即使在缺乏潜在攻击的先验知识。
我们的方法是基于这样的观察:为了使对抗性变化不被察觉,对抗性例子所引起的扰动通常需要被限制在一个小范围内。这是很重要的,否则,这个例子将很容易被人识别。 因此,扰动所引入的信息也应该小于原始图像的信息。在该方法中,我们将扰动视为一种人工噪声,并利用降噪技术来减少其对抗性影响。如果对降噪效果进行适当的降噪,降噪后的对抗性实例将被分类为一个不同于adversarial target的新类。另一方面,对于合法的样本,同样的去噪操作很可能只会稍微改变图像的语义,使其保持在原来的类别内。 直观地说,所有的对抗扰动都是后来添加到图像上的,因此比原始图像信息更不容易接受降噪过程。在去噪后的良性样本中保留的信息仍然足以让分类器正确地识别其类别。事实上,一些研究[21],[22]已经表明,目前最先进的分类器对于一定程度的失真具有一定的鲁棒性。为此,通过检测去噪后样本的分类是否发生改变,可以有效地检测出对抗样本。
两种经典的图像处理技术,标量量化和平滑空间滤波,是用来减少扰动的影响。然而,对所有样本进行同样的去噪实际上是不合适的。 一个简单的图像,例如,一个灰度手写数字,可能只包含数百个像素。换句话说,当对这类图像生成对抗例子时,扰动空间是有限的。对手必须放大扰动以产生有效的对抗实例[10]。另一方面,彩色照片往往能提供较大的扰动空间。添加一个小尺度扰动可能会导致误分类。如图1所示,利用[10]中的攻击方法,在极小扰动下处理彩色图像可以生成有效的对抗例子。然而,使用同样的强度扰动不能生成手写数字的对抗例子,如图2所示。只有将扰动放大至少50倍,才能得到一个有效的对抗例子。


因此,适合于高分辨率样本的量化或平滑可能对低分辨率的还不够。使用均匀降噪策略可能会使一些样本去噪过度或去噪不足,并引入假阳性和假阴性。显然,对于不同的图像,我们应该采用不同的去噪策略。
为了提高我们的方法对不同类型的图像的通用性,我们进行了自适应的降噪。利用图像的熵来度量样本的复杂度。对于可能受到对手严重干扰的低熵样本,采用主动降噪策略。对于高熵样本,a light strategy is employed。具体来说,如图3所示,我们方法的关键组成部分是检测滤波器 T T T。当将样本 x x x输入目标分类器 C C C时,经过 T T T去噪,生成过滤后的样本 T ( x ) T(x) T(x)。
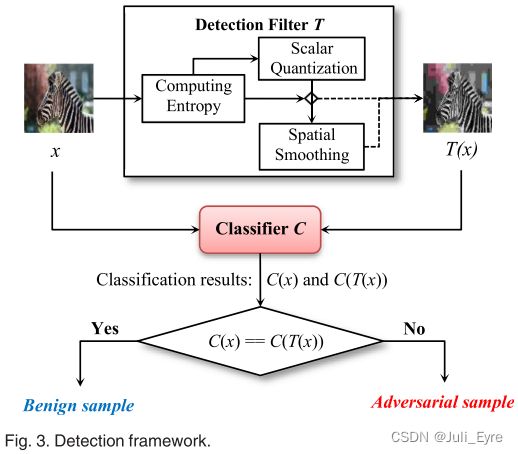
首先,通过计算样本的熵值确定适当的interval size,对样本进行量化。我们还利用熵来决定量化后的样本是否需要平滑。只有当熵值大于阈值时,才会使用空间平滑滤波器对其进行平滑处理。最后,进行两个单独的分类。一个为原始样本 x x x,另一个为去噪样本 T ( x ) T(x) T(x)。只有当这两个分类相等时,即 C ( x ) = = C ( T ( x ) ) C(x)== C(T(x)) C(x)==C(T(x)), x x x才被认为是良性的。否则,它被认为是敌对的。在实践中,检测机制不能提前知道 x x x的真正类来验证其目前的分类 C ( x ) C(x) C(x)。在我们的方法中, C ( T ( x ) ) C(T(x)) C(T(x))实际上作为检测基线来检测潜在的对抗例子。
我们使用了一些最先进的DNN模型和流行的数据集,如GoogLeNet[3]、CaffeNet[23]、MNIST[24]和ImageNet[25]来评估所提出方法的有效性。三种最新的攻击技术,即FGSM[10]、DeepFool[11]和CW攻击[26],被用来制作对抗例子。我们在两种攻击场景下评估了我们的方法,即无防御场景和有防御场景。在不了解防御的情况下,我们总共生成了21673个有效对抗的例子。实验结果表明,该方法检测对抗样本的总查全率达到95.00%,总查准率达到97.81%,F1总得分达到96.39%。与其他最近的检测方法相比,我们的方法可以检测出更多的对抗例子和更少的假阳性。在具有防御意识的场景下,实验结果表明,该检测方法能够有效提高攻击者的攻击成功率,攻击成功率显著降低到67.37%。正如[28]中所演示的,许多最近的检测方法都被具有防御意识的攻击打败了。相比之下,该方法被证明是一种很有前景的防御感知攻击的缓解方法。总之,我们的主要贡献如下。
- 我们将DNN对抗例子的扰动建模为图像噪声,并引入经典的图像处理技术来降低其影响。这使我们可以有效地检测对抗的例子,而无需事先了解攻击技术。
- 我们利用熵值去自动调整特定样本的检测策略。这使得该方法能够在不需要调整参数的情况下检测不同类型的对抗实例,并可以直接集成到未修改的目标模型中。
- 利用一些最新的DNN模型,我们证明了所提出的方法可以有效地检测不同攻击技术产生的对抗实例,并且比目前的其他检测方法有更好的性能,特别是在防御感知攻击场景中
背景
Attack Scenarios
在实践中,敌手可能对目标模型有不同程度的了解。因此,他们在发动攻击时可能采用不同的方法。与在[20],[28],[29]中所做的一样,我们在两种不同的攻击场景下评估我们的检测方法,即defense-unaware and defense-aware。
Defense-unaware Scenario:有些用户可以在任务[31],[32]中直接使用这样的公共模型。例如,Esteva et al.[31]利用一个预先训练的Inception v3模型,并在一些临床图像上重新训练它来分类皮肤癌。原始模型和再训练样本都是公开的。换句话说,对手也可以直接获得目标模型,或者构建一个相同的模型并彻底分析它。然而,如图3所示,所提出的技术可以很容易地部署在一个未改变的训练模型上。该技术的关键部分是滤波器 T T T,它可以直接与原始模型 C C C集成,而不需要对其进行任何修改。事实上,用户可以在一个公开的模型中偷偷地引入我们的检测技术。在这种情况下,对手可以完全理解C,但不知道T的存在(即不了解防御)。
Defense-aware Scenario: 在某些极端情况下,敌方可以通过各种方法得到包括综合检测机制在内的整个目标模型。因此,他们可以充分分析C和T,以生成所需的对抗例子,并发起更复杂的攻击。
Crafting Adversarial Example
一般来说,对于给定的样本x和训练过的模型C,攻击者的目标是通过在x上添加一个扰动Dx来构造一个对抗例子x = x + Dx,这样 C ( x ∗ ) ! = C ( x ) C(x^{*}) !=C(x) C(x∗)!=C(x)。
在大多数情况下,攻击者希望目标模型对结果图像进行错误分类,而人类观察者仍然可以在不注意引入扰动的情况下对图像进行正确分类。在实践中,对抗例子可以直接生成,也可以通过优化过程生成。在本文中,我们选择了以下三种最新的攻击技术来进行检测实验。它们能产生难以察觉的扰动。
- FGSM
- DeepFool moosavi - dez等人[11]设计了DeepFool算法,以找到足以改变分类结果的非常小的扰动。对原始图像x0进行迭代处理。在算法的每次迭代中,计算到达决策边界的xi的扰动向量,并更新当前的估计。算法停止,直到xi的预测类发生变化。DeepFool被实现为一个优化过程,它可以产生最小扰动的一个很好的近似。moosavi - dezfool等人对GoogLeNet[3]、CaffeNet[23]等几种DNN图像分类器进行了攻击实验。他们的实验表明,DeepFool可以导致比FGSM更小的扰动,但仍然有效地欺骗目标模型
- CW攻击。Carlini和Wagner[26]也使用了一种优化算法来寻求尽可能小的扰动。针对L0、L2和L1距离度量设计了三种强大的攻击。他们使用一些公共数据集,如MNIST[24]和ImageNet[25],训练一些深度网络模型来评估他们的攻击方法。如[26]所示,CW攻击可以找到比其他攻击技术更接近对抗的例子,而且永远不会找不到对抗的例子。例如,CW L0和L2攻击可以找到对抗的例子,失真至少比FGSM低2倍。此外,Carlini和Wagner也证明了他们的攻击可以有效地打破防守蒸馏[16]。
METHODOLOGY
Overview
我们的方法背后的基本思想是,将扰动视为一种噪声,并引入图像处理技术,以尽可能减少其对抗性影响。
如第2节所述,通过在原始图像上叠加一些扰动来设计对抗示例。从这个意义上说,在对抗例子中引入的扰动是一个加性噪声项 h ( m , n ) h(m, n) h(m,n),原始图片 f ( m , n ) f(m,n) f(m,n)
g ( m , n ) = f ( m , n ) + h ( m , n ) g(m,n)=f(m,n)+h(m,n) g(m,n)=f(m,n)+h(m,n)
其中m、n为空间坐标。
例如,FGSM对抗信号的扰动可以看作是振幅为 ϵ \epsilon ϵ的加性噪声。理想情况下,如果我们能从对抗例子g(m, n)中重建出原始图像f(m, n),那么对抗例子就能立即被检测出来。然而,由于缺乏关于噪声项h(m, n)的必要知识,实现这一点是非常困难的,甚至是不可能的。相反,我们寻求从分类的意义上重建原始图像。也就是说,我们想要将g(m, n)转换成一个新的图像f ’ (m, n),使它的预测类C(f ’ (m, n))可以与C(f(m, n))相同。
当然,我们希望模型转换后能够正确识别出良性样本。如果是这样,则可以通过检查样本的分类是否改变来检测对抗例子。如果分类被改变,样本将被识别为一个潜在的对抗样本。否则,它被认为是良性的。 值得庆幸的是,目前最先进的DNN图像分类器具有一定的鲁棒性,能够容忍一定程度的失真[21]、[22],但在面对对抗实例时表现较弱。如图5所示,原始图像被GoogLeNet以99.97%的置信度分类为Zebra。经过灰度化、调整大小、压缩或模糊处理后,仍然能够以较高的可信度正确分类。

正如在第1节中提到的,利用降噪技术来减少扰动的影响。尽管样本中一些感兴趣的细节被删除,但分类器可以对去噪后的图像输出正确的分类。请注意,虽然在本研究中扰动被视为一种噪声,但我们不能imply扰动遵循一定的分布。如[11]所示,扰动在不同的攻击之间可能有很大的不同。此外,在现实生活中,我们不太可能知道对手使用了什么技术,干扰可能具有什么特征。
事实上,所引入的扰动可以是随机的,并且它们的分布没有可预测的,如图4所示。因此,我们采用两种不需要先验知识的直接技术,即标量量化和平滑空间滤波,而不是基于先验知识的技术(如Lee滤波[34])来检测对抗例子。
对于标量量化,interval size是一个关键参数。原则上,使用较大的interval可以更有效地减少干扰的影响,但同时会引入更多的畸变,图像的“业务”受到更严重的破坏。这可能导致量化良性样本的错误分类,并产生假阳性。相反,更小的间隔可能会带来更多的假阴性,因为噪声降低不充分。
我们利用图像熵来确定参数。图像熵的概念描述了图像具有多少随机性(或不确定性),图像的熵值是对图像所传输信息的定量度量。通常,图像的熵越大,其语义(“业务”)就越丰富。因此,对于熵越大的图像,分类器需要更多的信息来识别其类别。根据直觉,为了避免过度消除样本的信息,在对高熵样本进行量化时,会对其应用一个小的区间大小,低熵样本将被分配一个大的区间大小。 平滑一个样本会模糊它的细节,常常会减少它的信息。然而,对于一个非常简单的图像(具有低熵),例如一个手写数字,平滑可能会过度消除其细节,而这些细节对分类任务很重要。即从分类的角度来看,低熵图像不能很好地容忍模糊。为此,我们使用熵来决定是否需要对样本进行平滑处理。
Evaluation Targets and Metrics

Computing Entropy
初步实验表明,输入图像本身也是决定有效检测方案的一个参数。换句话说,在检测低分辨率对抗图像时行之有效的方案可能无法检测高分辨率图像。在这项工作中,我们利用离散熵来区分不同分辨率的图像。离散熵[39]是一个强大的度量,已经被证明在图像处理[40],[41],[42]中很有用。不失一般性,对于一个M×N 256像素级的灰度图像,其熵可计算为式(7),像素级i的频率记为 f i f_i fi。

Scalar Quantization
量化是用一个较小的(有限的)值表示一个大的(可能是无限的)值集的过程,例如,将实数映射为整数。在图像处理中,量化通常被用作一种有损压缩技术by mapping a range of pixel intensities to a single representing one。换句话说,减少图像的颜色数量以减少其文件大小。
标量量化是一种最实用、最直接的图像量化方法。在标量量化中,所有输入within a specified interval都映射到一个公共值(称为码字),而不同时间间隔内的输入将映射到不同的码字。标量量化有两种类型:均匀量化和非均匀量化[43]。均匀量化时,将输入分割成相同大小的区间,而非均匀量化时,通常采用优化算法选择不同大小的区间,以减小失真。对100个具有FGSM攻击的MNIST数字进行了小规模的实证研究,以确定哪种量化方式能更有效地降低扰动的影响。我们采用[44]中的算法进行非均匀量化。对于均匀和非均匀量化,区间数都设置为2。如表3所示,均匀量化在检测方面可以获得更高的F1分数,花费的时间也更少。因此,在本研究中,我们采用均匀量化技术来处理样本。

为了形成统一的量化,我们还需要确定区间的数目。我们试图使用训练集的样本来发现一个合适的区间数。不幸的是,实验结果如表4所示
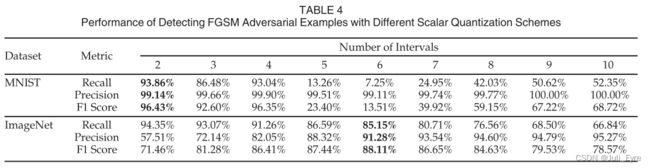
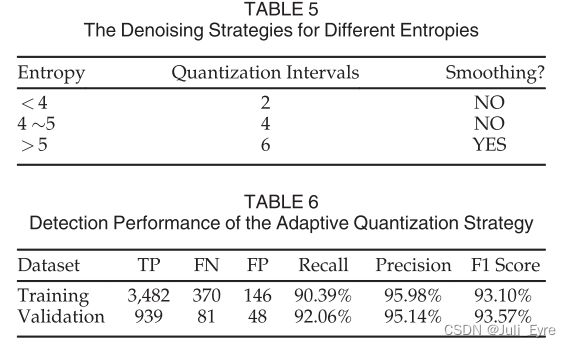
我们可以看到,对于不同的样本,没有一般的区间设置。 在两个间隔设置下,检测MNIST对抗实例的F1得分最高,为96.43%。然而,在ImageNet的例子中,使用6次间隔的最佳得分为88.11%。为了解决这个问题,我们利用第3.3节中描述的图像熵为给定的样本自动应用一个自适应的区间大小。 我们对训练集进行了一系列的实验,寻求一些熵阈值,用于设置区间大小。最后,如表5所示,我们找到了一个可行的解决方案。对于不同熵值(小于4.0,介于4.0和5.0之间,大于5.0)的样本,区间数分别设置为2、4和6。如表6所示,交叉验证实验也表明,自适应标量量化策略在训练集和验证集上都能取得满意的检测性能。
然而,实验也表明,对于高熵值(大于5.0)的样本,检测性能仍有提高的空间。高熵样本的F1得分为85.80%,而其他样本的F1得分为95.68%。标量量化在本质上是一种点运算。随后,通过引入邻域运算技术,进一步减小了对高熵样本的扰动。如表5所示,我们也使用熵来决定是否应该进行平滑。
Spatial Smoothing Filter
空间平滑滤波器是最经典的降噪技术之一。它背后的思想是根据像素的局部邻域来修改图像中像素的值。因此,像素强度的急剧变化(通常由噪声带来的)在目标图像中被减少。在线性平滑滤波中,滤波后的图像 f ′ ( m , n ) f ' (m, n) f′(m,n)是原始图像 f ( m , n ) f(m, n) f(m,n)与滤波掩模 w ( m , n ) w(m, n) w(m,n)的卷积,如下所示。
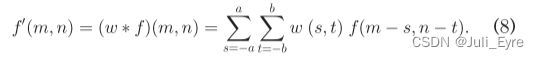
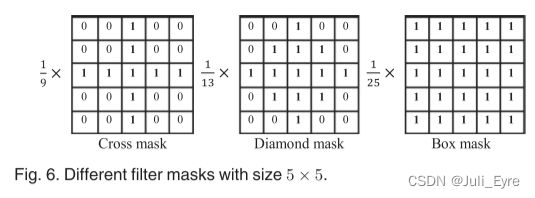
滤波掩模决定平滑效果。图6为三种常见的5 × 5平均filter masks。With a mask,像素的强度被替换为像素强度的标准平均值,which are weighted by 1 in its neighborhood。滤波后的目标图像会变得模糊,并去除图像中的小细节。然而,从图像分类的角度来看,感兴趣的对象可能会被突出显示,容易检测。
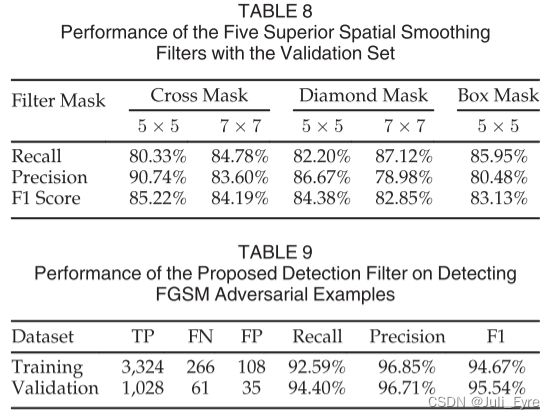
为了确定一个可行的滤波器,我们对2015个高熵训练样本进行了一系列不同形状和大小的实验。从表7的结果可以得出,mask有5个可接受的候选项,即5x5 cross、7x7 cross、5x5 diamond、7x7 diamond、5x5 box。交叉验证实验(见表8)也表明,这五种掩码对我们的验证集是有效的。在下一节中,我们将介绍基于标量量化和空间平滑的完整检测滤波器。
Detection Filter
在实际应用中,平滑处理可能会导致一些样本过度模糊,产生新的误报。为此,我们基于上述两种技术设计了一个组合过滤器,而不是简单地将它们连接在一起。
正如第2节所讨论的,攻击者通常希望对抗例子中引入的扰动尽可能小,以使其不易被察觉。换句话说,对像素强度的扰动通常被限制在一个小范围内。如果一个像素的强度被平滑滤波器过分模糊,平滑可能是不必要的。 基于上述直观,我们对高熵样本的检测滤波器定义如下:
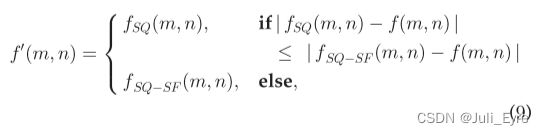
其中 f S Q ( m , n ) f_{SQ}(m, n) fSQ(m,n)为量化后的原始图像, f S Q − S F ( m , n ) f_{SQ-SF}(m, n) fSQ−SF(m,n)为平滑后的量化图像。对于输入样本 f ( m , n ) f(m, n) f(m,n)的给定像素 ( a , b ) (a, b) (a,b),当量化后的像素值 f S Q ( a , b ) f_{SQ}(a, b) fSQ(a,b)与原始像素值 f ( a , b ) f (a, b) f(a,b)之间的距离小于 f S Q − S F ( a , b ) f_{SQ-SF}(a, b) fSQ−SF(a,b)与f(a, b)之间的距离时,将输出像素值 f ′ ( a , b ) f ' (a, b) f′(a,b)替换为其量化后的像素值 f S Q ( a , b ) f_{SQ}(a, b) fSQ(a,b);否则,将被设置为 f S Q − S F ( a , b ) f_{SQ-SF}(a, b) fSQ−SF(a,b)。
我们的检测方法的完整框架现在已经准备好了。首先,利用图像熵自动调整每个样本的检测参数。对于低熵值(小于4.0)和中熵值(4.0 ~ 5.0)的样本,我们分别只对其进行二区间和四区间均匀量化;对于高熵(大于5.0)的样本,我们首先用六区间量化对其进行量化,然后对其量化后的版本进行平滑,如式(9)所示。为了从五个候选的平滑滤波器中确定最终的平滑滤波器,我们进行了一系列的实验,发现将7x7 cross mask与标量量化进行积分时是最好的平滑滤波器。如表9所示,最终的检测滤波器在训练集和验证集上都能取得满意的检测性能。
注意,本文方法对目标模型是透明的。在实践中,检测滤波器可以直接集成到任何现成的模型作为样本预处理器。目标模型可以保持不变。
总结
在不感知防御的实验中,我们总共使用了43,346个样本来评估我们的方法,其中一半是敌对的,一半是良性的。在检测三种攻击技术产生的对抗性样本时,我们获得了95.00%的总召回率和97.81%的总准确率,从而获得了96.39%的整体F1得分。请注意,我们的检测方法不可避免地会导致一些误报。对于21673个良性样本,我们的方法导致461个样本(2.13%)被误分类,这在安全关键场景中是可以接受的性能下降。此外,该滤波器可恢复94.16%的对抗实例分类。在实践中,有效地检测防御感知攻击是非常困难的,正如之前的研究所证明的那样。现有的检测方法都被具有防御意识的连续波攻击破坏了。正如第4.2节所示,我们的方法无疑提高了对手的难度,并且很有希望缓解具有防御意识的攻击。此外,我们的方法可以直接部署到目标模型,而无需修改或重新训练它,甚至无需任何攻击技术的先验知识。事实上,我们只使用FGSM算法来确定检测滤波器,但是所选择的滤波器可以有效地击败另外两种更强的攻击,即DeepFool和CW。
DISCUSSION AND LIMITATIONS
假阳性和假阴性。 原则上,我们的检测方法的性能与目标分类器的分类能力密切相关。一些误报和误报are caused by the ambiguous images,这对于目标分类器来说本质上是很难进行分类的。如图7所示,一幅由各种水果组成的图像被标记为菠萝,但GoogLeNet能够识别出这一点,其置信度只有19.55%。这真的不是一个强有力的预测。该样品也被认为是柠檬(10.85%)和菠萝蜜(9.43%)。经过我们的滤波器去噪后,图像被错误地分类为柠檬,并导致错误的阳性结果。然而,我们认为无论是模型还是提出的检测滤波器都不是造成假阳性的原因,而是图像中的模糊性。这些令人困惑的图像不仅会导致假阳性,也会导致假阴性。以FGSM生成的对抗例子为例,如图8所示的图像Pineapple to Sea Anemone被扰动,但只有19.76%的置信度。GoogLeNet对此给出了一个微弱的预测。我们的检测方法也未能检测到这个不利的例子并产生假阴性。
在我们的实验集中,像这两个例子一样有相当多的模糊图像,这降低了正确率和召回率。对于模糊的样本,可能有必要检查更多的预测类(例如,前5个预测),而不是只检查可信度最高的预测类。
可感知的扰动。一些攻击技术,如CW L 0 L_0 L0和 J a c o b i a n − b a s e d s a l i e n c y m a p a p p r o a c h ( J S M A ) Jacobian-based saliency map approach (JSMA) Jacobian−basedsaliencymapapproach(JSMA),可能会引入大振幅扰动。这种攻击技术限制了改变像素的数量,但没有限制像素的幅度。因此,如图9所示,所得到的对抗例子可能出现easy-to-notice的失真。它很容易被人发现。然而,当没有考虑到人的交互时,它仍然可以被利用来发动有效的攻击。在[15]中还发现了一些具有可感知扰动的对抗图像。原则上,在不损害原始图像语义的情况下,仅通过滤波技术来适当降低严重扰动的影响是非常困难的。 开发一种有效的检测方法这种例子超出了本文的范围,但将是我们未来的研究。

其他图像处理技术。除了我们所采用的方法外,还有许多其他的图像处理技术。其中一些可以用来进一步改进我们的检测方法,如Renyi entropy[51],图像分割[43]等。例如,我们可以根据像素之间的连通性将一个对抗性的例子分割成一些区域,从而找到一个包含尽可能多信息的区域。当扰动被隔离在其他区域时,我们有很好的机会恢复正确的分类。这样,可以检测到图9所示的对抗样本。在未来,我们计划研究其他图像处理技术,以发展一个更复杂的检测方法,特别是检测对抗例子with large-amplitude perturbations.
conclusion
然而,通常需要攻击技术的先验知识或对目标模型的修改。提出了一种简单有效的对抗图像实例检测方法。该方法将对抗扰动视为一种噪声,并将其作为滤波器来减小其影响。利用图像熵自动调整特定样本的检测策略。我们的方法提供了两个重要特征(1)不需要攻击的先验知识(2)可以直接集成到未修改的模型中。我们分别在无防御和有防御意识的情况下评估了我们的方法。实验结果表明,该方法在检测无防御场景下不同攻击技术和针对不同模型产生的对抗实例时,获得了较高的F1分数,并能有效提高防御感知场景下的对手水平。与现有的检测方法相比,我们的方法在两种攻击场景下都有更好的性能。注意,我们的方法也与其他防御技术兼容。将它们组合在一起可以获得更好的性能。我们的研究表明,经典的图像处理技术可以有效地分析对抗图像。在未来,我们将研究更多的图像处理技术,以找到更有效和实用的检测技术,特别是防御意识攻击。