网络爬虫学习(二) selenium
目录
六 selenium
一 selenium简介
1.什么是selenium?
2.为什么使用selenium?
3.selenium使用流程:
4.selenium的使用
二 访问网址
三 定位节点
方法一:
方法二:
2.find_element()和find_elements()的区别
案例一:selenium基础用法
四 模拟浏览器操作
1)常用方法
案例二:selenium其他自动化操作
2)页面存在iframe标签时
案例三:动作链和iframe的处理
3)在实际web操作时,会有很多鼠标操作不仅仅有单击
案例四:模拟登录qq空间
五 页面等待
1)显式等待
2)隐式等待
案例五:谷歌无头浏览器+反检测.
六 Phantomjs
七 综合案例--模拟登录12306
八 存储数据至数据库
1)简介数据库
2)Mysql数据库
3)pymysql
4)相关案例
5)MongoDB数据库
2)安装pymongo
3)相关案例
实战演练--爬取中国知网文章信息
六 selenium
一 selenium简介
1.什么是selenium?
(1)Selenium是一个用于Web应用程序测试的工具。
(2)Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。 (3)支持通过各种driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动 真实浏览器完成测试。
(4)selenium也是支持无界面浏览器操作的。
2.为什么使用selenium?
模拟浏览器功能,自动执行网页中的js代码,实现动态加载
3.selenium使用流程:
- 环境安装:pip install selenium
- 下载一个浏览器的驱动程序(edge)
- 下载路径:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
- 驱动程序和浏览器的映射关系:http://blog.csdn.net/huilan_same/article/details/51896672
- 实例化一个浏览器对象
- 编写基于浏览器自动化的操作代码
- 发起请求:get(url)
- 标签定位:find系列的方法
- 标签交互:send_keys('xxx')
- 执行js程序:excute_script('jsCode')
- 前进,后退:back(),forward()
- 关闭浏览器:quit()
4.selenium的使用
1)声明浏览器对象
(1)导入:from selenium import webdriver
(2)初始化浏览器操作对象:(支持多种浏览器)
path = 谷歌浏览器驱动文件路径
browser = webdriver.Edge(path)
注意:声明浏览器对象前需要安装对应的浏览器驱动
二 访问网址
使用get()方法请求网页,传入url参数即可,会弹出浏览器窗口并自动访问,然后可以调用浏览器对象的属性和方法获取网页的信息
url = 要访问的网址
browser.get(url)
浏览器对象的属性和方法获取网页的信息:
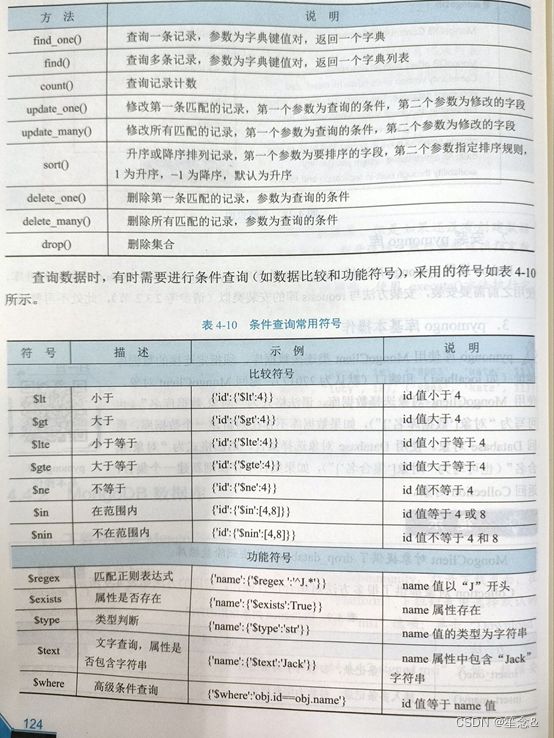
| 属性和方法 | 说明 |
| page_source | 获取当前页面的HTML源代码 |
| current_url | 获取当前页面的URL |
| title | 获取当前页面的HTML源代码中的title标签的文本信息 |
| get_cookies() | 获取所有cookie |
| get_cookie(name) | 获取指定的cookie |
| add_cookie({}) | 添加cookie,参数为字典类型 |
| delete_all_cookies() | 删除所有cookie |
| delete_cookie(name) |
删除指定的cookie |
三 定位节点
元素定位:自动化要做的就是模拟鼠标和键盘来操作来操作这些元素,点击、输入等等。操作这些元素前首先 要找到它们,WebDriver提供很多定位元素的方法
方法一:
(现在pycharm好像不能使用了,所以不详细介绍)

方法二:
通用方法
# driver.find_element(By.定位方法,‘元素信息’)
该方法需要传入查找方式喝对应的值两个参数
# 导入By模块
from selenium.webdriver.common.by import By
1.使用方法:
# driver.find_element(By.定位方法,‘元素信息’)
driver.find_element(By.ID, 'foo')
使用中的定位方法和普通的定位方法是一致的。
案例:
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.by import By
# 选择浏览器
driver = webdriver.Chrome()
# 进入百度网站
driver.get('https://www.baidu.com')
# 通过find_element定位输入框
driver.find_element(By.ID,'kw').send_keys('python')2.find_element()和find_elements()的区别
(1)find_element()的返回结果是一个WebElement对象,如果符合条件的有多个,默认返回找到的第一个,如果没有找到则抛出NoSuchElementException异常。
(2)find_elements()的返回结果是一个包含所有符合条件的WebElement对象的列表,如果未找到,则返回一个空列表
案例一:selenium基础用法
from selenium import webdriver
from lxml import etree
from time import sleep
from selenium.webdriver.edge.service import Service
#实例化一个浏览器对象(传入浏览器的驱动程序)
bro = webdriver.Edge(executable_path=r"msedgedriver.exe")
#让浏览器发起一个指定url对应请求
bro.get('https://www.jd.com/')
#page_source获取浏览器当前页面的页面源码数据
page_text = bro.page_source
#解析企业名称
tree = etree.HTML(page_text)
a_list = tree.xpath('//*[@id="J_seckill"]/div/div/div[1]/div/div/div/a')
for a in a_list:
name = a.xpath("./h6/text()")[0]
print(name)
#等待五秒后关闭
sleep(5)
#关闭浏览器
bro.quit()
四 模拟浏览器操作
1)常用方法
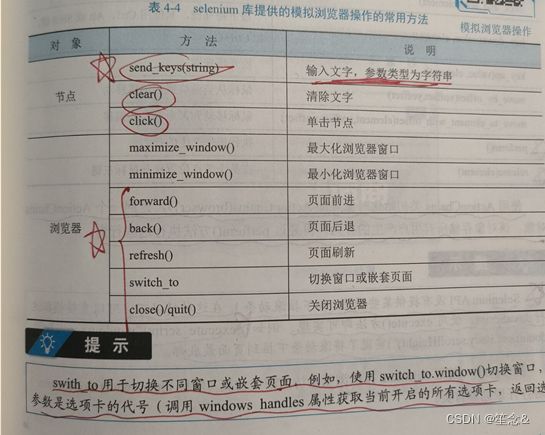
案例二:selenium其他自动化操作
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
bro = webdriver.Edge(executable_path=r"msedgedriver.exe")
bro.get('https://www.taobao.com/')
#标签定位
search_input = bro.find_element(By.ID,'q')
#标签交互
search_input.send_keys('Iphone')
#执行一组js程序
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(2)
#点击搜索按钮
btn = bro.find_element(By.CSS_SELECTOR,'.btn-search')
btn.click()
bro.get('https://www.baidu.com')
sleep(2)
#回退
bro.back()
sleep(2)
#前进
bro.forward()
sleep(5)
bro.quit()
2)页面存在iframe标签时
iframe:在一个页面中,可以嵌套一个子页面,这样的操作可以使用iframe来实现。
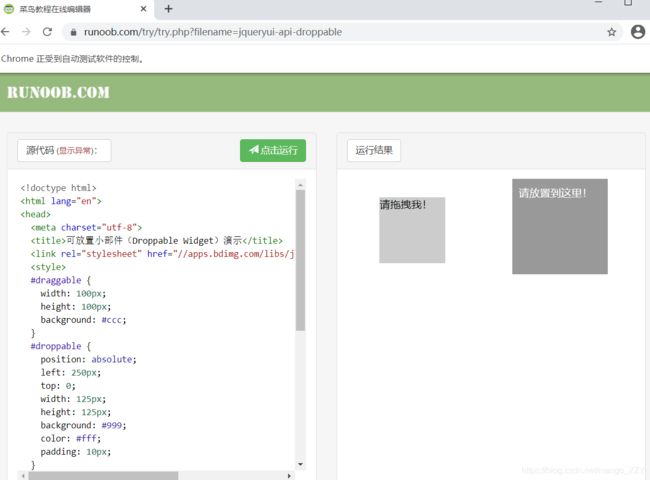
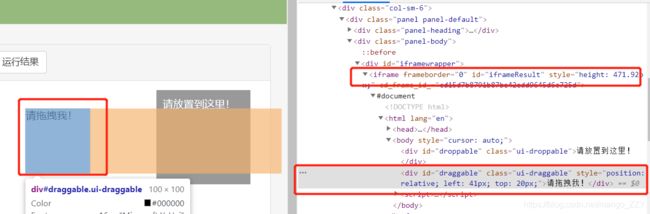
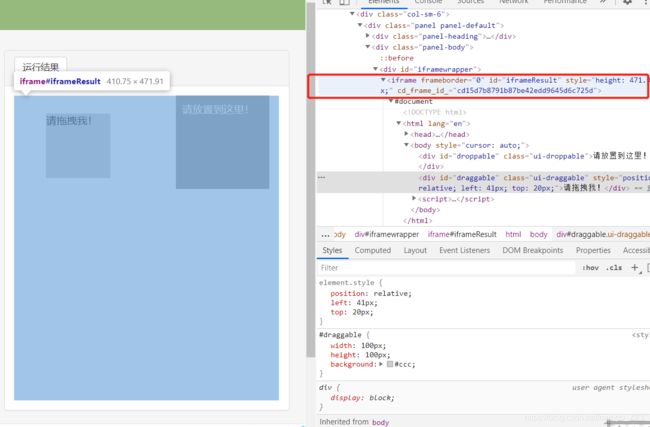
如上图所示,要挪动的方块被嵌套在当前网页的子页面中。如果定位的标签存在在iframe之中,必须用上述代码中的方法切换作用域,切换到指定的iframe中,否则会默认在全局作用域。
frame总结
- 如果定位的标签存在于iframe标签之中,则必须使用switch_to.frame(id)
- 动作链(拖动):from selenium.webdriver import ActionChains
- 实例化一个动作链对象:action = ActionChains(bro)
- click_and_hold(div):长按且点击操作
- move_by_offset(x,y)
- perform()让动作链立即执行
- action.release()释放动作链对象
- selenium处理iframe
- 如果定位的标签存在于iframe标签之中,则必须使用switch_to.frame(id)
- 动作链(拖动):from selenium.webdriver import ActionChains
- 实例化一个动作链对象:action = ActionChains(bro)
- click_and_hold(div):长按且点击操作
- move_by_offset(x,y)
- perform()让动作链立即执行
- action.release()释放动作链对象
案例三:动作链和iframe的处理
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
#导入动作链对应的类
from selenium.webdriver import ActionChains
bro = webdriver.Edge(executable_path=r"msedgedriver.exe")
bro.get('https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
#如果定位的标签是存在于iframe标签之中的则必须 通过如下操作在进行标签定位
bro.switch_to.frame('iframeResult')#切换浏览器标签定位的作用域
div = bro.find_element(By.ID,'draggable')
#动作链
action = ActionChains(bro)
#点击长按指定的标签
action.click_and_hold(div)
for i in range(5):
#perform()立即执行动作链操作
#move_by_offset(x,y):x水平方向 y竖直方向
action.move_by_offset(17,0).perform()
sleep(0.5)
#释放动作链
action.release()
bro.quit()3)在实际web操作时,会有很多鼠标操作不仅仅有单击

注意:seleniumAPI没有提供某些操作(如下拉滚动条)在这种情况下,可以直接模拟运行js,使用execute()方法即可实现
例如:execute_scrpt("window.scrollTo(0,document.body.scrollHeight)")实现;1将滚动条下拉到页面最底部。
案例四:模拟登录qq空间
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
bro = webdriver.Edge(executable_path=r"msedgedriver.exe")
bro.get('https://qzone.qq.com/')
bro.switch_to.frame('login_frame')
a_tag = bro.find_element(By.ID,"switcher_plogin")
a_tag.click()
userName_tag = bro.find_element(By.ID,'u')
password_tag = bro.find_element(By.ID,'p')
sleep(1)
userName_tag.send_keys('328410948')
sleep(1)
password_tag.send_keys('123456789')
sleep(1)
btn = bro.find_element(By.ID,'login_button')
btn.click()
sleep(3)
bro.quit()五 页面等待
很多网页采用了Ajax技术,程序无法确定某个节点是否已经完全加载。如果页面实际加载的时间过长,会导致程序使用未加载出来的节点,此时就会抛出NullPointer异常。为了避免这种情况,selenium库提供了显式等待和隐式等待两种等待方式
1)显式等待

2)隐式等待
selenium库直接使用implicitly_wait(timeout)方法实现隐式等待,该方法表示在规定的时间内页面的所有元素都加载完了就执行下一步,否则一直等到时间截止,然后再继续下一步。
相关案例:

运行结果:
聚划算
资源加载成功
清理资源
案例五:谷歌无头浏览器+反检测.
1.无头浏览就是不弹出浏览器
2.如果selenium被检测到,会被拒绝爬取,这也是一种反爬手段。因此我们需要规避selenium检测。
以上两条不需要背下来,用的时候copy就行。
目前好像有了新的规避方法,等我用到我会更新,欢迎大家和我交流!
from selenium import webdriver
from time import sleep
#实现无可视化界面
from selenium.webdriver.edge.options import Options
#实现规避检测
from selenium.webdriver import EdgeOptions
#实现无可视化界面的操作
edge_options = Options()
edge_options.add_argument('--headless')
edge_options.add_argument('--disable-gpu')
#实现规避检测
option = EdgeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
#如何实现让selenium规避被检测到的风险
bro = webdriver.Chrome(executable_path='./msedgedriver.exe',chrome_options=edge_options,options=option)
#无可视化界面(无头浏览器) phantomJs
bro.get('https://www.baidu.com')
print(bro.page_source)
sleep(2)
bro.quit()六 Phantomjs
1.什么是Phantomjs?
(1)是一个无界面的浏览器
(2)支持页面元素查找,js的执行等
(3)由于不进行css和gui渲染,运行效率要比真实的浏览器要快很多
2.如何使用Phantomjs?
(1)获取PhantomJS.exe文件路径path
(2)browser = webdriver.PhantomJS(path)
(3)browser.get(url)
扩展:保存屏幕快照:browser.save_screenshot('baidu.png')
3.Chrome handless
Chrome-headless 模式, Google 针对 Chrome 浏览器 59版 新增加的一种模式,可以让你不打开UI界面的情况下 使用 Chrome 浏览器,所以运行效果与 Chrome 保持完美一致。
1.系统要求:
Chrome Unix\Linux 系统需要 chrome >= 59 Windows 系统需要 chrome >= 60
Python3.6
Selenium==3.4.*
ChromeDriver==2.31
2.配置:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.options import Options
chrome_options = Options() chrome_options.add_argument('‐‐headless') chrome_options.add_argument('‐‐disable‐gpu') path = r'C:\Program Files (x86)\Google\Chrome\Application\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('http://www.baidu.com/')
七 综合案例--模拟登录12306
12306模拟登录
- 超级鹰:http://www.chaojiying.com/about.html
- 注册:普通用户
- 登录:普通用户
- 题分查询:充值
- 创建一个软件(id)
- 下载示例代码
- 12306模拟登录编码流程:
- 使用selenium打开登录页面
- 对当前selenium打开的这张页面进行截图
- 对当前图片局部区域(验证码图片)进行裁剪
- 好处:将验证码图片和模拟登录进行一一对应。
- 使用超级鹰识别验证码图片(坐标)
- 使用动作链根据坐标实现点击操作
- 录入用户名密码,点击登录按钮实现登录
#下述代码为超级鹰提供的示例代码
import requests
from hashlib import md5
from selenium.webdriver.common.by import By
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
# if __name__ == '__main__':
# chaojiying = Chaojiying_Client('2841083324', '1905242685.abc', '939854') #用户中心>>软件ID 生成一个替换 96001
# im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
# print( chaojiying.PostPic(im, 1902)) #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
# print chaojiying.PostPic(base64_str, 1902) #此处为传入 base64代码
#上述代码为超级鹰提供的示例代码
#使用selenium打开登录页面
from selenium import webdriver
import time
from PIL import Image
from selenium.webdriver import ActionChains
bro = webdriver.Chrome(executable_path='./msedgedriver.exe')
bro.get('https://kyfw.12306.cn/otn/login/init')
time.sleep(1)
#save_screenshot就是将当前页面进行截图且保存
bro.save_screenshot('aa.png')
#截图可能需要把浏览器*1.25
#确定验证码图片对应的左上角和右下角的坐标(裁剪的区域就确定)
code_img_ele = bro.find_element(By.XPATH,'//*[@id="loginForm"]/div/ul[2]/li[4]/div/div/div[3]/img')
location = code_img_ele.location # 验证码图片左上角的坐标 x,y
print('location:',location)
size = code_img_ele.size #验证码标签对应的长和宽
print('size:',size)
#左上角和右下角坐标
rangle = (
int(location['x']), int(location['y']), int(location['x'] + size['width']), int(location['y'] + size['height']))
#至此验证码图片区域就确定下来了
i = Image.open('./aa.png')
code_img_name = './code.png'
#crop根据指定区域进行图片裁剪
frame = i.crop(rangle)
frame.save(code_img_name)
#将验证码图片提交给超级鹰进行识别
chaojiying = Chaojiying_Client('2841083324', '1905242685.abc', '939854') #用户中心>>软件ID 生成一个替换 96001
im = open('code.png', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print( chaojiying.PostPic(im, 1902))
print(chaojiying.PostPic(im, 9004)['pic_str'])
result = chaojiying.PostPic(im, 9004)['pic_str']
all_list = [] #要存储即将被点击的点的坐标 [[x1,y1],[x2,y2]]
if '|' in result:
list_1 = result.split('|')
count_1 = len(list_1)
for i in range(count_1):
xy_list = []
x = int(list_1[i].split(',')[0])
y = int(list_1[i].split(',')[1])
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
else:
x = int(result.split(',')[0])
y = int(result.split(',')[1])
xy_list = []
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
print(all_list)
#遍历列表,使用动作链对每一个列表元素对应的x,y指定的位置进行点击操作
for l in all_list:
x = l[0]
y = l[1]
ActionChains(bro).move_to_element_with_offset(code_img_ele, x, y).click().perform()
time.sleep(0.5)
bro.find_element(By.ID,'username').send_keys('[email protected]')
time.sleep(2)
bro.find_element(By.ID,'password').send_keys('bobo_15027900535')
time.sleep(2)
bro.find_element(By.ID,'loginSub').click()
time.sleep(30)
bro.quit()
八 存储数据至数据库
1)简介数据库
MySQL是关系型数据库,他将数据保存在不同的二维表中,表中每一列是一个字段,每一行是一条记录;MongoDB是非关系型文档数据库,其数据存储形式类似JSON对象,他的字段可以包含其他文档,数组以及文档数组,形式非常灵活。
2)Mysql数据库
安装并且配置数据库
MySQL 8.0保姆级下载、安装及配置教程(我妈看了都能学会)_哔哩哔哩_bilibili
使用mysql -uroot -p输入密码12345进入
输入use mysql 命令选择数据库
输入flush privileges;命令刷新数据库
3)pymysql
pip install pymysql

常用方法及其操作

4)相关案例
#定义元组类型数据,创建mysql数据库和表,并对数据库进行插入,更新何删除和查询数据等操作,输出查询的结果
#定义元组类型数据,创建mysql数据库和表,并对数据库进行插入,更新何删除和查询数据等操作,输出查询的结果
import pymysql #导入pymysql模块
db = pymysql.connect(host='localhost', user='root', password='12345', port=3306) #连接MySQL
cursor = db.cursor() #获取操作游标
cursor.execute('CREATE DATABASE IF NOT EXISTS student_sql Character Set UTF8MB4') #创建数据库student_sql
cursor.close() #关闭游标
db.close() #断开连接
#连接MySQL,并选择student_sql数据库
db = pymysql.connect(host='localhost', user='root', password='12345', port=3306, db='student_sql')
cursor = db.cursor() #获取操作游标
sql = 'CREATE TABLE IF NOT EXISTS students (id CHAR(20), name CHAR(20), age INT)' #创建表students
cursor.execute(sql) #执行SQL语句
student = (('0001', 'bob', 12),
('0002', 'lucy', 10),
('0003', 'kate', 11)) #定义数据
try:
#SQL插入数据语句
sql='INSERT INTO students(id, name, age) VALUES(%s, %s, %s)'
cursor.executemany(sql,student) #执行多条SQL语句
db.commit() #提交到数据库执行
sql = 'SELECT * FROM students'#SQL查询数据语句,查询所有记录
cursor.execute(sql) #执行SQL语句
results = cursor.fetchall() #获取所有记录列表
print('插入数据后的所有记录:', results)#输出记录
#SQL更新数据语句
sql = 'UPDATE students SET age = %s WHERE name = %s'
cursor.execute(sql, (13, 'bob')) #执行SQL语句
db.commit() #提交到数据库执行
sql = 'SELECT * FROM students'#SQL查询数据语句,查询所有记录
cursor.execute(sql) #执行SQL语句
results = cursor.fetchall() #获取所有记录列表
print('更新数据后的所有记录:', results)#输出记录
#SQL删除数据语句,删除age小于等于10的记录
sql = 'DELETE FROM students WHERE age <= 10'
cursor.execute(sql) #执行SQL语句
db.commit() #提交到数据库执行
sql = 'SELECT * FROM students'#SQL查询数据语句,查询所有记录
cursor.execute(sql) #执行SQL语句
results = cursor.fetchall() #获取所有记录列表
#输出记录
print('删除age小于等于10的数据后的所有记录:', results)
#SQL查询数据语句,查询age大于12的记录
sql = 'SELECT * FROM students WHERE age > 12'
cursor.execute(sql) #执行SQL语句
results = cursor.fetchall() #获取所有记录列表
print('age大于12的数据的所有记录:', results) #输出记录
except:
db.rollback() #回滚当前事务
cursor.close() #关闭游标
db.close() #断开数据库连接
运行结果

注意:

5)MongoDB数据库
1)下载并且安装MongoDB
访问MongoDB Community Download | MongoDB
打开下载页面

点击download
然后根据向导进行安装
2)安装pymongo

3)相关案例
定义字典列表,创建mongoDB数据库和集合,并对数据库进行添加,删除,修改和排序,和查询数据等操作,输出查询的记录
import pymongo #导入pymongo模块
#创建MongoClient类对象
myclient = pymongo.MongoClient(host='localhost', port=27017)
mydb = myclient.test #选择数据库,如果不存在则新建一个数据库
collection = mydb.student #选择集合,如果不存在则新建一个集合
#定义字典列表
list = [{'id': '001', 'name': '小明', 'age': 10},
{'id': '002', 'name': '小红', 'age': 11},
{'id': '003', 'name': '小刚', 'age': 11},
{'id': '004', 'name': '小蓝', 'age': 12}]
collection.insert_many(list)#将字典列表list添加到数据库中
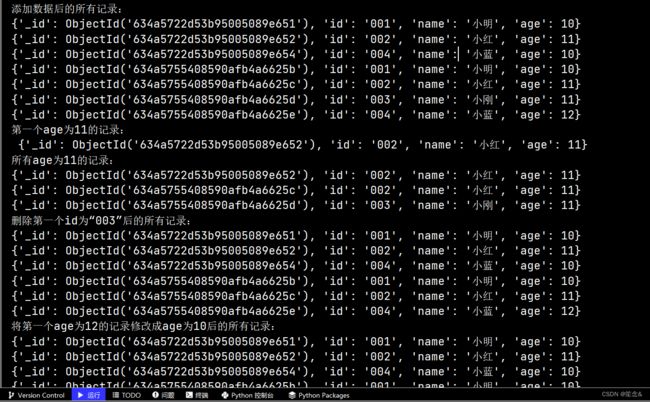
print('添加数据后的所有记录:')
#查询添加数据后的所有记录并输出
for i in collection.find():
print(i)
#查询第一个age为11的记录并输出
print('第一个age为11的记录:\n', collection.find_one({'age': 11}))
print('所有age为11的记录:')
#查询所有age为11的记录并输出
for i in collection.find({'age': 11}):
print(i)
#删除第一个id为“003”的记录
collection.delete_one({'id': '003'})
print('删除第一个id为“003”后的所有记录:')
#查询删除第一个id为“003”后的所有记录并输出
for i in collection.find():
print(i)
#将第一个age为12的记录修改成age为10
collection.update_one({'age': 12}, {'$set': {'age': 10}})
print('将第一个age为12的记录修改成age为10后的所有记录:')
#查询将第一个age为12的记录修改成age为10后的所有记录并输出
for i in collection.find():
print(i)
print('排序后的所有记录:')
#查询排序后的所有记录并输出
for i in collection.find().sort('age'):
print(i)
运行结果
实战演练--爬取中国知网文章信息
目的:使用elenium模拟浏览器爬取数据
将怕爬取到的数据保存到mongodb数据库中
分析

from selenium import webdriver #导入webdriver模块
#导入By模块
from selenium.webdriver.common.by import By
#导入WebDriverWait模块
from selenium.webdriver.support.ui import WebDriverWait
#导入expected_conditions模块
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup #导入BeautifulSoup模块
#导入TimeoutException
from selenium.common.exceptions import TimeoutException
import pymongo #导入pymongo模块
import time #导入time模块
#初始化Google Chrome浏览器对象,并赋值给browser
browser = webdriver.Chrome()
wait = WebDriverWait(browser, 10) #初始化WebDriverWait对象
#创建MongoClient类对象
client = pymongo.MongoClient('localhost', 27017)
mongo = client.cnki #选择数据库,如果不存在则新建一个数据库
collection = mongo.papers #选择集合,如果不存在则新建一个集合
#定义搜索函数,根据传入的关键字搜索
def searcher(keyword):
#请求中国知网首页,打开一个浏览器窗口
browser.get('https://www.cnki.net/')
browser.maximize_window() #最大化窗口
time.sleep(2) #休眠2s
#通过id属性定位“搜索”编辑框节点,并赋值给input
input = wait.until(
EC.presence_of_element_located((By.ID,'txt_SearchText'))
)
input.send_keys(keyword) #输入文本“Python”
#定位“搜索”按钮节点并单击
wait.until(EC.presence_of_element_located(
(By.CLASS_NAME, 'search-btn'))).click()
time.sleep(3) #休眠3s
#定位每页文章篇数列表节点并单击
wait.until(EC.presence_of_element_located(
(By.CSS_SELECTOR, '[class="icon icon-sort"]'))).click()
#定位每页文章篇数“50”节点并单击
wait.until(EC.presence_of_all_elements_located(
(By.CSS_SELECTOR, '#id_grid_display_num ul li'))
)[2].click()
time.sleep(3) #休眠3s
parse_page() #调用parse_page函数
#定义解析网页函数
def parse_page():
wait.until(
EC.presence_of_all_elements_located(
(By.CSS_SELECTOR, '.result-table-list tbody tr')
)
)
html = browser.page_source #获取HTML源代码
#创建BeautifulSoup对象,并设置使用lxml解析器
soup = BeautifulSoup(html, 'lxml')
#使用CSS选择器查找tr节点
items = soup.select('.result-table-list tbody tr')
#遍历列表,提取文章信息
for i in range(0, len(items)):
item = items[i]
detail = item.select('td') #使用CSS选择器查找td节点
paper = {
'index': detail[0].text.strip(),
'title': detail[1].text.strip(),
'author': detail[2].text.strip(),
'resource': detail[3].text.strip(),
'time': detail[4].text.strip(),
'database': detail[5].text.strip()
}
print(paper) #输出文章信息
data_storage(paper) #调用data_storage函数
#将数据存入数据库
def data_storage(paper):
try:
collection.insert_one(paper)
except Exception:
print('failedly storage!', paper)
#定义翻页函数
def next_page():
try:
#判断id值为"Page_next_top"的节点是否可见
page_next = wait.until(
EC.visibility_of_element_located(
(By.CSS_SELECTOR, '#Page_next_top')
)
)
except TimeoutException: #捕获超时异常
return False #返回False
else: #节点可见
page_next.click() #单击节点
return True #返回True
if __name__ == '__main__':
keyword = 'Python' #定义搜索关键字
searcher(keyword) #调用searcher函数,返回HTML源代码
while True: #循环
flag = next_page() #调用next_page函数
time.sleep(5) #休眠5s
#如果next_page函数返回为True,继续调用next_page函数
if flag:
parse_page()
continue
#如果next_page函数返回为False,退出循环
else:
break
browser.close() #关闭浏览器