Workflow as code+SageMaker, DolphinScheduler的机器学习选股系统新玩法
 点亮 ⭐️ Star · 照亮开源之路
点亮 ⭐️ Star · 照亮开源之路
GitHub:https://github.com/apache/dolphinscheduler

作者 | 周捷光 Apache Dolphin
Scheduler
Committer
摘要
Apache DolphinScheduler 已经在DataOps领域提供了强大的分布式可视化工作流调度能力,最新发布的3.1.0版本新增了机器学习任务调度的能力,逐步开箱即用式地支持主流的MLOps项目/服务商的功能。目前已经有MLflow,DVC,Jupyter,OpenMLDB, SageMaker等任务组件可以让用户低成本,更容易地编排机器学习系统。
这次我们介绍基于 YAML 文件来创建机器学习工作流,并在其中使用DolphinScheduler上调用Amazon SageMaker 来进行股票系统训练与预测。
PyDolphinScheduler 3.1.0
![]()
PyDolphinScheduler 3.1.0发布后,用户除了可以使用Python脚本定义工作流以外,也可以使用YAML文件定义工作流。
Python

执行 python tutorial.py即可提交工作流到DolphinScheduler中。
YAML
执行 pydolphinscheduler yaml -f tutorial.yaml即可提交工作流到DolphinScheduler中。
对于喜欢用code形式工作流的的用户,可以直接使用以上两种方法来定义管理工作流,也可以直接搭配git来管理工作流,进行CICD等。
系统介绍
![]()
前情回顾:自动更新选股模型,实时监控,基于 Apache DolphinSchedule 打造机器学习智能选股系统
这次的机器学习选股系统主要有两个新的玩法:
使用pydolphinscheduler来支持workflow as code的方式构建工作流,无需在页面点点点,运行一行命令即可快速创建工作流并运行
下载与处理完股票数据后,会将数据送到Amazon SageMaker中使用SageMaker Pipeline执行数据集处理,训练,评估以及批量推理
系统概况
![]()
![]()
关于系统前后端更详细的介绍可翻阅之前介绍的自动更新选股模型,实时监控,基于 Apache DolphinSchedule 打造机器学习智能选股系统。
接下来会简要回顾系统,并着重介绍如果通过配置文件创建工作流与在DS上调用SageMaker。
系统展示
系统运行原理
选股逻辑
计算整个股票市场中符合五日均线高于10日均线信号的股票作为标的池, 对于上述股票池中的每个股票构建以下特征用于训练模型
股价与布林带三条轨道的相对值
股价与多条均线的相对值;多条均线的多个间隔的斜率
当前K线的形态,用talib pattern计算,如是否为三只乌鸦,是否为十字星等,详情可见K线模式识别(https://www.jianshu.com/p/fd5c7f49db33)
备注:你也可以加上任何你认为有用的信息作为特征
模型训练
以第二天是否上涨进行二分类,使用SageMaker的Pipeline中的训练节点进行训练,每天构建120天的数据集,其中后7天用于评估。
任务调度
系统中所有的任务调度均使用DolphinScheduler完成。
DolphinScheduler可以定时每天晚上自动更新模型,并上线进行预测。在当天模型表现不好时,可以调参调特征一键重新训练新的模型并评估上线。
还有其对任务的容错机制,可以保证系统能够稳定运行。
前端展示
前端展示使用Observable实现,得益于其Notebook丰富和易用的可视化数据分析特性,构建出监控实时选股系统的效果监控。
项目地址
项目中涉及到的工作流任务的实现可以在这里找到 GitHub - DolphinScheduler-MLOps-Stock-Analysis(https://github.com/jieguangzhou/DolphinScheduler-MLOps-Stock-Analysis/tree/sagemaker), 切换至SageMaker 分支。
git clone https://github.com/jieguangzhou/DolphinScheduler-MLOps-Stock-Analysis
cd DolphinScheduler-MLOps-Stock-Analysis
git checkout sagemaker由于前端展示方便与之前无异,因此主要介绍选股系统工作流介绍。
选股系统工作流介绍
![]()
![]()
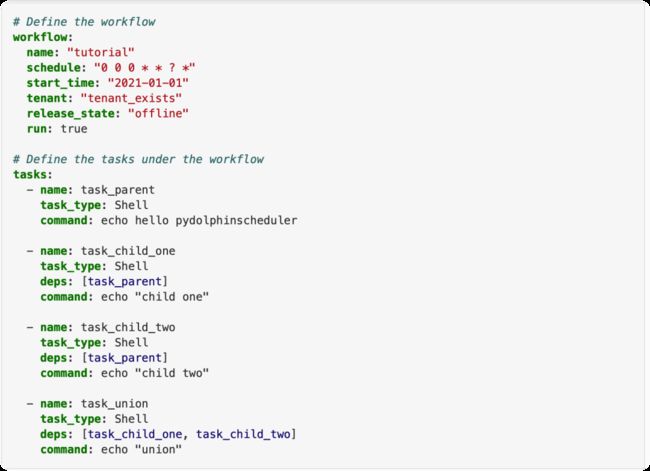
主要包含三个子工作流:
prepare_datas: 每日数据下载,信号计算,特征(在量化交易中称为因子)计算train_model:生成训练数据,调用SageMaker Pipeline更新模型,对模型进行评估与批量数据推理recommend_stock:将SageMaker Pipeline推理的数据下载下来后录入数据库进行股票推荐。
以下是几个子工作流的介绍:
Prepare datas
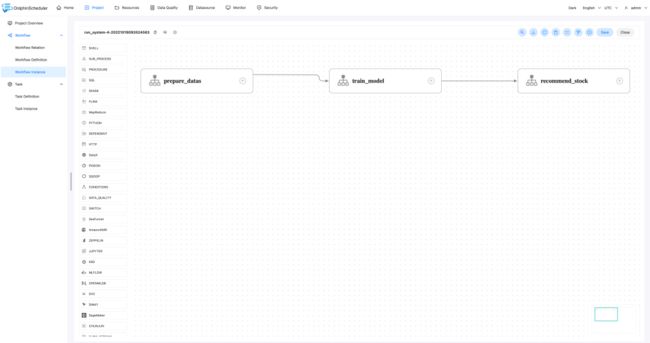
下图所示是数据准备的工作流 prepare_datas,该工作流会下载股票数据并进行信号计算和特征计算
download_data: 下载全市场的股票日线数据calc_signals:进行信号计算(计算每天符合信号条件的股票,如每天5日均线与10日均线金叉的股票)calc_features: 特征(量化交易中称为因子)计算(计算每个股票每天的特征值,如收盘价与5日均线的相对值,股票是否是十字星形态等)
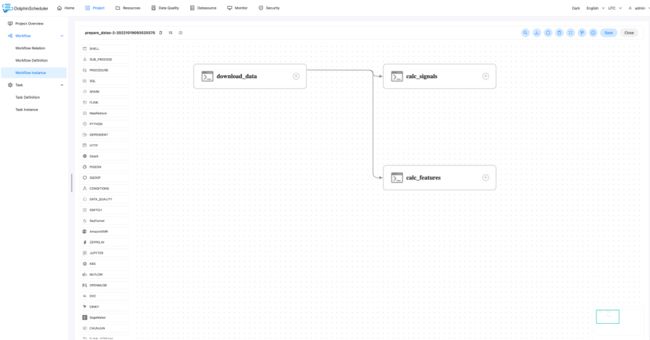
上面定义了工作流prepare_datas,包含三个任务。
training_model
下图为工作流 training_model 的各个任务的DAG图,该工作流主要执行以下任务
prepare_trainging_data: 准备模型训练数据,并上传至Amazon S3中(后会交给SageMaker进行数据转换成训练集,验证集和测试集)prepare_inference_data: 准备需要预测的股票数据,并上传至Amazon S3中sagemaker:执行SageMaker Pipeline
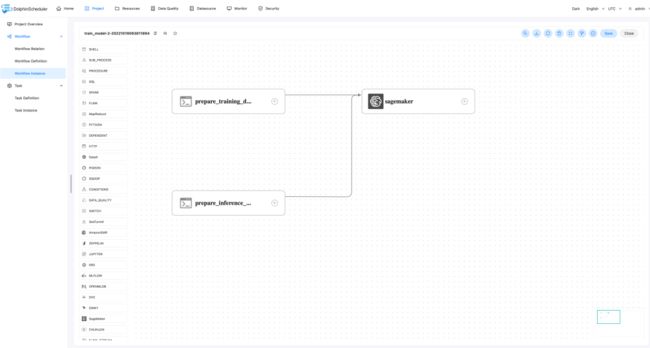
SageMaker
其中sagemaker组件中的任务定义如下,JSON数据与AWS SageMaker pipeline启动数据格式一致,包含pipeline的名字和入参等。
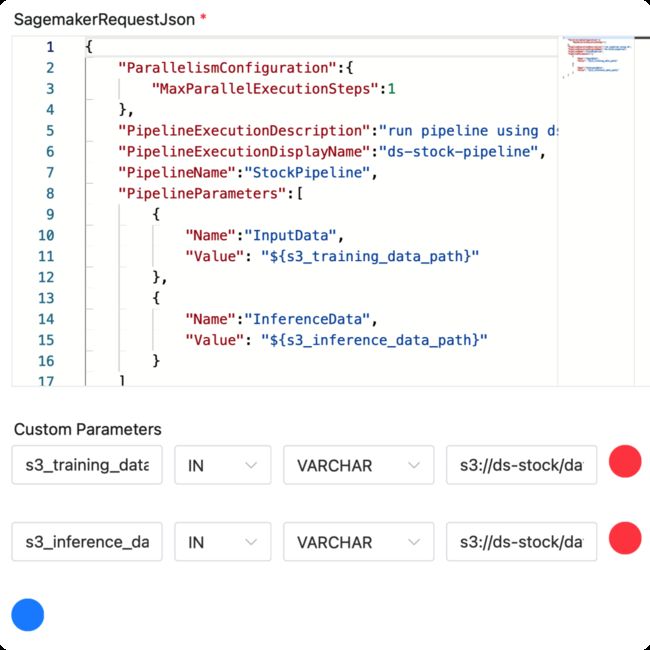
该任务中,会启动一个SageMaker Pipeline的执行,并持续跟踪执行的情况,直至其完成。
其他的信息可见DolphinScheduler SageMaker组件文档(https://dolphinscheduler.apache.org/zh-cn/docs/dev/user_doc/guide/task/sagemaker.html)
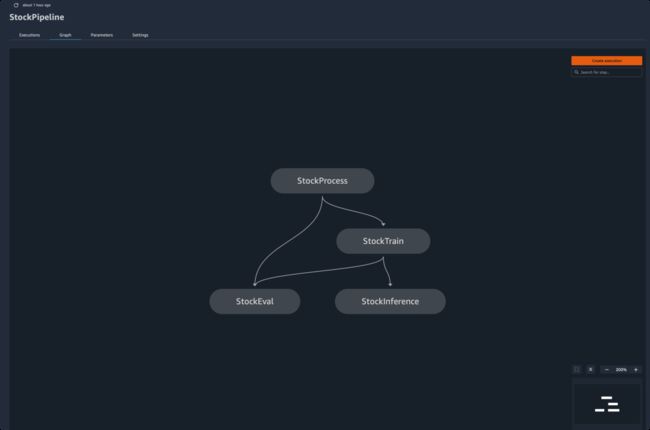
Pipeline主要有4个步骤:
StrockProcess: 处理数据集成为SageMaker内置算法适配的格式,并切分为训练集,验证集和测试集
StockTrain: 训练模型
StockEval: 评估模型
StockInference: 使用模型进行批量股票预测
Pipeline定义的notebook可见: DolphinScheduler-MLOps-Stock-Analysis/pipeline_stock.ipynb at sagemaker(https://github.com/jieguangzhou/DolphinScheduler-MLOps-Stock-Analysis/blob/sagemaker/pipeline_stock.ipynb)
在Amazon SageMaker Studio中可以查看:
recommend_stock
YAML 文件定义如下:
该工作流目前只有一个任务,DS中显示如下:

run_system
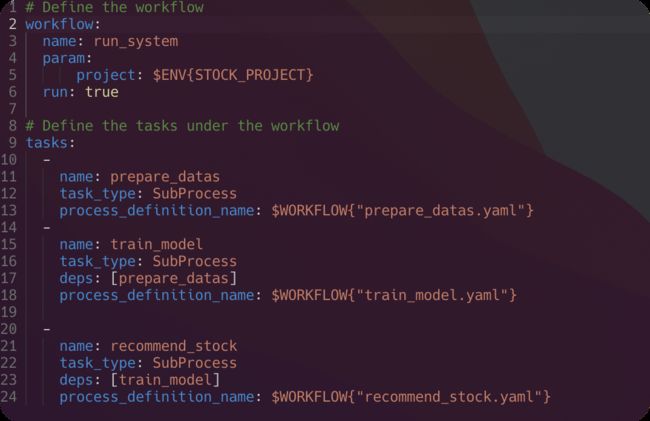
现在我们需要将三个工作流合并成一个名为run_system的工作流,即我们展示的

定义YAML文件:
其中
$ENV{STOCK_PROJECT}语法表示会将环境变量STOCK_PROJECT进行填充$WORKFLOW{"prepare_datas.yaml"}语法表示创建prepare_datas.yaml中的工作流并引用其名字,填充进来作为子工作流。
创建并执行工作流
我们创建一个sh文件 pydolphin_init.sh如下:
# /bin/bash
# init config
user=Stock-Analysis
password=123456
tenant=$USER
project_name=pydolphin
api_address=127.0.0.1
api_port=25333
pydolphinscheduler config --set java_gateway.address $api_address
pydolphinscheduler config --set java_gateway.port $api_port
pydolphinscheduler config --set default.user.name $user
pydolphinscheduler config --set default.user.password $password
pydolphinscheduler config --set default.user.tenant $tenant
pydolphinscheduler config --set default.workflow.user $user
pydolphinscheduler config --set default.workflow.tenant $tenant
pydolphinscheduler config --set default.workflow.project $project_name
pydolphinscheduler config --set default.workflow.queue default
# 以上配置为pydolphinscheduler相关配置,包含ds地址,端口配置,以及租户,用户,项目的创建(若不存在)
# 以下为创建工作流的命令
# 配置环境变量,将会在yaml中引用
export STOCK_PROJECT=$(pwd)
# 创建工作流
pydolphinscheduler yaml -f pyds/run_system.yaml我们就可以运行该脚本来启动选股系统项目了。
项目实操
![]()
![]()
DolphinScheduler安装与启动
安装dolphinscheduler
下载安装包:apache-dolphinscheduler-3.1.0-bin.tar.gz(https://www.apache.org/dyn/closer.lua/dolphinscheduler/3.1.0/apache-dolphinscheduler-3.1.0-bin.tar.gz)
Standalone启动详情可见(https://dolphinscheduler.apache.org/zh-cn/docs/latest/user_doc/guide/installation/standalone.html)
解压:
tar -zxvf apache-dolphinscheduler-3.1.0-bin.tar.gz
cd apache-dolphinscheduler-3.1.0-bin修改配置standalone-server/conf/common.properties 中以下字段添加 aws 密钥,用于SageMaker组件的身份验证
# The AWS access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.access.key.id=
# The AWS secret access key. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.secret.access.key=
# The AWS Region to use. if resource.storage.type=S3 or use EMR-Task, This configuration is required
resource.aws.region= 启动DolphinScheduler
bash bin/dolphinscheduler-daemon.sh start standalone-server登录 DolphinScheduler
浏览器访问地址 http://localhost:12345/dolphinscheduler/ui 即可登录系统UI。默认的用户名和密码是 admin/dolphinscheduler123
DolphinScheduler-MLOps-Stock-Analysis
现在我们拉取选股系统的代码,并切换至sagemaker分支
git clone https://github.com/jieguangzhou/DolphinScheduler-MLOps-Stock-Analysis
cd DolphinScheduler-MLOps-Stock-Analysis
git checkout sagemaker修改一下dmsa/db.py中的mysql配置,来保存信号特征和股票推荐结果
class CONFIG:
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123456'
MYSQL_HOST = 'xxxxxxxxxxxxxxxx'
MYSQL_PORT = 3306
MYSQL_DATABASE = 'dolphinscheduler_mlops_stock'因为需要将数据上传到AWS S3,需要配置一下文件 ~/.aws/config
[default]
aws_access_key_id =
aws_secret_access_key =
region = 准备Python环境
virtualenv -p /usr/bin/python3 env
source env/bin/activate
pip install -r requirements.txt安装PyDolphinScheduler: python -m pip install apache-dolphinscheduler,可以在任意python环境中安装,实际任务执行无需pydolphinscheduler,pydolphinscheduler用于快速使用code的形式提交工作流。
然后执行命令 bash pydolphin_init.sh 即可。
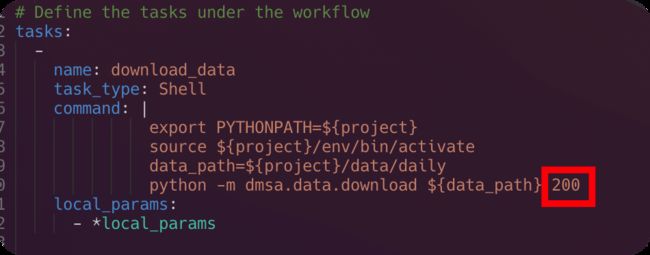
如果想要快速运行,可以在 pyds/prepare_datas.yaml中的 python -m dmsa.data.download ${data_path} 后面加上200,表示只用200个股票进行pipeline的执行
总结
![]()
本文展示了在DolphinScheduler中使用yaml配置文件构建和执行工作流,并从中调用Amazon SageMaker Pipeline提供机器学习能力,构建机器学习选股系统。希望能给大家带来以下收获::
了解如何使用DolphinScheduler构建一个选股系统。
了解如何使用DolphinScheduler连接MLOps系统与其上下游任务。
了解DolphinScheduler SageMaker 组件的使用。
了解DolphinScheduler 通过配置文件管理工作流的实践。

 打个广告:
打个广告:
如果你对DolphinScheduler构建机器学习系统感兴趣可以加入社区一起参与交流
如果你有DolphinScheduler有构建机器学习系统或者调度机器学习任务经验的同学也欢迎投稿
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。
![]()
参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:
![]()
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
< >
活动推荐
Apache DolphinScheduler Meetup
金融与物流场景深度实践
活动形式:线上直播
活动时间:2022 年 10 月 29 日 14:00-15:30
报名方式:点击链接「一键报名」或扫描二维码预约
https://www.slidestalk.com/m/1256



添加小助手进交流群
我知道你在看哟