【2022年MathorCup大数据竞赛】B题:北京移动用户体验影响因素研究(二)(问题一的分析和结果)
目录:题目解析
- 一、问题的解答框架
- 二、问题一的分析
-
- 2.1 附件1的处理流程
- 2.2 附件2的处理流程
-
- 2.2.1 拉格朗日插补法
- 2.3 数据编码
- 2.4 相关分析
- 2.5 基于互信息+GBDT的特征提取
- 2.6 量化分析
一、问题的解答框架
二、问题一的分析
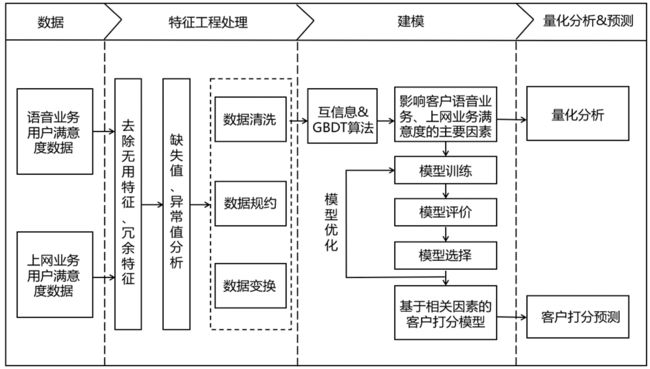
针对问题一,首先需要对附件1和附件2提供的数据进行分析和处理。
附件1提供了5433个样本数据,包含用户语音业务的满意度及其50个影响因素;
附件2提供了7020个样本数据,包含用户上网业务的满意度及其120个影响因素。
其中,原始数据在采集或传输过程中因为某种原因出现了数据缺失等问题,导致数据质量下降,进而会影响后续建立客户打分基于相关影响因素的数学模型,故在研究影响客户语音业务和上网业务满意度的主要因素之前,需要对附件1数据和附件2数据进行特征工程处理。
本文对上述数据的预处理主要包含如下过程:首先,删除无用特征和冗余特征;其次,根据附件5说明填充部分空值;然后,对于附件1,空值比例超过50%的影响因素直接删除,空值比例没有超过50%的离散型特征选择用众数填补,连续型特征选择用0填补;对于附件2,对于离散型特征选择用众数填补,小范围缺失的连续型特征用拉格朗日插值法进行填补,其余连续型特征用0填补;最后对数据集进行填充替换,选用CatBoost Encoder对数据集进行编码,方便进一步研究。
由于问题一需要分别研究影响用户语音业务和上网业务满意度的主要因素,而附件1用户语音业务的满意度包括语音通话整体满意度、网络覆盖与信号强度、语音通话清晰度和语音通话稳定性四个方面,以及经过特征工程处理之后的影响因素;附件2用户上网业务的满意度包括手机上网整体满意度、网络覆盖与信号强度、手机上网速度和手机上网稳定性四个方面,以及经过特征工程处理之后的影响因素。
本文先对影响因素进行互信息提取,在此基础上采用GBDT算法进行提取主要影响因素并进行量化分析。
2.1 附件1的处理流程
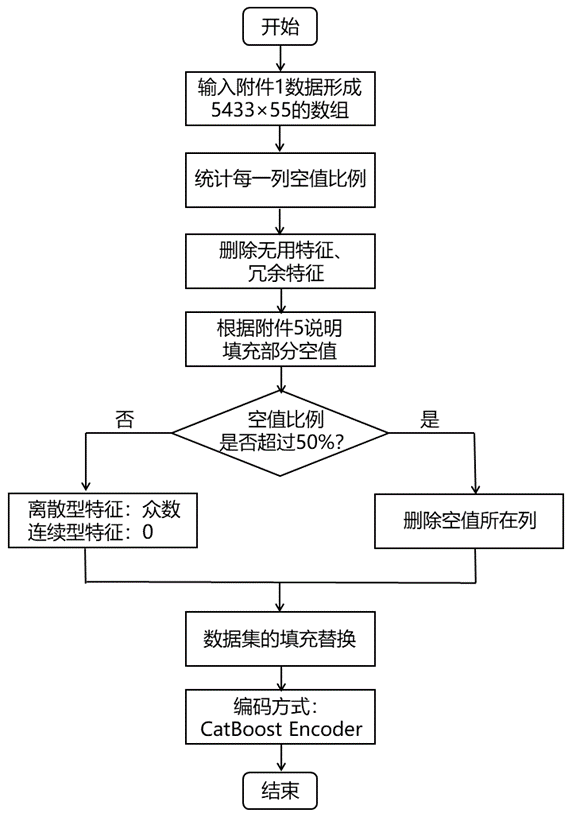
首先,统计每一列特征的空值比例,删除无用特征以及冗余特征;其次,根据附件5的备注说明填补部分空值;然后,删除空值比例超过50%的特征;空值比例没有超过50%的离散型特征选择用众数填补,连续型特征选择用0填补。附件1特征变量缺失值数量、缺失值占比以及处理方式如下表所示:

附件1语音业务用户满意度数据共有15个特征变量含有缺失值,其中当月欠费金额、客户星级标识等特征的缺失值占比非常小,远小于0.1%,因此,对此类含有缺失值的变量进行填充处理,其中连续型特征用0填补,离散型特征用众数填补;而用户描述.1、是否关怀用户、用户描述、重定向驻留时长、重定向次数以及是否去过营业厅的缺失值占比大于50%,这些变量中存在大量缺失,其中附件5对是否关怀用户以及是否去过营业厅进行说明,空白的用“否”进行填补,用户描述.1、用户描述、重定向驻留时长以及重定向次数认定该特征变量提供的信息有限,因此选择删除,故最终剩余46个影响因素。
2.2 附件2的处理流程
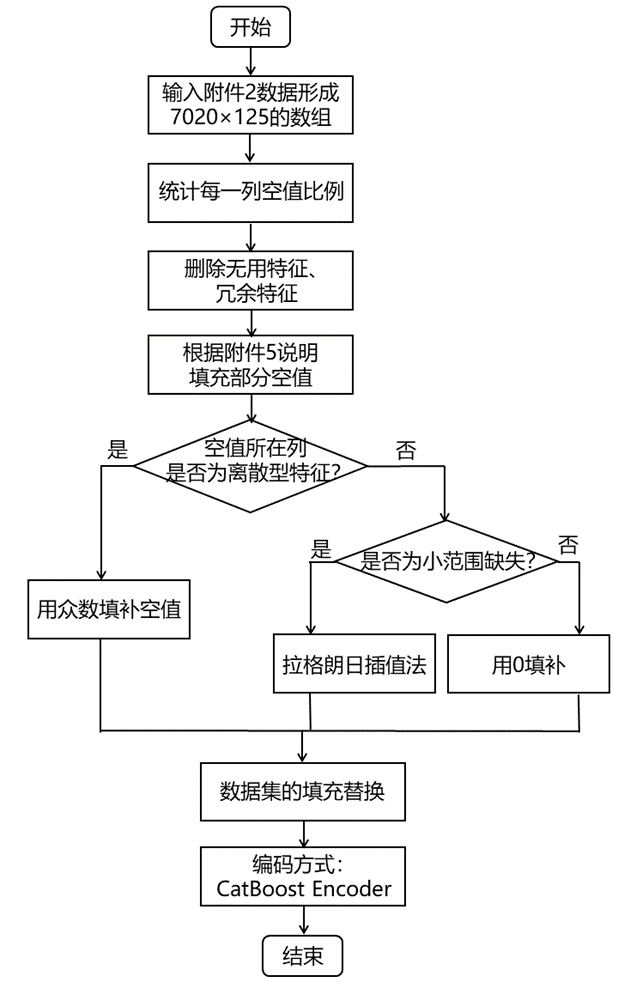
附件2提供了7020个样本数据,相关指标包括语手机上网整体满意度、网络覆盖与信号强度、手机上网速度和手机上网稳定性四个用户语音业务的满意度及其120个影响因素。首先,统计每一列特征的空值比例,删除无用特征以及冗余特征;其次,根据附件5的备注说明填补部分空值;然后,对于离散型特征选择用众数填补,小范围缺失的连续型特征用拉格朗日插值法进行填补,其余连续型特征用0填补。附件2特征变量缺失值数量、缺失值占比以及处理方式如表所示:
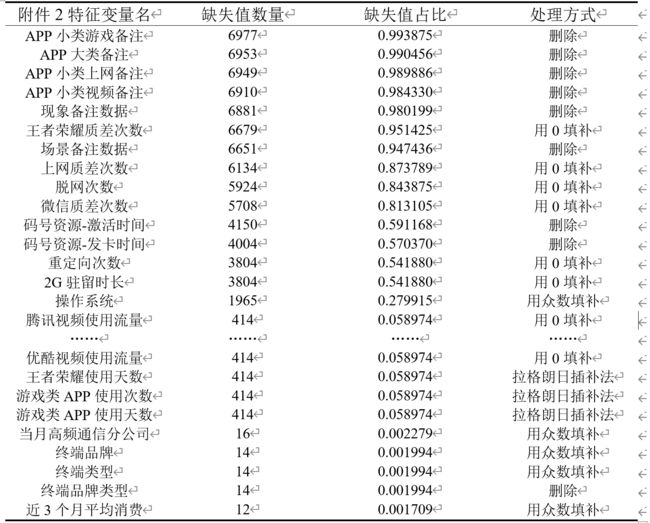
附件2上网业务用户满意度数据共有29个特征变量含有缺失值,其中腾讯视频使用流量、优酷视频使用流量等变量的缺失值占比非常小,远小于0.1%,因此,对此类含有缺失值的变量进行填充处理,而APP小类游戏备注、APP大类备注等变量的缺失值占比大于50%,这些变量中存在大量缺失这些变量中存在大量缺失,其中附件5对上网质差次数、脱网次数、重定向次数、2G驻留时长、微信质差次数、王者荣耀质差次数进行说明,空白的用0进行填补,其他变量则有理由认定该特征变量提供的信息有限,因此选择删除,故最终剩余111个影响因素。
2.2.1 拉格朗日插补法
拉格朗日插值法(Lagrange interpolation)是一种多项式插值方法。如对实践中某个物理量进行观测,在若干个不同的地方得到相应的观测值,拉格朗日插值法可以找到一个多项式,其恰好在各个观测点取到观测到的值。从数学上来讲,拉格朗日插值法可以给出一个恰好穿过二维平面上若干个已知点的多项式函数,并且可以证明,经过n+1个互异的点的次数不超过n的多项式是唯一存在的。应用拉格朗日插值公式所得到的拉格朗日插值多项式为:
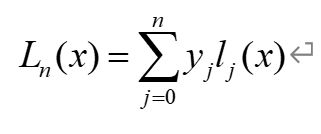
![]()
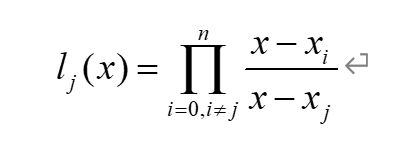
在插值计算中,为了减少截断误差,选择插值结点时尽量选取与插值点距离较近的一些结点。本文针对连续缺失小于3条的数据,取其前后5条数据进行拉格朗日插值从而将缺失部分补充完整;针对连续缺失条数较多的数据,由于无法在其相邻时刻取到足够多的点,因此采用均值插补的方法将剩余缺失数据补充完整。
对附件2中的缺失值小于0.1%且小范围缺失的连续型变量采用拉格朗日插值法进行缺失值填补,包括王者荣耀使用天数、游戏类APP使用天数和游戏类APP使用次数三个特征。
2.3 数据编码
对附件1和附件2的数据进行缺失值处理后,数据属于问卷数据类型,类别用不同数字进行区分,本文还需要对数据集进行填充替换。由于数据集中大多数变量为离散型变量,对于此类变量,在一般的统计分析中难以处理,而且大部分数学模型要求数据是数字格式的,对于非数值型这种非数字格式,则需要将其转换为数字形式的数值型变量,这个过程又称为对非数值型变量的编码。常见的数据编码方式很多,其中最常见的编码方式包括Label Encoder、OneHot Encod、Target Encoder及Catboost Encoder等。




Label Encoder随机地给特征排序,会给这个特征增加不存在的顺序关系,即对数据增加了不必要的噪声;OneHot Encoder在离散特征的取值过多的时候,会导致生成特征变量的数量太多导致特征维度爆炸且过于稀疏;Target Encoder使模型更难学习均值编码变量和另一个变量之间的关系,仅基于列与目标的关系就在列中绘制相似性,且这种编码方法对目标变量非常敏感,这会影响模型提取编码信息的能力,此外,由于该类别的每个值都被相同的数值替换,因此模型可能会过拟合其见过的编码值。
综合上述分析,问题一采用CatBoost Encoder对附件1和附件2的离散型变量进行编码转化为数值型变量。
2.4 相关分析
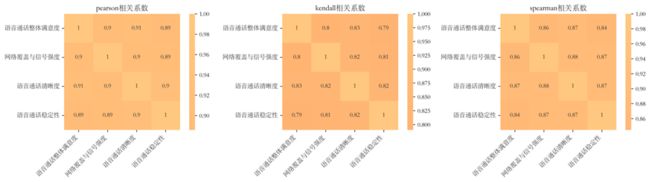
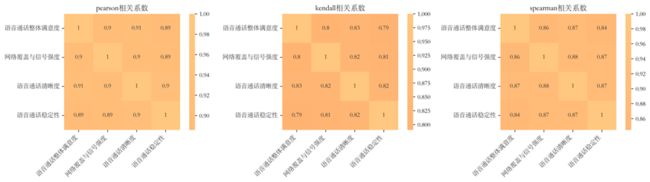
语音业务三个方面的评分与整体满意度之间的三种相关系数均在0.79以上,这说明语音业务三个方面的评分与整体满意度之间是高度相关的。因此在问题二的预测中,本文可以以语音整体满意度作为基准进行模型的优化处理与选择,后面对另外三个指标直接运用对应的模型进行预测。同理用于上网的业务。
2.5 基于互信息+GBDT的特征提取
先对影响因素分别计算与四个打分指标之间的互信息值,选择互信息值大于等于1%的影响因素,然后再对大于互信息阈值的影响因素采用GBDT算法提取主要影响因素。


GBDT的算法原理较为常见,不再详细讲解!(用随机森林的效果差不多)
首先对附件1所有影响因素计算和语音整体满意度的互信息值:

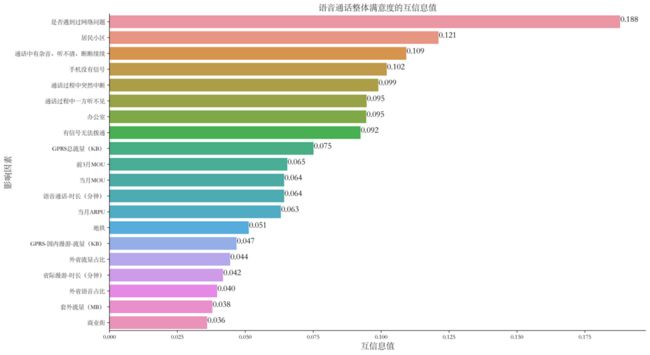
可视化前20个影响因素和语音整体满意度的互信息值:
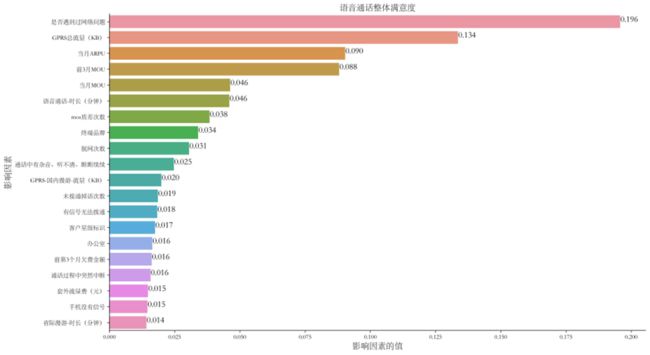
进一步采用GBDT算法对语音通话整体满意度及其影响因素再一次选择,特征重要性如下所示:

可视化前20个语音整体满意度的特征重要性:
绘制了语音业务前20个影响因素的热力图,分析前20个影响因素之间的相关性:
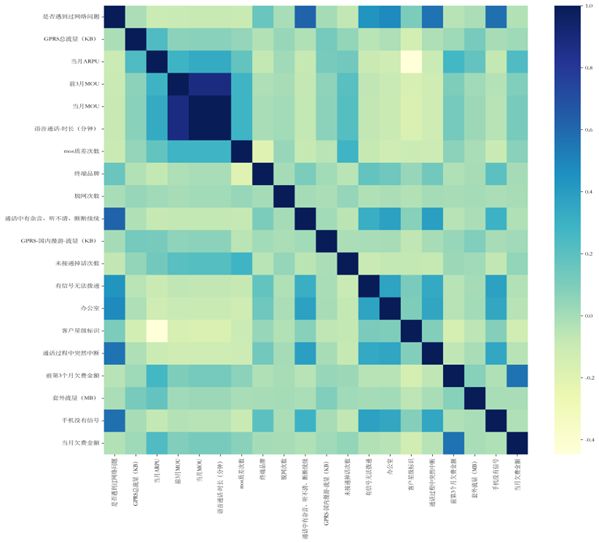
可认为这20个主要影响因素之间各自具有一定的代表性!
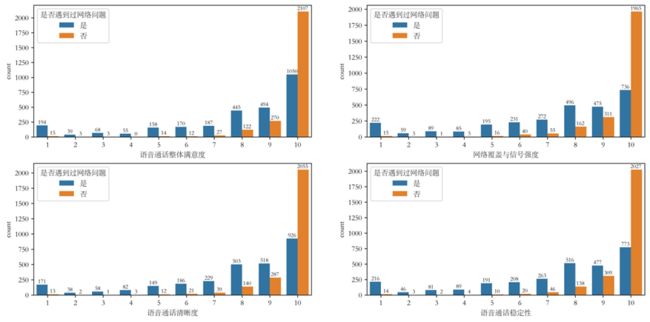
排名前三的影响因素为是否遇到过网络问题、GPRS总流量(KB)以及当月ARPU,影响因素的值分别为0.196、0.134、0.090。
由于网络覆盖与信号强度、语音通话清晰度和语音通话稳定性与语音通话整体满意度的互信息值以及特征重要性相似,分析方法相同,故网络覆盖与信号强度、语音通话清晰度和语音通话稳定性的互信息值以及特征重要性不再多写。
上网业务的分析同上!
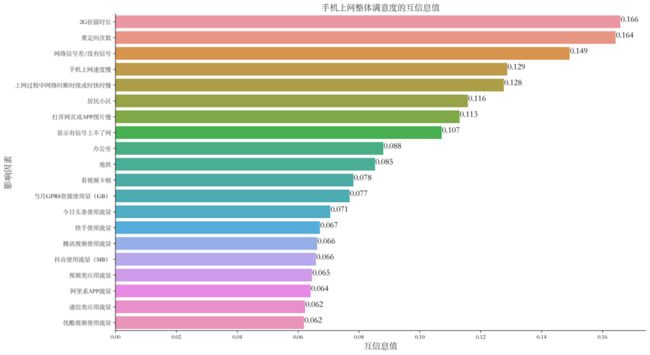
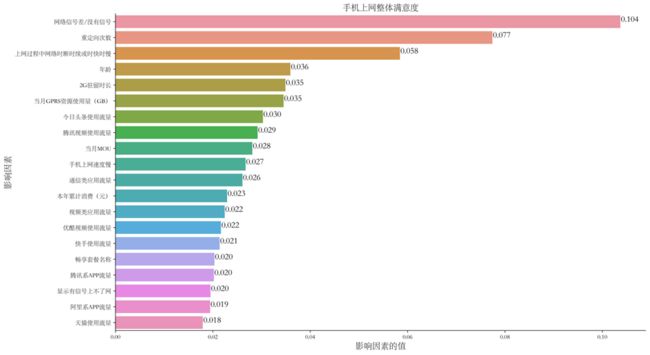
排名前三的影响因素为网络信号差/没有信号、重定向时长以及上网过程中网络时断时续或时快时慢,影响因素的值分别为0.104、0.077、0.058。
2.6 量化分析
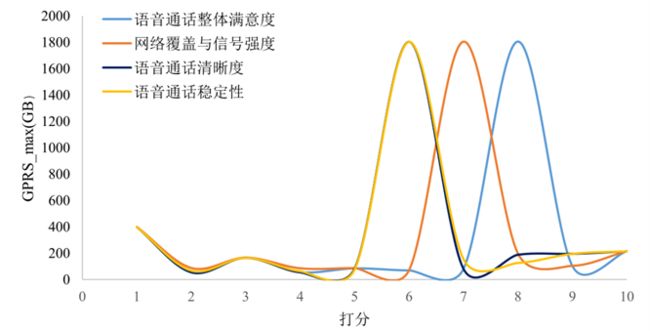
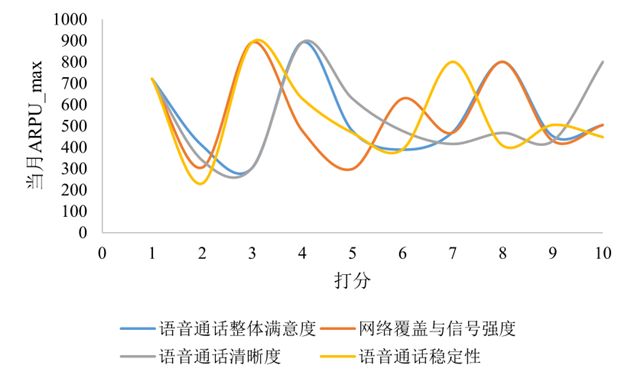
这里我们只写语音业务的量化分析。
本文主要选取了附件1语音业务排名前三的影响因素进行量化分析,即对是否遇到过网络问题、GPRS总流量(KB)以及当月ARPU进行量化分析。