汽车领域多语种迁移学习挑战赛-Coggle 30 Days of ML
前言
依然是coggle的7月竞赛学习活动,本博客围绕着汽车领域多语种迁移学习挑战赛展开。
- 比赛地址:http://challenge.xfyun.cn/topic/info?type=car-multilingual&ch=ds22-dw-zmt05
- 活动地址:https://coggle.club/blog/30days-of-ml-202207
上一个任务是糖尿病遗传风险检测挑战赛,传送门:
糖尿病遗传风险检测挑战赛-Coggle 30 Days of ML
一、赛题理解
本赛题为标准的nlp领域的任务,需要通过给定的语料,完成相应的关键字提取和文本分类任务。关键词提取主要是考察对于文本的结构分析以及一些常见的分词工具如jieba、jiagu等等的使用,文本分类则要用到如今在nlp如日中天的预训练+微调这套东西(当然如果能把语料吃透,用字典或者规则也行),个人感觉这项工作对于不熟悉nlp的同学的要求要高一大截,但是如果能啃下来收获也是非常大的。
1.1 数据读取
照例还是先看看给的数据,训练集包含中文、英文、日语三类语言,其中英语和日语油给出了相应的中文翻译:
中文语料:
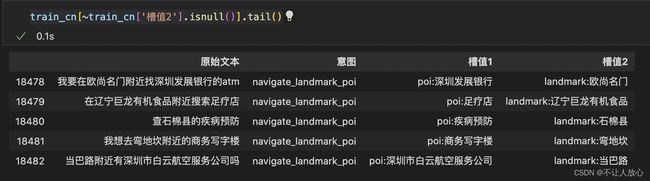
英文语料:

日文语料:

再看看给的提交示例(A榜):

基本上就能确定了,这个任务就是要尽可能的填上“意图”列和两个“槽值”列,“意图”对应着文本分类,“槽值”则是关键词提取。
2.2 数据概览
以下两部分代码均来自于一位同样参与打卡活动的大佬@千千惠儿,能够在动手之前先对文本语料有一个大致的把握,首先是文本长度分布 :
import matplotlib.pyplot as plt
import seaborn as sns
fig,axes=plt.subplots(1,3, figsize=(20, 5)) #创建一个1行三列的图片
train_cn['Chinese_text_len'] = [len(i) for i in train_cn["原始文本"]]
train_en['English_text_len'] = [len(i.split(" ")) for i in train_en["原始文本"]]
train_ja['Japan_text_len'] = [len(i) for i in train_ja["原始文本"]]
sns.distplot(train_cn['Chinese_text_len'],bins=10,ax=axes[0])
sns.distplot(train_en['English_text_len'],bins=10,ax=axes[1])
sns.distplot(train_ja['Japan_text_len'],bins=10,ax=axes[2])

然后是意图分布:
df_ana = pd.DataFrame()
for label,df in zip(['中文','英文','日文'],[train_cn,train_en,train_ja]):
temp = pd.DataFrame(df.意图.value_counts()).reset_index()
temp.columns = ['%s意图'%label,'个数']
df_ana = pd.concat([df_ana,temp],axis=1)
df_ana
槽值的槽点有点多,一时间想不到统计它的作用,所以这里就先不管了,不过我上方的传送门里那位大佬也针对这俩字段有所处理,感兴趣的同学可以移步看看。
二、文本分词
这块工作主要是熟悉一些常见的分词工具,中文和日文毕竟不像英文那样有空格隔开,所以想把一句话拆成几个词,还是需要一些成熟的词典工具进行辅助。比如jieba、jiagu还有coggle打卡活动中提示用于日语分词的nagisa,实际上这些工具除了能完成句子的分词任务以外,还能够给出相应词汇的词性(比如名词、动词、形容词等等),如果能用好这一点,至少可以粗略的定义一些规则,同样可以完成一些现实任务。
train_cn['words'] = train_cn['原始文本'].apply(jieba.lcut)
train_en['words'] = train_en['原始文本'].apply(lambda x:x.split(' '))
train_ja['words'] = train_ja['原始文本'].apply(lambda x:nagisa.tagging(x).words)
三、TFIDF与文本分类
3.1 TF-IDF
关于它的原理放个传送门:机器学习:生动理解TF-IDF算法。在做文本分类任务时,一个很重要的任务就是完成文本的向量化表示(这个是nlp的基础),TFIDF所提供的就是一种基于词频次的文本向量化表示方式,为了进一步理解它,我们不妨直接动手试一下:
from sklearn.feature_extraction.text import TfidfVectorizer
tv = TfidfVectorizer(use_idf=True, smooth_idf=True, norm=None)
words_list = [ # 每行表示一个文本
"i am a good boy",
"i am a bad boy",
"she is so pretty",
"she drives me crazy",
"i fell in love with her"
]
tv_fit = tv.fit_transform(words_list)
查看一下构建的词汇表以及表的长度:
 再查看一下向量化的结果:
再查看一下向量化的结果:
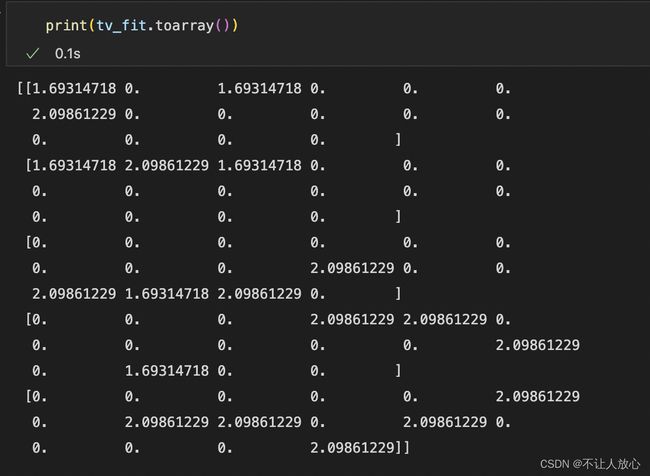
输出的是一个5*16的矩阵,这就很明显了。TfidfVectorizer根据抽取出来的16个词汇表来为每句话进行向量化操作,每一行代表对应的一个文本的向量化结果。
3.2 文本分类(意图分类)
了解了这个,其实就可以完成相应的文本分类任务了,要做的事情就是把原本的文本段落和对应的意图的用TFIDF进行向量化,然后采用相应的模型进行训练即可,这里直接贴上活动官方给的代码了:
## copy from https://coggle.club/blog/30days-of-ml-202207
import pandas as pd # 读取文件
import numpy as np # 数值计算
import nagisa # 日文分词
from sklearn.feature_extraction.text import TfidfVectorizer # 文本特征提取
from sklearn.linear_model import LogisticRegression # 逻辑回归
from sklearn.pipeline import make_pipeline # 组合流水线
# 读取数据
train_cn = pd.read_excel('汽车领域多语种迁移学习挑战赛初赛训练集/中文_trian.xlsx')
train_ja = pd.read_excel('汽车领域多语种迁移学习挑战赛初赛训练集/日语_train.xlsx')
train_en = pd.read_excel('汽车领域多语种迁移学习挑战赛初赛训练集/英文_train.xlsx')
test_ja = pd.read_excel('testA.xlsx', sheet_name='日语_testA')
test_en = pd.read_excel('testA.xlsx', sheet_name='英文_testA')
# 文本分词
train_ja['words'] = train_ja['原始文本'].apply(lambda x: ' '.join(nagisa.tagging(x).words))
train_en['words'] = train_en['原始文本'].apply(lambda x: x.lower())
test_ja['words'] = test_ja['原始文本'].apply(lambda x: ' '.join(nagisa.tagging(x).words))
test_en['words'] = test_en['原始文本'].apply(lambda x: x.lower())
# 训练TFIDF和逻辑回归
pipline = make_pipeline(
TfidfVectorizer(),
LogisticRegression()
)
pipline.fit(
train_ja['words'].tolist() + train_en['words'].tolist(),
train_ja['意图'].tolist() + train_en['意图'].tolist()
)
# 模型预测
test_ja['意图'] = pipline.predict(test_ja['words'])
test_en['意图'] = pipline.predict(test_en['words'])
test_en['槽值1'] = np.nan
test_en['槽值2'] = np.nan
test_ja['槽值1'] = np.nan
test_ja['槽值2'] = np.nan
# 写入提交文件
writer = pd.ExcelWriter('submit.xlsx')
test_en.drop(['words'], axis=1).to_excel(writer, sheet_name='英文_testA', index=None)
test_ja.drop(['words'], axis=1).to_excel(writer, sheet_name='日语_testA', index=None)
writer.save()
writer.close()
本着多试试没毛病的原则,又把LogisticRegression改成RandomForestClassifier试了一下,最终两个结果:

3.3 扯点别的
自从bert出现之后,这种预训练-微调的这种模式几乎成为解决各种nlp问题的基本范式了,但是我个人依然认为理解并掌握经典的文本分类原理和工程思路还是十分有必要的。
对于本赛题,这种意图的预测方式确实有点粗暴,却意外有效,但是一个不得不提及的点是从头到尾并没有用到占绝大对数的中文语料,这毫无疑问是个很大的遗憾。
四、正则表达式
本节任务:
- 步骤1:学习使用正则表达式,并提取文本中的连续数值;
- 步骤2:使用正则表达式进行槽值匹配(基于历史的槽值字符串)。
正则表达式这东西确实是比较让人犯愁的东西,大部分人都知道有这么个东西也知道它能用来干啥,但是真正用的时候又得去翻翻资料(知识点太琐碎了,而且没有全部记忆的必要)。在python中,有专门的re包可以负责干这个事,它常常配合request、bs4等模块,完成一些爬虫工作。
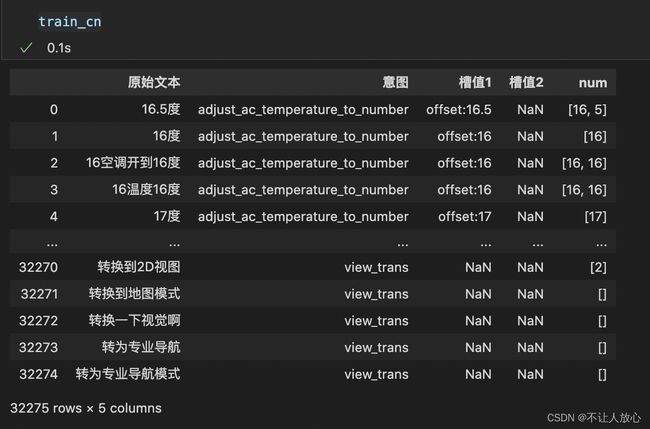
4.1提取文本中的连续数值
import re
train_cn['num'] = train_cn['原始文本'].map(lambda x: re.findall("\d+", x))
train_ja['num'] = train_cn['原始文本'].map(lambda x: re.findall("[一|二|三|四|五|六|七|八|九|十]+",x))
## 英文的没有数字,不管了
结果:
4.2 使用正则表达式进行槽值匹配
这项工作的核心就是对数据集的观察,在2.2数据预览这部分,我们不难注意到,中英日这三类语言的意图是固定的,前面基于TFIDF完成的文本分类工作,本质上就是把它看作一个多分类的问题,明确了这一点,我们再来挨个观察一下训练集中不同的意图,这里以英文为例,可以得到下面这个表:

代码如下,关于music_search、poi这三个意图,我个人确实没能想到很好的基于规则的处理方案,如果有其它想法的小伙伴欢迎交流(个人邮箱:[email protected])。
caozhi_en = []
num_list = ['one','two','three','four','five','six','seven','eight','nine','ten',
'eleven','twelve','thirty','forty','fifty','sixty','seventy','eighteen','nineteen','twenty']
for index,row in test_en.iterrows():
if row["意图"]=="adjust_ac_temperature_to_number" or row["意图"]=="adjust_ac_windspeed_to_number":
words_split = row["words"].split(" ")
num_str = "offset:"
for word in words_split:
if word in num_list:
num_str = num_str + word
if word.find("-") != -1:
num_str = num_str + word
caozhi_en.append(num_str)
elif row["意图"]=="open_car_device":
device_str = "device:"
search = re.search("atmosphere Lamp|car's roof|car window|sunshade|window|sunroof|roof",row["原始文本"])
if search:
device_str = device_str + search.group()
caozhi_en.append(device_str)
elif row["意图"]=="close_car_device":
device_str = "device:"
search = re.search("Automobile Ambient atmosphere Lamp|atmosphere Lamp|Car sunshade|car's roof|car roof|car window|sunshade|sunlight roof|window|sunroof|roof",row["原始文本"])
if search:
device_str = device_str + search.group()
caozhi_en.append(str(device_str))
elif row["意图"]=="open_ac_mode":
mode_str = "mode:"
search = re.search("automatic mode|cooling mode|heating mode|inner loop|Automatic",row["原始文本"])
if search:
mode_str = mode_str + search.group()
caozhi_en.append(str(device_str))
else:
caozhi_en.append(np.nan)
test_en['槽值1'] = caozhi_en
test_en['槽值2'] = np.nan
日文的同理,这里黄色和绿色的完全可以用正则进行匹配(绿色的要稍微麻烦一些),其余的就都暂时不管了。提交结果:

提交的时候已经是二阶段了(汗颜耽误了这么多天),由于数据集不一样,没办法跟之前的做比较,但是可以确定的是对于赛题数据的解析,必要时还是会起到作用。现阶段一个很值得注意的点是,目前所有的“槽值”的匹配,都依赖于前一步得到的"意图",这是不希望见到的,因此还有很大的优化空间。
五、BERT模型入门
本节任务:
- 步骤1使用BERT完成意图识别(文本分类)
- 步骤2:将步骤1预测的结果文件提交到比赛,截图分数;
关于BERT的原理,这里安利一个b站大佬的讲解:【BERT模型】暴力的美学,协作的力量(好看不火系列)。由于BERT独有的训练方式,加之超大的预料,使得它天然就具备向文本分类、命名实体识别等下游任务迁移的能力。
这部分迁移自讯飞的另一个比赛:基于论文摘要的文本分类与查询性问答baseline。
整个工程分为以下几个阶段,首先是读取数据文件:
train_cn = pd.read_excel('./data/中文_trian.xlsx')
train_ja = pd.read_excel('./data/日语_train.xlsx')
train_en = pd.read_excel('./data/英文_train.xlsx')
test_en = pd.read_excel('testB.xlsx',sheet_name='英文_testB')
test_ja = pd.read_excel('testB.xlsx',sheet_name='日语_testB')
然后进行数据的合并,对训练意图使用pd.factorize方法编码
train_df = train_df.sample(frac=1.0) # 对原来的数据进行随机
train_df['intent_factorize'], intent_ecode = pd.factorize(train_df['意图']) # 使用pd.factorize方法编码
然后就是借助bert-base-multilingual-cased进行encoding:
from transformers import AutoTokenizer, AutoModelForSequenceClassification , AutoConfig
tokenizer = AutoTokenizer.from_pretrained("./model/bert-base-multilingual-cased")
config = AutoConfig.from_pretrained("./model/bert-base-multilingual-cased")
train_encoding = tokenizer(train_df['原始文本'].to_list()[:], truncation=True, padding=True, max_length=512)
test_encoding = tokenizer(test_df['原始文本'].to_list()[:], truncation=True, padding=True, max_length=512)
num_label = max(train_df['intent_factorize'].to_list()) + 1 # 意图的数目,也即分类的数目
定义Dataset:
from torch.utils.data import Dataset, DataLoader
class BertDataset(Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
# 读取单个样本
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx])
for key, val in self.encodings.items()}
item['labels'] = torch.tensor(int(self.labels[idx]))
return item
def __len__(self):
return len(self.labels)
train_dataset = BertDataset(train_encoding, train_df['intent_factorize'].to_list())
test_dataset = BertDataset(test_encoding, [0] * len(test_df))
# 单个读取到批量读取
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=8, shuffle=False)
初始化模型:
from transformers import AutoModelForSequenceClassification, AdamW
checkpoint ='./model/bert-base-multilingual-cased'
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_label)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 优化方法
optim = AdamW(model.parameters(), lr=1e-5)
total_steps = len(train_loader) * 1
训练函数(这部分几乎没改):
def train():
model.train()
total_train_loss = 0
iter_num = 0
total_iter = len(train_loader)
for batch in train_loader:
# 正向传播
optim.zero_grad()
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs[0]
total_train_loss += loss.item()
# 反向梯度信息
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# 参数更新
optim.step()
# scheduler.step()
iter_num += 1
if(iter_num % 50 == 0):
print("epoth: %d, iter_num: %d, loss: %.4f, %.2f%%" %
(epoch, iter_num, loss.item(), iter_num/total_iter*100))
print("Epoch: %d, Average training loss: %.4f" %
(epoch, total_train_loss/len(train_loader)))
def validation():
model.eval()
total_eval_accuracy = 0
total_eval_loss = 0
for batch in test_dataloader:
with torch.no_grad():
# 正常传播
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(
input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs[0]
logits = outputs[1]
total_eval_loss += loss.item()
logits = logits.detach().cpu().numpy()
label_ids = labels.to('cpu').numpy()
total_eval_accuracy += flat_accuracy(logits, label_ids)
avg_val_accuracy = total_eval_accuracy / len(test_dataloader)
print("Accuracy: %.4f" % (avg_val_accuracy))
print("Average testing loss: %.4f" %
(total_eval_loss/len(test_dataloader)))
print("-------------------------------")
for epoch in range(4):
print("------------Epoch: %d ----------------" % epoch)
train()
validation()
训练过程:


从几个testing loss可以看出,模型有点过拟合了(确实训练数据量不大)。
模型预测:
def prediction():
model.eval()
test_label = []
for batch in test_dataloader:
with torch.no_grad():
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
pred = model(input_ids, attention_mask).logits
test_label += list(pred.argmax(1).data.cpu().numpy())
return test_label
test_predict = prediction()
test_df['意图'] = [intent_ecode[x] for x in test_predict]
test_en = test_df.iloc[:526]
test_ja = test_df.iloc[526:]
结果:
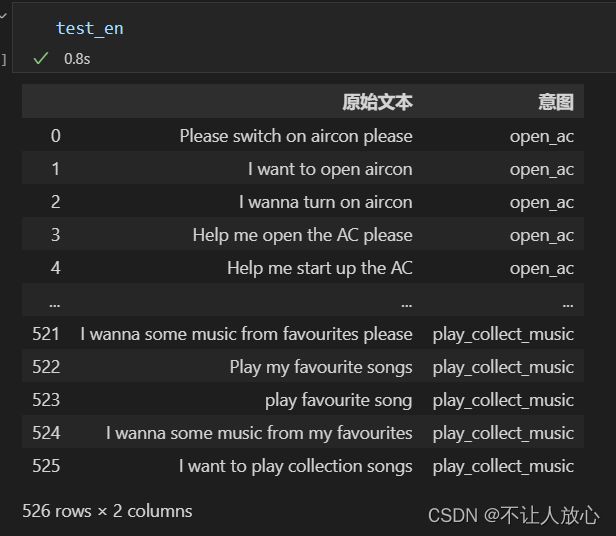

至此算是完成了意图的识别。
参考:
Pandas小知识—map、apply、applymap