基于pynq的数字识别神经网络加速器设计
文章目录
- 基于pynq的数字识别神经网络加速器设计
-
- 软件部分
-
- 1. 全连接神经网络:
- 2. 卷积神经网络搭建:
- 3. 文件格式转换:
- 硬件部分
-
- 1. MNIST的硬件实现思路
- 2. 代码编写与硬件综合
- 3. 硬件平台的搭建
- 软硬件协同部分
-
- 1. 硬件驱动的编写:
- 2. 功能代码编写:
基于pynq的数字识别神经网络加速器设计
本篇为笔者第一次进行神经网络加速器设计的工程开发流程,在此做如下整理。
python环境:python:3.6.13;tensorflow:1.14.0;numpy:1.16.0
硬件环境:vivado2019,vivado_hls2019,pynq-Z1(xc7z020clg400-1)
软件部分
1. 全连接神经网络:

本神经网络主要是进行图像识别,在人眼中图片是带有颜色的,而在电脑中图片的颜色则是使用0-1之间的灰度值表示,最为简单的黑白照片便是使用0表示白色,1表示黑色,中间值表示灰度。彩色图片则是采用红绿蓝(RGB)进行三通道混合表示。传统的数字识别思路为:对于图片中的每个像素点即矩阵中每个位置的点,对应于不同的分类结果(0-9)都一个支持率,之后将图像中对于每个分类的支持率全部加起来,支持率最高的分类就作为这张图片的识别结果,即 y = softmax(wx + b)。(其中softmax对计算结果进行归一化处理方便训练过程中的反向传播计算)
代码部分:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
import tensorflow as tf
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.nn.softmax(tf.matmul(x, W) + b)
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
sess = tf.InteractiveSession()
init = tf.global_variables_initializer()
sess.run(init)
for _ in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, {x: batch_xs, y_: batch_ys})
#print(sess.run(tf.matmul(x, W) + b, {x: mnist.test.images}))
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, {x: mnist.test.images, y_: mnist.test.labels}))
2. 卷积神经网络搭建:
通过卷积和池化不断地对图片信息进行提取,最后在全连接中实现结果的输出。同时卷积神经网络考虑到具有一定的泛化能力(不同数据集上的准确度应该都较高),会加入dropout以防止过拟合,即会在神经网络的训练过程中随机地打开或关闭一些层。

此处为数据存储代码,进过训练以后的神经网络每一层的代码需要存储下来,方便后续硬件端进行计算,这里需要注意的是为了和后面硬件端C语言的函数读取方式一致,需要根据存储数据的维度进行分类,而不是简单读入。
def Record_Tensor(tensor,name):
print ("Recording tensor "+name+" ...")
f = open('./record/'+name+'.dat', 'w')
array=tensor.eval();
#print ("The range: ["+str(np.min(array))+":"+str(np.max(array))+"]")
if(np.size(np.shape(array))==1):
Record_Array1D(array,name,f)
else:
if(np.size(np.shape(array))==2):
Record_Array2D(array,name,f)
else:
if(np.size(np.shape(array))==3):
Record_Array3D(array,name,f)
else:
Record_Array4D(array,name,f)
f.close();
def Record_Array1D(array,name,f):
for i in range(np.shape(array)[0]):
f.write(str(array[i])+"\n");
def Record_Array2D(array,name,f):
for i in range(np.shape(array)[0]):
for j in range(np.shape(array)[1]):
f.write(str(array[i][j])+"\n");
def Record_Array3D(array,name,f):
for i in range(np.shape(array)[0]):
for j in range(np.shape(array)[1]):
for k in range(np.shape(array)[2]):
f.write(str(array[i][j][k])+"\n");
def Record_Array4D(array,name,f):
for i in range(np.shape(array)[0]):
for j in range(np.shape(array)[1]):
for k in range(np.shape(array)[2]):
for l in range(np.shape(array)[3]):
f.write(str(array[i][j][k][l])+"\n");
之后便是基于tensorflow语法进行神经网络搭建。
def weight_variable(shape):
initial = tf.compat.v1.truncated_normal(shape, stddev=0.1);
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2,1], padding='SAME')
#First Convolutional Layer
with tf.name_scope('1st_CNN'):
W_conv1 = weight_variable([3, 3, 1, 16])
b_conv1 = bias_variable([16])
x_image = tf.reshape(x, [-1,28,28,1])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
#Second Convolutional Layer
with tf.name_scope('2rd_CNN'):
W_conv2 = weight_variable([3, 3, 16, 32])
b_conv2 = bias_variable([32])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#Densely Connected Layer
with tf.name_scope('Densely_NN'):
W_fc1 = weight_variable([ 7* 7* 32, 128])
b_fc1 = bias_variable([128])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*32])
h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat , W_fc1) + b_fc1)
#Dropout
with tf.name_scope('Dropout'):
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
#Readout Layer
with tf.name_scope('Softmax'):
W_fc2 = weight_variable([128, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
with tf.name_scope('Loss'):
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
with tf.name_scope('Train'):
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
with tf.name_scope('Accuracy'):
correct_prediction = tf.equal(tf.argmax(y_conv ,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction , "float"))
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("logs/",sess.graph)
tf.initialize_all_variables().run()
for i in range(10000):
batch = mnist.train.next_batch(50);
if i%20 == 0:
train_accuracy = accuracy.eval(feed_dict={x:batch[0], y_: batch[1], keep_prob:1.0});
print("step %d, training accuracy %g"%(i, train_accuracy));
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob:0.5});
print("test accuracy %g"%accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
3. 文件格式转换:
在神经网络中存储的.dat文件并不能被C直接读取,需要进行文件名的转换,此时可以采用如下所示的C代码,也可以使用python中自带的tofile函数实现。
#include 硬件部分
上述神经网络具有较大的计算量,可以通过硬件端的并行化设计使其更为快速地执行。以下部分便是进行硬件端的代码编写。此处设计可以直接通过verilog进行编写,也可以通过hls进行编写,本工程中采用的为hls。
1. MNIST的硬件实现思路
- 第一种思路,采用类似于软件端编写函数的方式,将神经网络中的每一层通过函数的方式进行编写并最终实现整个网络,但是该种方法将导致硬件部分的通用性不足,同时硬件部分的执行效率不高,即并行度不高,第一层进行计算的时候后续层都不进行工作,并且对于较为复杂的网络(层数十层及以上的)设计起来将会非常麻烦,生成的电路也会较为臃肿。
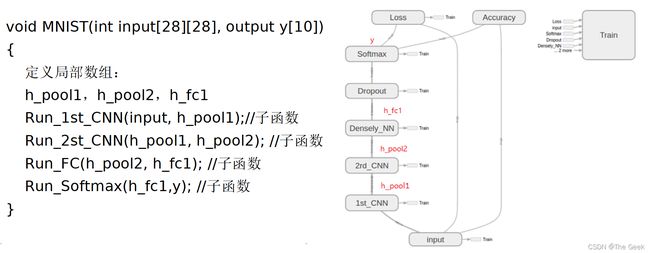
- 第二种思路,提取网络总的特征层,例如该神经网络中主要是conv和pool(还有linear但是由于其为conv的一种特殊形式因此也归为conv),之后在硬件中设计可以通用的conv和pool电路,并采用CPU和存储器对其进行控制和数据存储,将极大地提高设计电路的通用性及其并行度。设计思路如下:
通过CPU对conv和pool进行控制,首先将要读取的图片存储到存储器中,之后CPU控制conv进行第一层卷积运算,并将计算结果存储到存储器中;该步完成后CPU按照神经网络设计控制pool读取上一次conv的计算结果,并将计算得到的结果再次存入存储器中;此后,只需重复上述步骤直至运算全部结束。
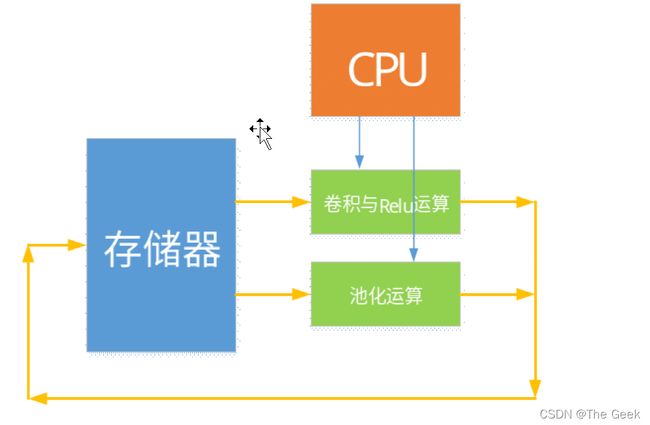
C语言实现conv和pool部分的思路:
conv部分:对于卷积部分而言,因为是要设计通用的电路,所以需要确定需要传入的参数,其中有win和hin分别表示输入图层的宽度和高度,x_stride和y_stride用来表示卷积核在X方向和Y方向移动的步幅,Cin和Cout则表示输入的通道数和输出的通道数,kx和ky用于表示卷积核的大小,wout和hout则用来表示输出图层的大小,由于可以算出所以不再进行赘述,除此之外还需要指定Conv是否需要进行padding,以及之后的relu运算,同时还需要必要的输入(其中w表示conv_core中的具体参数)和输出(如红框中所示)。Pool部分则与其基本相同。
注1:本次使用的网络较为简单同时采用的MINIST数据集也较小,所以并没有对数据进行量化操作。
注2:此处出现的ap_uint为hls中特定的数据类型使用时需要引用表示任意精度的整数数据类型,而此处的Dtype_f和Dtype_w则并非hls中固有的数据类型而是笔者typedef重新定义的名称,只是表示float而已

2. 代码编写与硬件综合
之后需要做的便是进行hsl编写。
conv部分的代码如下:
#include "conv_core.h"
//Feature: [H][W][C]
//kernel: [Ky][Kx][CHin][CHout]
void Conv(ap_uint<16> CHin,ap_uint<16> Hin,ap_uint<16> Win,ap_uint<16> CHout,
ap_uint<8> Kx,ap_uint<8> Ky,ap_uint<8> Sx,ap_uint<8> Sy,ap_uint<1> mode,ap_uint<1> relu_en,
Dtype_f feature_in[],Dtype_w W[],Dtype_w bias[],Dtype_f feature_out[]
)//mode: 0:VALID, 1:SAME
{
ap_uint<8> pad_x,pad_y;
if(mode==0)
{
pad_x=0;pad_y=0;
}
else
{
pad_x=(Kx-1)/2;pad_y=(Ky-1)/2;
}
ap_uint<16> Hout,Wout;
Wout=(Win+2*pad_x-Kx)/Sx+1;
Hout=(Hin+2*pad_y-Ky)/Sy+1;
for(int cout=0;cout<CHout;cout++)
for(int i=0;i<Hout;i++)
for(int j=0;j<Wout;j++)
{
Dtype_acc sum=0;
for(int ii=0;ii<Ky;ii++)
for(int jj=0;jj<Kx;jj++)
{
ap_int<16> h=i*Sy-pad_y+ii;
ap_int<16> w=j*Sx-pad_x+jj;
if(h>=0 && w>=0 && h<Hin && w<Win)
{
for(int cin=0;cin<CHin;cin++)
{
Dtype_mul tp=feature_in[h*CHin*Win+w*CHin+cin]*W[ii*Kx*CHin*CHout+jj*CHin*CHout+cin*CHout+cout];
sum+=tp;
}
}
}
sum+=bias[cout];
if(relu_en & sum<0)
sum=0;
feature_out[i*Wout*CHout+j*CHout+cout]=sum;
}
}
pool部分的代码:
#include "pool_core.h"
#define max(a,b) ((a>b)?a:b)
#define min(a,b) ((a>b)?b:a)
void Pool(ap_uint<16> CHin,ap_uint<16> Hin,ap_uint<16> Win,
ap_uint<8> Kx,ap_uint<8> Ky,ap_uint<2> mode,
Dtype_f feature_in[],Dtype_f feature_out[]
)//mode: 0:MEAN, 1:MIN, 2:MAX
{
ap_uint<16> Hout,Wout;
Wout=Win/Kx;
Hout=Hin/Ky;
for(int c=0;c<CHin;c++)
for(int i=0;i<Hout;i++)
for(int j=0;j<Wout;j++)
{
Dtype_f sum;
if(mode==0)
sum=0;
else
if(mode==1)
sum=99999999999999999;
else
sum=-99999999999999999;
for(int ii=0;ii<Ky;ii++)
for(int jj=0;jj<Kx;jj++)
{
ap_int<16> h=i*Ky+ii;
ap_int<16> w=j*Kx+jj;
switch(mode)
{
case 0:{sum+=feature_in[h*CHin*Win+w*CHin+c];break;}
case 1:{sum=min(sum,feature_in[h*CHin*Win+w*CHin+c]);break;}
case 2:{sum=max(sum,feature_in[h*CHin*Win+w*CHin+c]);break;}
default:break;
}
}
if(mode==0)
sum=sum/(Kx*Ky);
feature_out[i*Wout*CHin+j*CHin+c]=sum;
}
}
此时其实可以直接综合,vivado_hls将根据已有的代码生成电路,不过该电路是由vivado_hls自己生成因此性能上可能并不能达到预期效果,此时便需要添加约束;
以下代码将以一个简单的4x4矩阵为例展示如何给已有的C语言代码添加约束:
- 打开Directive界面:因为vivado_hls的界面是按照上一次默认的情况打开的,所以一些用户的界面打开后可能并不会直接出现Drictive的界面,此时便需要在window中点击show view便可以打开Directive界面。
- 将for循环展开:此处的显示为linux系统中的小bug程序界面随着系统界面颜色改变,导致显示字符出错,不过并不影响我们的操作,此时我们在Directive框中选择UNROLL表示将for循环展开,Destination中选择source文件(表示约束将直接添加到原文件中)。
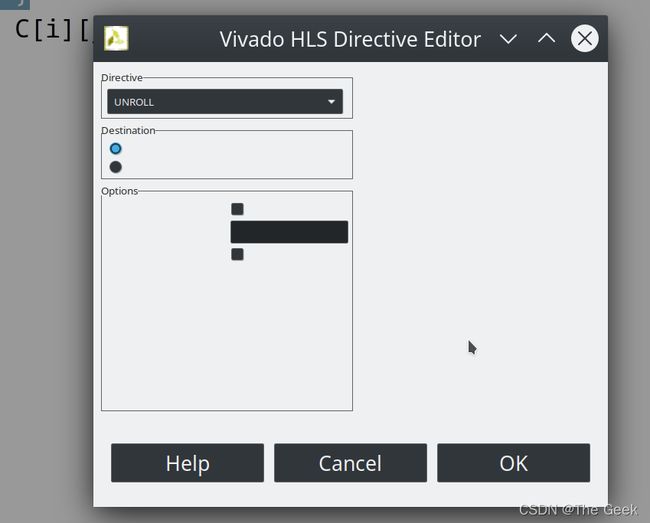
此时对比之前综合结果发现,所用资源变少,电路的性能提高(上图为原来结果,下图为添加约束后的结果)。


在此之后,根据一般思维便会认为如果把三重循环全部展开,电路的运算速度将变得更快,但是经过笔者尝试发现电路综合后的结果变化并不大并不会出现之前发生的巨大变化。此时,根据硬件设计的思路分析便可以知道,限制电路运行速度的并不仅是电路的运算速度,还有数据的传输速度,此处并没有改变电路的传输速度只是一味的增加数据的运算速度电路的整体速度并不会有太大提升。 - 对函数参数进行约束(约束电路的输入输出端口)Directive选择ARRAY_RESHAPE维度上选择dim = 1(A,C同理)。
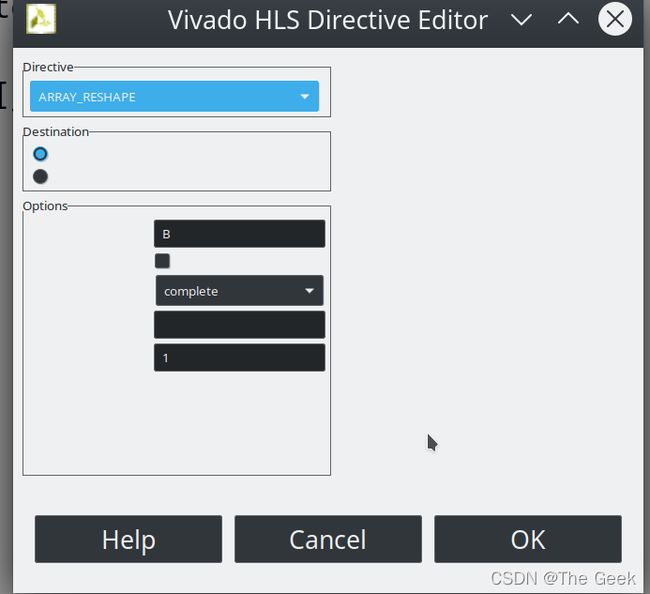
但是此时会发现一个更为神奇的现象便是,电路的性能优化仍然不高:

此时便需要考虑到一个更为重要的问题便是solution中我们添加的时钟周期制约。
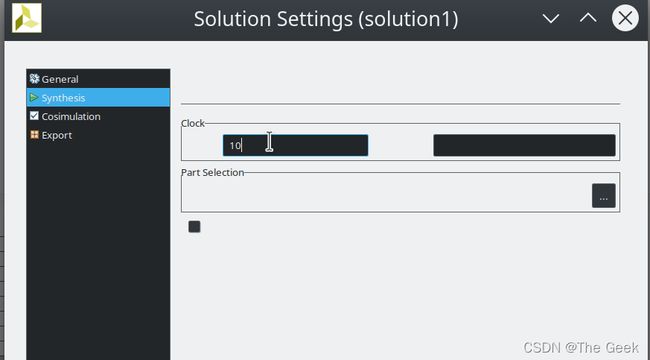
观察此处可以发现clock采用的默认值10,电路中的延迟将导致电路无法在如此高的频率下按照理论上的结果单周期完成(因此此时实际上已将将三重for循环和所有的输入全部展开,理论上应该是变成了一个组合逻辑电路可以单周期完成)。因此修改此处的值,将其变为更大的值1000在进行仿真。此时可以发现电路速率按照理论减少了近乎100倍,如果再增大时钟周期便可以达到理论上的单周期电路。

- 函数名约束(较为重要)
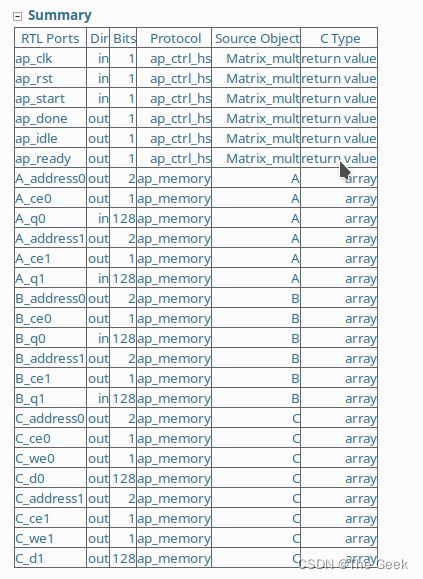
下图为不添加约束时,生成的结果在该结果中电路由一个ap_start和ap_done信号控制其开始和结束,ap_idle和ap_ready表示电路的工作状态,ap_clk和ap_rst表示电路的控制时钟和复位信号。电路以这样的方式被控制。(此时并不是完全不能被CPU控制,而是可以采用GPIO对电路进行控制,此方法并不推荐)。
但是根据我们之前的设计思路,我们希望的是电路被CPU所控制,因此需要采用AXI总线控制。
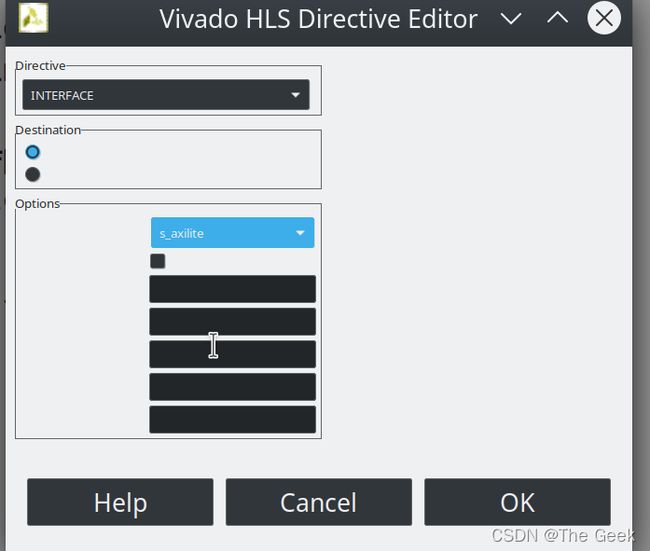
具体的操作流程如下:Directive选择INTERFACE,Options选择s_axilite表示生成电路收到CPU驱动。
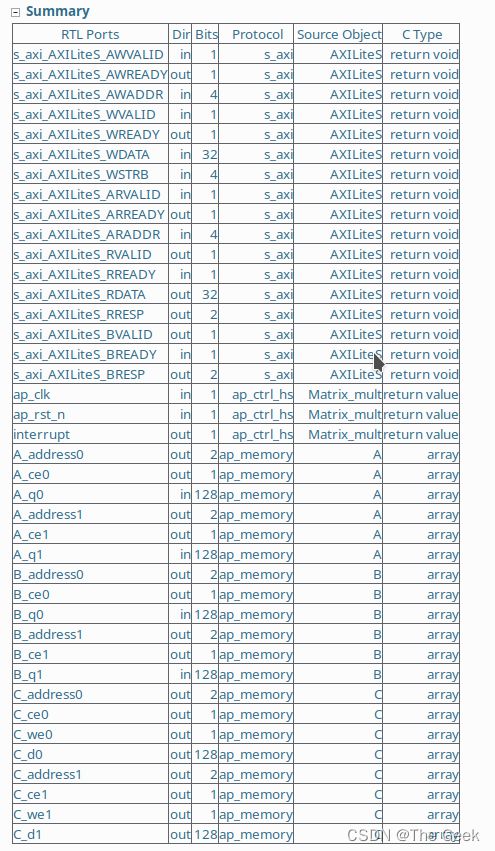
此时电路的综合结果为:如需了解AXI总线的具体协议可查看相关资料。
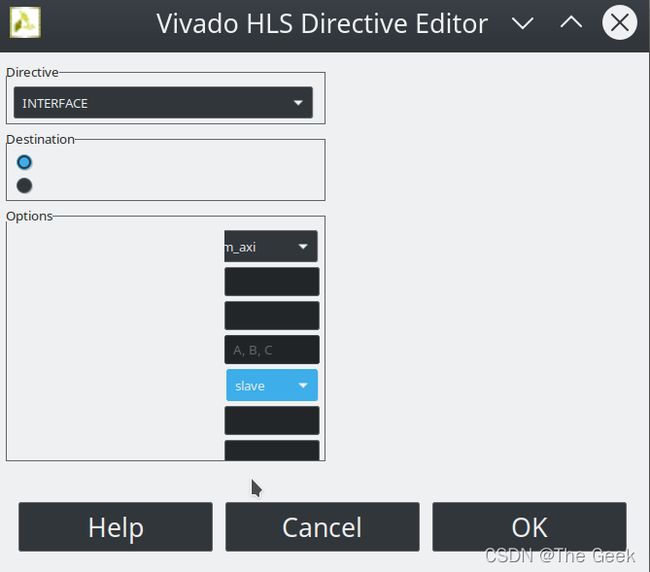
此处除了对函数名进行约束以外,因为要将AXI总线接到CPU上,还需要对函数的参数也就是电路的输入输出结果进行约束。具体操作如下图所示:(此处自己尝试是出现了一个较为神奇的bug,选择m_axi时会报错,但是选择s_axi时并不会报错,但此处正确情况下应该是按照下图所示选择,同时如果采用手动代码输入也不会报错)。
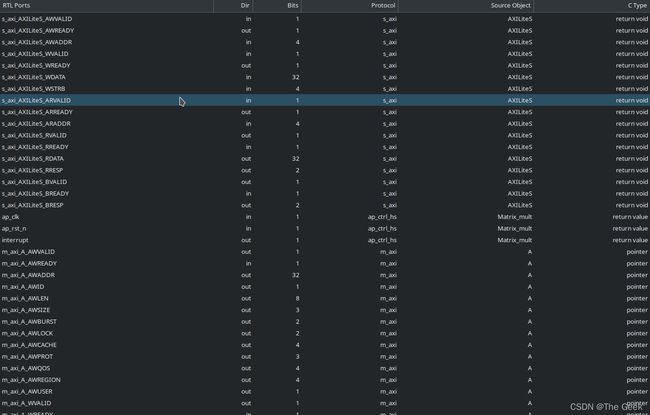
此时综合得出的AXI不仅包含s_axi也包含m_axi。
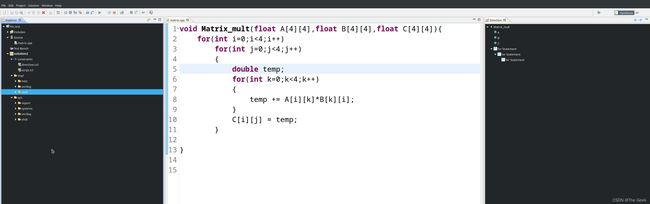
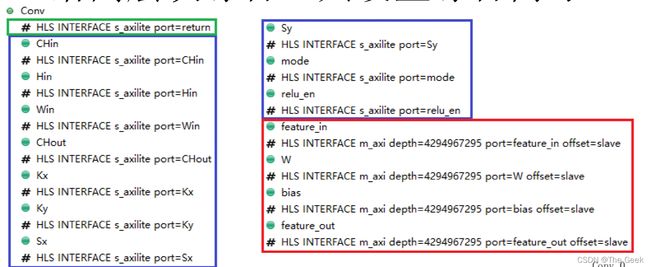
- 进过如上操作后的代码:其中因为A,B,C分别对应于总线接口,所以采用m_axi,主要是这些需要其主动地去读入或者写入数据。(对于conv和pool而言,还需要加入depth参数这个参数对于电路并不会产生任何影响给一个较大的值即可,表示为HLS INTERFACE m_axi depth=4759000 port=C)
void Matrix_mult(float A[4][4],float B[4][4],float C[4][4]){
#pragma HLS INTERFACE s_axilite port=return
#pragma HLS INTERFACE m_axi port=C
#pragma HLS INTERFACE m_axi port=B
#pragma HLS INTERFACE m_axi port=A
#pragma HLS INTERFACE s_axilite port=return
for(int i=0;i<4;i++){
#pragma HLS UNROLL
for(int j=0;j<4;j++)
{
#pragma HLS UNROLL
double temp;
for(int k=0;k<4;k++)
{
#pragma HLS UNROLL
temp += A[i][k]*B[k][i];
}
C[i][j] = temp;
}
}
};
conv部分的约束
3. 硬件平台的搭建
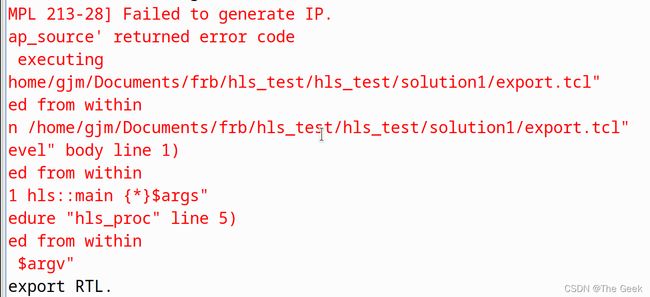
- 生成ip核操作如下:点击橙色十字便会可进行ip核的生成,此时要注意的是进入2022年以后vivado_hls产生一个bug,需要将系统时钟调到小于或者等于2021年才可以成功生成ip核。否则将出现如下图所示的bug;

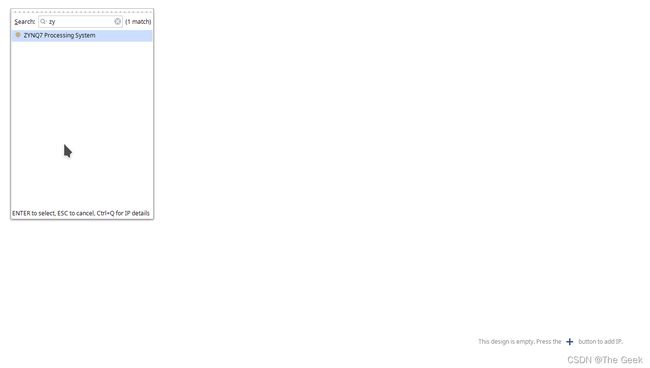
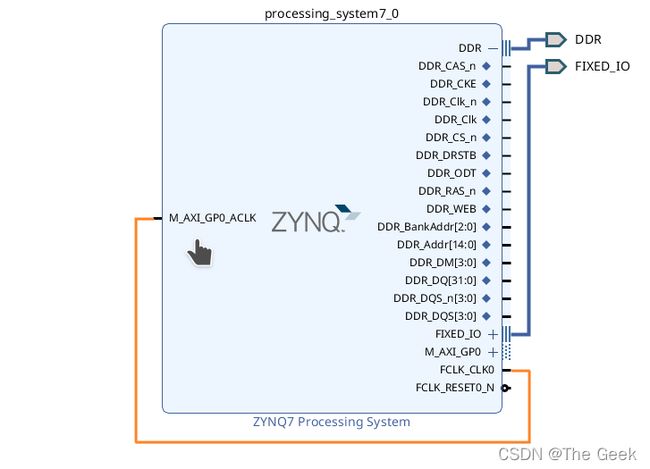
- 新建工程后点击Creat Block Design,之后按照下图导入RAM部分,之后点击run block automatic,此时将自动生成DDR接口。并按照下图进行连线,此时可以点击工作台上方的√查看设计是否有问题。
- 添加之前写入到ip,不同版本的vivado操作并不一致,此处采用2019.1版本的界面进行介绍。
点击setting,点击IP>Repository将之前得到的IP核路径添加进去。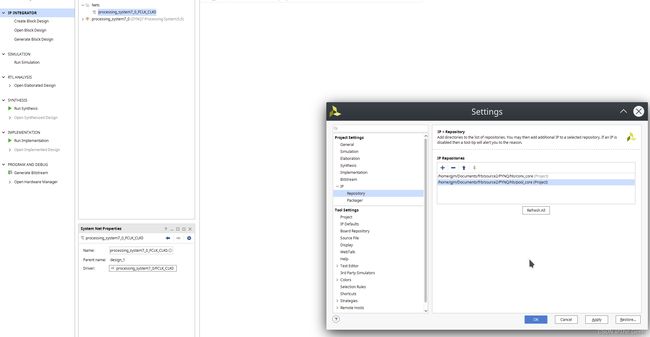
之后需要做的就是通过==+进行ip核的添加即可。
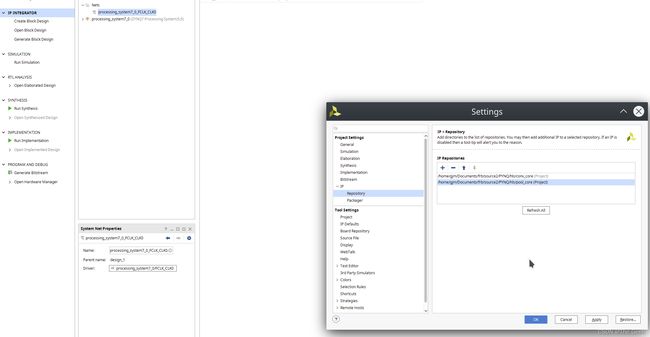
之后需要做的便是点击run block automatic==,将conv和pool的slave端接到ram上。
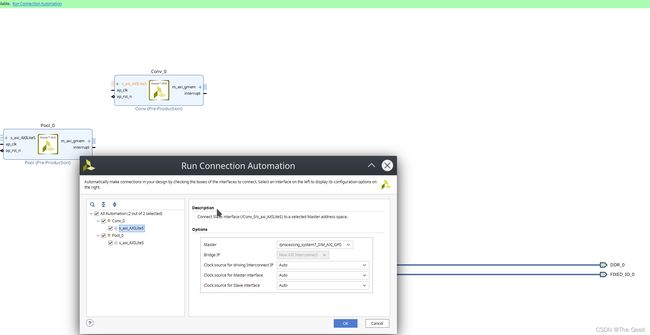
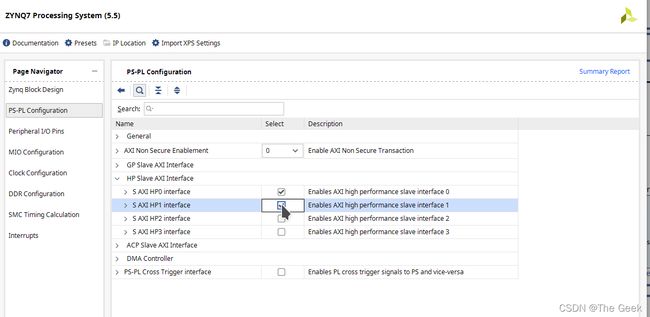
此时已经完成了conv和pool被控制端口的连接,但是还需要将master接口连接到ram上,此时双击ram,便会弹出如下框图:此时可以选择一个(HP0)也可以选择两个(HP0和HP1)。
注:这一步不能和之前slave端口链接一样通过run block automatic自动完成,因为ram的slave端口是不显示,需要自己手动调节显示。
- 点击工作台上的√,验证电路是否有误。如显示结果正确则完成电路连接,如下图所示:
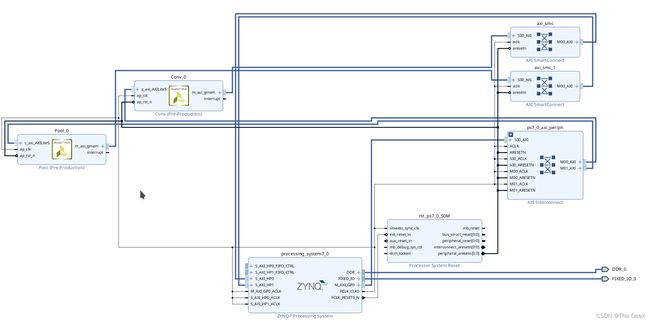
- 生成可以传输到板子的比特流文件:点击Source->Desing_1->Create HDL Wrapper;之后再点击Desing_1->Generate Output Products-> ;最后点击Generate Bitstream便可以生成比特流文件了。(注意该比特流文件存储的位置,位于base->base.runs->impl_1,此处使用的是笔者电脑上的文件命名)同时还需要点击file->export->export block design,生成一个.tcl结尾的文件,之后还需要将这两个文件拷入(此时.tcl和.bit文件都需要拥有同样的命名)到pynq开发板上,如果可以通过网线连接就可以通过网线传输;如果不能通过网线传输就可以采用SD卡进行传输。
软硬件协同部分
此处需要基本的pynq-z1的开发知识,如果不了解可以查看官方文档。
1. 硬件驱动的编写:
pynq的硬件驱动可以由python编写,对于没有任何pynq开发经验的人而言可以先试着调用官方ip进行LED灯点亮来进行熟悉,代码如下:
from pynq import Overlay
import numpy as np
ol = Overlay("testAAA.bit")
# ol.ip_dict 可以用查询导入电路中用到的ip核
ol.download()
gpio = ol.axi_gpio_0
gpio.write(0,15)
gpio.write(0,4)
# 神经网络中设计大量的数组运算,但是虚拟空间连续的数组地址,在真实的物理空间并不一定是连续的,
# 所以这里需要通过Xlnk,来创建数组,xlnk对于pynq就类似于numpy之于python。
from pynq import Xlnk
xlnk = Xlnk()
input_buffer=xlnk.cma_array(shape=(4000,),cacheable=0,dtype=np.int32);
# 通过这种方式在物理空间里开出来的数组地址都是连续的,cacheable表示缓冲也就是说对硬件写数据是否直接写入到ram中。
input_buffer.physical_address
熟悉了基本的pynq-ip调用过程以后就可以进行CPU驱动程序的开发了。
其实经过hls生成ip之后也会相应的生成一份硬件驱动,保存在以下目录中Documents/frb/source2/PYNQ/hls/pool_core/solution1/impl/ip/drivers/Pool_v1_0/src$ (同样这里是以笔者的文件为例)。但是这份驱动对于我们而言并不是十分适用,主要原因在于这份驱动文件是由C语言编写而成,而我们需要的则是一份python版本的代码,因此需要自己根据C语言生成的文件进行转义变成python文件。
以下展示pool部分的驱动头文件:
#ifndef __linux__
#include "xil_types.h"
#include "xil_assert.h"
#include "xstatus.h"
#include "xil_io.h"
#else
#include 以上展示的主要是头文件,但是实际要转义的文件为xpool_hw.h里,主要代码如下所示:
此处告知pool中的各个参数分别存储在哪些寄存器中。
#define XPOOL_AXILITES_ADDR_AP_CTRL 0x00
#define XPOOL_AXILITES_ADDR_GIE 0x04
#define XPOOL_AXILITES_ADDR_IER 0x08
#define XPOOL_AXILITES_ADDR_ISR 0x0c
#define XPOOL_AXILITES_ADDR_CHIN_V_DATA 0x10
#define XPOOL_AXILITES_BITS_CHIN_V_DATA 16
#define XPOOL_AXILITES_ADDR_HIN_V_DATA 0x18
#define XPOOL_AXILITES_BITS_HIN_V_DATA 16
#define XPOOL_AXILITES_ADDR_WIN_V_DATA 0x20
#define XPOOL_AXILITES_BITS_WIN_V_DATA 16
#define XPOOL_AXILITES_ADDR_KX_V_DATA 0x28
#define XPOOL_AXILITES_BITS_KX_V_DATA 8
#define XPOOL_AXILITES_ADDR_KY_V_DATA 0x30
#define XPOOL_AXILITES_BITS_KY_V_DATA 8
#define XPOOL_AXILITES_ADDR_MODE_V_DATA 0x38
#define XPOOL_AXILITES_BITS_MODE_V_DATA 2
#define XPOOL_AXILITES_ADDR_FEATURE_IN_DATA 0x40
#define XPOOL_AXILITES_BITS_FEATURE_IN_DATA 32
#define XPOOL_AXILITES_ADDR_FEATURE_OUT_DATA 0x48
#define XPOOL_AXILITES_BITS_FEATURE_OUT_DATA 32
转义的python代码:
注:这一部分还需要参看xpool.c文件,查看原C语言中的函数是如何进行读写操作的
def RunPool(pool,Kx,Ky,mode,feature_in,feature_out):
#这里[0],[1]分别表示图层大小,[2]表示channel数;
pool.write(0x10,feature_in.shape[2]);
pool.write(0x18,feature_in.shape[0]);
pool.write(0x20,feature_in.shape[1]);
pool.write(0x28,Kx);
pool.write(0x30,Ky);
pool.write(0x38,mode);
pool.write(0x40,feature_in.physical_address);
pool.write(0x48,feature_out.physical_address);
pool.write(0, (pool.read(0)&0x80)|0x01 );
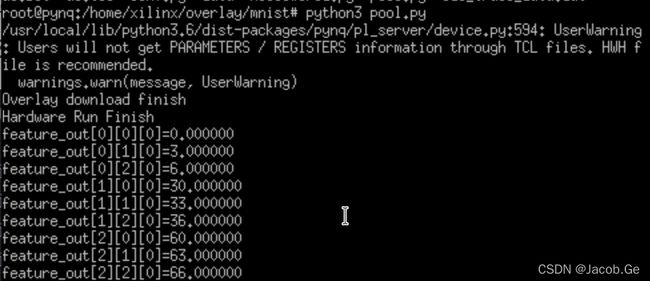
之后就可以在pynq开发板上运行编写好的驱动文件,显示效果如下:
注:运行是需要采用root账户
2. 功能代码编写:
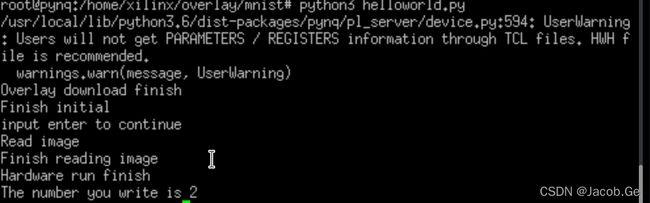
此时便只剩下最后一步,即根据Lenet-5模型编写python代码,并调用之前已经编写的pool和conv部分代码,搭建最后的功能电路。并将之前几页tensorflow搭建的网络的训练参数导入。
演示效果如下:

如上图所示是一张数字2;
之后运行编写好的代码:可以正确识别出数字2,至此工程全部结束。