Incorporating Convolution Designs into Visual Transformers阅读笔记
Incorporating Convolution Designs into Visual Transformers阅读笔记
Abstract
纯Transformer架构需要大量的训练数据或者额外的监督,才能获得与CNN相当的性能。为克服限制,提出一种新的Convolution-enhanced image Transformer(CeiT)
它结合了神经网络在提取低层特征、增强局部性方面的优势和变换器在建立长距离依赖方面的优势。对原变形器做了三点修改:
- 设计了一个Image-to-Tokens(I2T)模块。从CNN生成的低层特征中生成patch,而不是从原始图像直接切分patch。
- 每一个encoder模块中的前馈网络被局部增强的前馈层替代(Locally-enhanced Feed-Forward(LeFF)),该层促进空间维度中相邻标记之间的相关性。
- Layer-wise Class token Attention(LCA)
CeiT有效,且泛化能力好,同时表现出更好的收敛性,迭代次数减少了3倍,显著降低了训练成本。
1 Introduction
Transformer能够称为NLP的标准,因为能够模拟远程依赖和并行训练。
ViT是纯Transformer用于图像分类,缺点是严重依赖于JFT-300M[32]大型数据集,限制了在计算资源或者标记数据有限的情况下的应用。
[32]Chen Sun, Abhinav Shrivastava, Saurabh Singh, and Abhinav Gupta. Revisiting unreasonable effectiveness of data in deep learning era. In ICCV, pages 843–852. IEEE Computer Society, 2017. 1
为了减轻对大量数据的依赖,DeiT引入CNN模型作为teacher网络,并应用只是蒸馏[13]来改进ViT的student模型。
Geoffrey E. Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling the knowledge in a neural network. CoRR, abs/1503.02531, 2015. 1
transformer缺少CNN固有的inductive biases,因此在数据不足的情况下,不能很好的学习。
回顾卷积,卷积的主要特性就是平移不变性和局部性[21, 30],
平移不变性与权重共享机制相关,该机制可以捕获视觉任务中的几何和拓扑信息[22]。
为了解决这些问题,我们设计了一个卷积增强的图像转换器(CeiT),
主要贡献:
- 设计了新的Vision Transformer架构,结合了CNN在提取低层特征、增强局部性方面的优势,以及Transformer在简历远程依赖方面的优势。
- 在ImageNet上表明,与最先进的CNN相比,CeiT的有效性和泛化能力,不需要大量数据和二外的CNN teacher完了过。
- Transformer具有更好的收敛性,迭代次数少量三倍,显著降低训练成本。
2 Related Work
Transformer in Vision.
iGPT [6]首先引入变压器来自动回归预测像素,并获得预先训练的模型,而不需要结合2D图像内容的知识。缺点,智能在小数据集上验证性能。
ViT [9]成功地使标准变压器可扩展用于图像分类。缺点,智能在大数据集上训练。
DeiT通过模型蒸馏模仿CNN模型,在ImageNet上即可训练。
还有一些其他任务用于目标检测,分割,和图像增强、视频处理。
Hybrid Models of Convolution and Self-attention.
Non-local network[38]通过将non-local 层插入到ResNet的最后几个block中,提高了视频识别和实例分割的性能。
CCNet[17]在分割网路的顶部添加了一个注意力模块。SASA,SANet和Axial-SASA提出用self-attention模块代替所有卷积层,形成 一个独立的self-attention网络。
DETR使用CNN主干之外的Transformer模块用来拜托区域吸纳之和简单的非极大值抑制。
CeiT的蒸馏CNNs,更复杂。
3 Methodology
CeiT基于ViT。
3.1 Revisiting Vision Transformer
ViT的基本组件,包括:tokenization, encoder blocks, multi-head self-attention layers, and feed-forward network layers
Tokenization. Transformer的输入是一系列token embeddings。为了处理二维图像,ViT分解成一些列patches。同时添加一个额外的类标记作为图像的表示,从而得到 x t ∈ R ( N + 1 ) × C x_t \in R^{(N+1)\times C} xt∈R(N+1)×C, 其中 N = H W P 2 N=\frac {HW} {P^2} N=P2HW为patch的数量。
ViT以 16 × 16 16\times 16 16×16的patch大小分割图像,但是带来的局限性,1,难以捕捉图像中的低层信息;2,大型内核被过度参数化,难以后话,需要更多的训练样本。
Encoder blocks. ViT由堆叠编码器构成,每个编码器有两个子层,MSA和FFN。每个子层使用残差连接,最后是归一化层。
MSA. self-attention(SA)模块。MSA是SA的扩展,将qkv拆分成h次,并行执行attention能力。
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T C ) V Attention(Q,K,V)=softmax(\frac {QK^T}{\sqrt C})V Attention(Q,K,V)=softmax(CQKT)V
FFN. 执行逐点操作。
F F N ( x ) = σ ( x W 1 + b 1 ) W 2 + b 2 FFN(x)=\sigma (xW_1 + b_1)W_2 + b_2 FFN(x)=σ(xW1+b1)W2+b2
σ \sigma σ使用的是GELU非线性激活。
3.2 Image-to-Tokens with Low-level Features
I2T
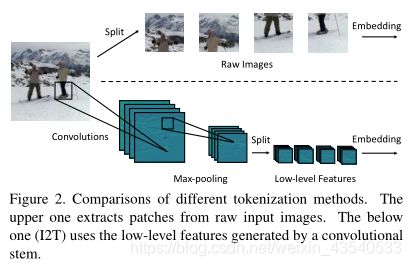
I2T module是一个轻量级的主干,由一层卷积层和一个最大池化层组成。消融实验表明,卷积层之后的BN层有利于训练过程。
x ′ = I 2 T ( x ) = M a x P o o l ( B N ( C o n v ( x ) ) ) x' = I2T(x)=MaxPool(BN(Conv(x))) x′=I2T(x)=MaxPool(BN(Conv(x)))
3.3 Locally-Enhanced Feed-Forward Network
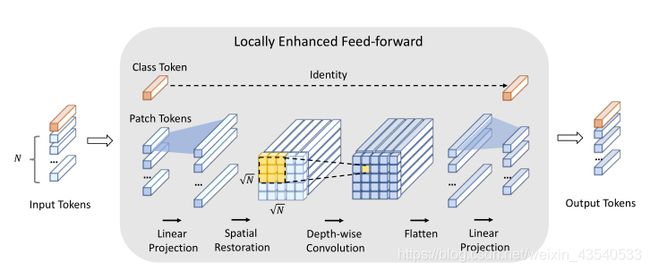
为了结合神经网络提取局部信息的优势和变压器建立远程依赖的能力,我们提出了一个局部增强前馈网络层。
3.4 Layer-wise Class-Token Attention
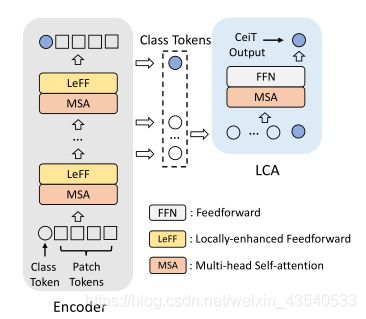
为了跨层汇集特征,设计了一个分层的类标记关注模块。
3.5 Computational Complexity Analysis
4 Experiments
4.1 Experimental Settings
Network Architectures.
I2T的卷积核大小为7,stride为2,channels为32,加入BN层进行稳定训练。然后跟一个卷积核为3,stride为2的max-pooling层,得到比输入图像小4倍的特征图。与ViT的 16 × 16 16\times 16 16×16相比,本文使用 4 × 4 4\times4 4×4的patch来生成一系列tokens。
Implementation Details. GPU为NVIDIA Tesla V100。采用和DeiT相同的训练策略。Input size为 224 × 224 224\times224 224×224,epochs为300,batch size为1024, 学习率为 1 e − 3 1e^{-3} 1e−3 LR scheduler 为cosine warmup epoch 为5, weight decay 为0.05
**Datasets. ** 使用ImageNet数据集,和其他7类不同数据集。
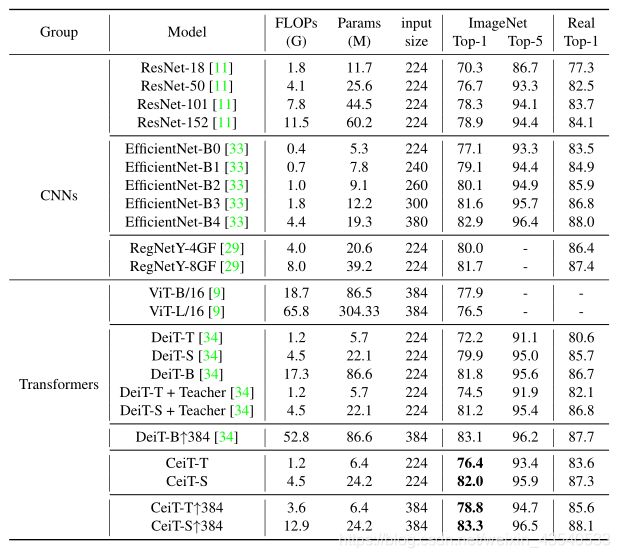
4.2 Results on ImageNet
4.3 Transfer Learning
为证明泛化能力,在7个下游基准中进行了迁移学习实验。
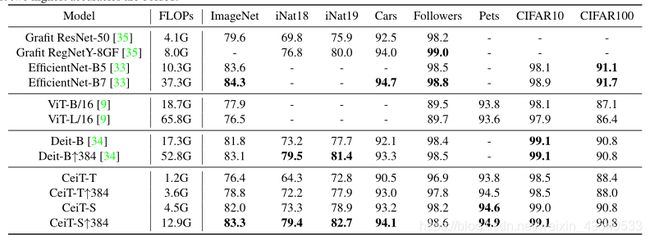
4.4 Ablation Studies
Different types of I2T module.
I2T中的影响因素包括卷积的核大小、卷积的步长、最大池的存在和批处理层。
最大池层和批处理层都有利于训练。
Different types of LeFF module.
Effectiveness of LCA
4.5 Fast Convergence
训练时间节省3倍。
5 Conclusion
提出CeiT架构。