1024程序员节 | 我在自研数据库,我为技术代言

随着互联网的发展,“程序员”这个名字逐渐为人们所关注到,其所代表的标签印象也变得更加多样 —— 改变世界?Debug专业户?格子衫代言人?……事实上,有那么一群人,比如腾讯数据库工程师,他们将自己定义为“数字的工匠”,初心如一地用代码创造产品、解决问题,为国产数据库发展助力。而对于我们来说,有他们的努力,数字世界也不再是虚无缥缈的数据,而像冰山盘亘在海面一样,深邃而沉稳。
在“1024”程序员节到来之际,我们推出本期特别分享,邀请腾讯6位数据库技术工程师,讲述了他们对代码技术的理解。

“我是腾讯云数据库技术负责人雷海林,2007年大学毕业加入腾讯,负责过计费、支付底层各大模块的开发,包括分布式Cache系统‘Hold(厚德)’等,以及腾讯金融级安全可控分布式数据库研发。我在腾讯,为数据库国产化发展助力。”

“我是腾讯云数据库高级工程师赖铮,2018年加入腾讯,曾经在MySQL数据库官方团队工作,现在负责腾讯云数据库内核开发。我在腾讯,为数据库国产化发展助力。”

“我是腾讯IEG数据库专家工程师陈福荣,2011年加入腾讯,曾经做过Tendb Cluster和Tendis项目,现在腾讯IEGCROS团队负责腾讯游戏云存储开发。我在腾讯,为数据库国产化发展助力。”

“我是腾讯云数据库高级工程师陈再妮,2019年加入腾讯,从事数据多活、Oracle兼容、读写分离等项目开发。我在腾讯,为数据库国产化发展助力。”

“我是腾讯云数据库工程师张风啸,2019年加入腾讯,从事多源同步和数据校验模块的设计与开发。我在腾讯,为国产数据库发展助力。”

“我是腾讯云数据库高级工程师陈松威,2018年加入腾讯,从事云数据库内核研发,开发过的功能包括企业级列加密函数、数据恢复工具、异步审计,数据预热等。我在腾讯,为国产数据库发展助力。”
你为什么从事数据库底层研发
雷海林:
个人兴趣更喜欢与计算机打交道,通过code去解决问题;而一般来说,越是偏低层的系统软件,技术挑战也越大,而数据库领域在性能优化、高可用、扩展性、数据一致性等方面一直有无限的可能,技术上可以做各种尝试、各种创新探索,同时驱动更广泛的技术生态创新突破。
赖铮:
数据库系统作为基础的系统软件,是很多应用系统的核心。它涉及到的知识领域非常广泛,包括操作系统、事务系统、并发处理等等,可以说是软件领域的明珠、人类智慧的结晶。能从事这个领域的研发工作,会有一种使命感,同时,如果做出了一点点成绩,也会给自己带来巨大的满足感。尤其是在数据爆炸的时代,对于数据的存储和管理技术越来越成为计算机领域的关键性技术,能在这样快速变化的大潮中奋发搏击,也是一件幸事。
陈福荣:
应该说比较幸运,研究生阶段就是从事数据库方面的学习和研究,第一份工作是跟着导师做国产数据库,积累了一些经验,后来加入了腾讯游戏的DBA团队。所以,从学生到现在超过10年了,一直都是做数据库相关的开发工作。也很庆幸一直做着自己比较喜欢的工作。
陈再妮:
最早在业务系统的后台开发时,底层数据存储使用到了数据库,发现很多大段的业务逻辑代码,一条SQL就可以搞定,这使得我对数据库产生了浓厚的兴趣,开始进入这个领域。进入后发现数据库底层确实是复杂的东西,做起来特别有挑战,但一旦完成后也会让我产生更多的成就感,这也驱动了我一直从事下去。
张风啸:
才开始接触技术是写Java Web的,参与了校内小项目的开发,做了有一年多。在开始觉得只是用框架,不够深入有点无聊。后来通过社区接触了很多之前没接触的新技术,对一些基础组件的底层实现产生了比较浓厚的兴趣。后来进入腾讯实习期间,调研了解了一些新的DB技术,从而对数据库的兴趣更加浓烈。后来面试的时候也和面试官表达了想去做数据库的意愿,没想到真的遇上了。
陈松威:
数据库是三大系统软件之一,涉及到的模块众多,是非常有深度、值得探索的领域。能从事数据库底层研发,是一件非常荣幸的事情。特别是在我们团队,有多位在数据库内核领域深耕多年的技术大牛,他们总能知无不言言无不尽地帮助我,使我快速成长,这我更加坚信从事数据库内核研发的选择是正确的。
作为程序员,你做过觉得罪有成就感的三个业务或者事情是什么?
雷海林:
我觉得最有成就感的事情是技术上比较追求完美地做出一些组件或者产品,解决难以解决的BUG,或者性能上的每一次超越和升级:
a) 比如封装zkapi,能让大家用起来更方便,屏蔽很难处理的一些细节问题,实现一个基本无锁化的内存池组件,解决偶发的毛刺问题等等; b) 比如花一个星期以上的时间,构造数十亿的请求去解决某个难以重现的数据一致性BUG; c) 负责腾讯国产分布式数据库的研发,支撑各行业对分布式数据库的需求。
赖铮:
a)在InnoDB存储引擎中实现了透明加密功能; b)在InnoDB存储引擎中实现了基于R树的空间索引; c)通过优化热点更新大幅度提升了秒杀场景下的系统性能。

陈福荣:
作为程序员,最有成就感的事情应该就是做的一些核心功能或者优化,能够真正在业务上落地并且发挥作用。举三个例子:
第一个是在数据库上增加了在线加字段的能力。这应该是我个人加入腾讯做的第一个比较大的功能点,需要对Innodb底层存储格式进行优化,当时做的时候技术上挑战很大,但完成后,它对业务减少停服时间的收益也特别明显。当第一个Demo做出来并且在第一个业务(当年应该是斗战神)上线时,还是很有成就感的。
第二个是研发互娱的分布式解决方案TenDBCluster,解决了原来数据库无法水平扩展的问题,顺应了手游时代的爆发。大约在2015年,第一款业务从单机数据库切换到TenDB Cluster时,我跟另外一个同事一直坚守了凌晨两三点,最终业务顺利切换,虽然比较晚了,但心里还是感到非常兴奋。
第三个是TendisX冷热混合存储在腾讯云商业化,通过腾讯云对外开放。
陈再妮:
a)数据库多中心多活模块研发:保障企业数据库的高可用,为客户业务系统实现7×24小时不间断高效平稳运行发挥了重要作用; b)Oracle兼容特性研发,助力Oracle兼容版本的数据库产品功能顺利上线,极大提升了腾讯云数据库助力行业技术国产化的优势; c)完成腾讯自研分布式HTAP国产数据库开源。
张风啸:
a)一个是实现了数据库迁移中异构数据迁移和同步的数据校验模块,解决了据迁移中的一致性校验问题。 b)进一步完善了数据库异构多源同步的功能,提升了产品的易用性。 c)最关键的是大学期间教女孩子写计算机的大作业,最后变成了女朋友。
陈松威:
a)原创了业界唯一的数据恢复工具,能够从损坏的表文件中恢复用户数据,保障数据安全。 b)设计并实现了异步审计,将审计性能影响降至3%,在业界遥遥领先。 c)原创了数据库主从切换前,备机的数据预热功能。
你认为对程序员来说最重要的非技术因素是什么?
雷海林:
寻根问底的精神。比如程序出现了某个罕见的异常现象,那也一定是在代码层面出现了问题,我们要尽全力找到并解决它,不能因为它非常偶发而忽视。
赖铮:
保持好奇。
陈福荣:
第一,需要刨根问底的精神。对于一个技术问题,如果这个问题是自己的主要工作,或者是某个待解决问题的关键路径,必须把这些问题完全搞清楚,不能似懂非懂。对于底层技术而言,对更多底层问题的钻研,会发现这些问题的解决思路其实是类似的,渐渐会建立自己的方法论,因此不要轻易放过一个问题或者bug。
第二,对最终结果负责。不能仅仅满足于功能开发完成,这点特别重要。一个任务,一定不仅仅是希望这个功能跑起来,更多是希望真正能够解决业务问题和痛点。如果开发人员仅仅把自己定位成代码编写者,是不够的。
第三,可以有一点点代码洁癖,这样会让自己写出风格更好的代码。
陈再妮:
做事严谨,就像计算机的世界非0即1;态度认真负责,值得信赖。
张风啸:
我觉得是对感兴趣的事情的喜爱和追求。技术和其他方面都一样,一定是有兴趣、有追求,才能做得更好。
陈松威:
我觉得是,要有一种“空杯心态”。
厉害的程序员都有哪些特别的能力 ?
雷海林:
a)学习能力。个人很渺小,要不断地虚心学习,看书、看文章论文、多掌握原理性质的东西; b)热爱阅读开源社区好的代码,通过学习别人的代码提升自己的编程能力; c)对自己有信心,遇事不妥协,高标准要求自己,喜欢去解决工作领域各种技术上的挑战。
陈福荣:
第一是学习能力。开发这个领域新技术是层出不穷,如果不具备很好的学习能力,很容易会出现一些力不从心的状态。当然,如果有比较好的计算机基础理论的背景,学习起来是可以触类旁通的。
第二个是抗压能力。线上bug是不可避免的,如果出现线上故障压力一定是很大的。但此时最重要的是优先恢复业务,因此,一定要顶住压力,保持思路清晰,寻找最高效的解决办法。
第三个是心态调整能力。厉害的程序员都会表现出干劲十足,精神饱满,除了本身对工作的热爱外,还需要自己心态上的调整,以及适当的泄压方式包括锻炼身体等。
陈再妮:
a)极客精神:对未知技术保持好奇之心,并持续学习; b)看待问题可以通过表象直到问题根源; c)有趣的灵魂:代码注释写的让人如沐晨风,比如让模块运行起来:
/* Do the modulemagic dance */
PG_MODULE_MAGIC;
赖铮:
思维缜密,逻辑性极强。
张风啸:
专注, 细致,心思缜密,思考全面;以及对问题刨根究底的态度,深入钻研。
陈松威:
逻辑性强、创造力强、思维严谨、良好的沟通能力。
对数据库未来发展趋势,有什么看法或建议
雷海林:
数据库必定还是会往分布式数据库的方向继续发展。整体来看,则将在数据库弹性扩展、跨地域进行分布调度、6个9(99.9999%)以上的可用性、HTAP融合、SQL智能诊断与优化、极致的性能等方向持续发展——最后回归数据库的本质:当某个业务获取到一个数据库的域名地址,数据库就是一个黑盒子以极致的性能提供SQL读写服务。不用再关心容量、SQL调优、容灾等细节。
赖铮:
数据库未来会操作面向云计算的方向发展,云原生数据库将会成为主流。弹性扩展、TP+AP、海量数据等特点将会充分显示出云原生数据库的优势。
陈福荣:
1)分布式。未来的数据库一定主要是使用分布式的架构,无论是share nothing还是share disk,都能较好解决数据库的容量问题,便于弹性扩缩容;
2)软硬结合。未来数据库一定会结合软硬一体化的设计理念,充分发挥硬件的性能,满足企业级用户的需求,如更快的响应时间、更高的安全性、更大的容量、更低的成本等;
3)智能化。未来的数据库会结合数据库的运行状态以及AI的能力,提升数据库管理的智能化水平,包括故障诊断、故障预测、自动扩缩容、更优的执行计划等。
陈再妮:
未来数据库一定会依据新型硬件做架构层面的改良,举个例子:传统数据库是基于存储不可靠以及存储性能差设计的(WAL、REDO、UNDO、DO、CHECKPOINT),是基于当前CPU运算速度设计的(32位事务ID,64位事务ID),但是好多理论随着硬件的快速发展会被彻底颠覆:比如基于云原生数据库(接近于基于存储可靠的设计),云原生内存数据库(数据全部存储于内存,主要解决网络问题 RDMA、DPDK、SPDK 等)、量子数据库等,这些基于新硬件新理论才是数据库的未来。
张风啸:
一方面是,当前业界关于数据库的架构、存储结构等很多方面的研究已经很多且比较完善了,而存储介质等硬件方面的变化,可能给会给存储的架构设计带来很大的变化,所以我们可以多关注新型存储产品的出现带来的一些变化。
另一方面是我很赞同的观点:性能不是唯一的肌肉,稳定性、产品化、运营体系等方面,才是当前国产数据库面对最突出的几个挑战。数据库要发展好,发展优秀的生态和做好产品化是至关重要的。
陈松威:
数据库未来趋势是云原生。在未来的产业互联网中,数据库的弹性扩展能力、自我诊断快速运维能力、个性化服务能力将非常重要。

推荐一段值得称道或简短代码片段?
雷海林:
Linux内核的list.h组件,实现简单,通用性好:
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
#ifndef CONFIG_DEBUG_LIST
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
#else
extern void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next);
#endif
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
赖铮:
存储引擎里字节序转换函数代码,简单明了,非常精巧。
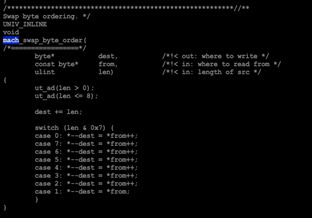
陈再妮:
/*
* TransactionIdPrecedes --- is id1 logically < id2?
*/
bool
TransactionIdPrecedes(TransactionId id1, TransactionId id2)
{
/*
* If either ID is a permanent XID then we can just do unsigned
* comparison. If both are normal, do a modulo-2^32 comparison.
*/
int32 diff;
if (!TransactionIdIsNormal(id1) || !TransactionIdIsNormal(id2))
return (id1 < id2);
diff = (int32) (id1 - id2);
return (diff < 0);
}
这段代码乍一看平平无奇,但要结合PG事务环来看,这个算法设计得很巧妙的,而且刚好在PG这种事务环下才是有效的。它在半个事务环的限制下,巧妙的运行 2 的补码,实现无符号事务ID的比较:

张风啸:
世界上最简单的数据库可以只用2个bash函数实现。这是在书籍《DesigningData-IntensiveApplication》中截取的,也非常推荐大家去阅读。
#!/bin/bash
db_set () {
echo"$1,$2" >> database
}
db_get () {
grep"^$1," database | sed -e "s/^$1,//" | tail -n 1
}
陈松威:
想推荐一个存储引擎里实现中的一个页面校验函数:btr_validate_level。这个函数将所有可能的校验条件都一一列举,包括页面在区中的状态校验、页面本身校验、相邻页面指针校验、父子节点指针校验、父子节点相邻节点指针环校验等等。代码非常严谨,对我启发很大。

陈福荣:
简短代码片段意义不是很大,一个片段不管有多好,也不是一个可服务的载体。相对于代码片段,一个完整系统的设计与实现显得更重要。如果是C语言,推荐redis;如果是C++,推荐LevelDB或RocksDB。如果把成熟的开源软件代码认真看一遍,对个人的提升还是很大的。
本文由博客一文多发平台 OpenWrite 发布!