# -*- coding: utf-8 -*-
# Import data and modules
import pandas as pd
import numpy as np
from sklearn import datasets
import pylab
import matplotlib.pyplot as plt
pylab.rcParams['figure.figsize'] = (10, 6)
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import cross_val_score
def main():
## Load the iris data
X_train, X_test, y_train, y_test, iris_df, X, y = get_data()
X_train_std, X_test_std = scale_data(X_train, X_test, iris_df)
show_data(y_test, X, y)
classification = Adaboost(X_train_std, y_train, X_test_std, y_test)
classification.perform_adaboost(X_train_std, y_train, X_test_std, y_test)
def get_data():
# Only petal length and petal width considered
data=pd.read_excel('D:\学习\专业主干课\机器学习\数据集\\UCI数据集\seeds_dataset.xlsx',header=None)
data=data.values
# 任选两列
# wine 选0 6 最好
# iris 选0 3
# seeds 选0 1 7
X=np.array([data[:,3], data[:,2]]).T
y = data[:,7]
#print(y)
# Place the iris data into a pandas dataframe
iris_df = pd.DataFrame(data[:,0:2],columns=['petal length (cm)', 'petal width (cm)'])
#print(X)
# View the data
#print(iris_df.head())
# Print the classes of the dataset
#print('\n' + 'The classes in this data are ' + str(np.unique(y)))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3, random_state=0)
#print('Training set are {} samples and Test set are {} samples'.format(X_train.shape[0], X_test.shape[0]))
#print()
return (X_train, X_test, y_train, y_test, iris_df, X, y)
##scale the training data before training
def scale_data(X_train, X_test, iris_df):
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
#print('After standardizing our features,data looks like as follows:\n')
#print(pd.DataFrame(X_train_std, columns=iris_df.columns).head())
return (X_train_std, X_test_std)
##visualization of the data before training
def show_data(y_test, X, y):
##There are 3 classes
markers = ('s', 'x', 'o')
colors = ('red', 'blue', 'green')
cmap = ListedColormap(colors[:len(np.unique(y_test))])
#y=np.array(y)
#print(y)
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
c=cmap(idx), marker=markers[idx], label=cl)
plt.rcParams['font.sans-serif'] = ['Microsoft Yahei']
plt.rcParams['axes.unicode_minus'] = False
# plt.xlabel('Compactness')
# plt.ylabel('Kernel_Groove_Length')
plt.show()
##Adaboost Class
class Adaboost(object):
def __init__(self, X_train_std, y_train, X_test_std, y_test):
self.X_train_std = X_train_std
self.y_train = y_train
self.X_test_std = X_test_std
self.y_test = y_test
def perform_adaboost(self, X_train_std, y_train, X_test_std, y_test): ##perform adaboost
ada = AdaBoostClassifier(n_estimators=10)
ada.fit(X_train_std, y_train)
train_score = cross_val_score(ada, X_train_std, y_train)
print('训练集正确率:{:.2f}%'.format(train_score.mean() * 100))
test_score = cross_val_score(ada, X_test_std, y_test)
print('测试集正确率:{:.2f}%'.format(test_score.mean() * 100))
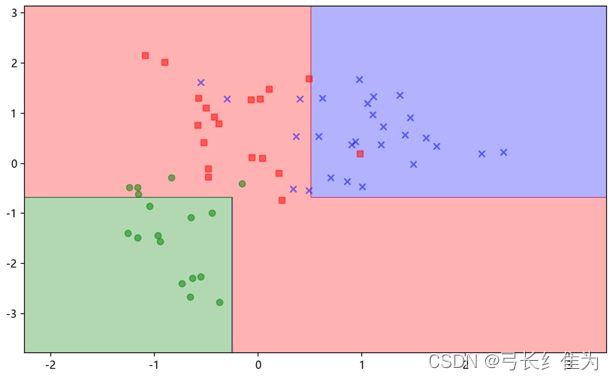
X = X_test_std
y = y_test
resolution = 0.01
# Z = svm.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'green', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y_test))])
X = X_test_std
y = y_test
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = ada.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.3,cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=0.5, c=cmap(idx),
marker=markers[idx], label=cl)
plt.rcParams['font.sans-serif'] = ['Microsoft Yahei']
plt.rcParams['axes.unicode_minus'] = False
# plt.xlabel('Compactness')
# plt.ylabel('Kernel_Groove_Length')
plt.show()
if __name__ == "__main__":
main()