【李宏毅ML笔记】19 CNN
CNN常被用于影像处理上,也可以用一般的Network来处理影像。
输入为图像转换而来的pixcel,输出可能为1000个类别,每一个neuro可以看做是一个classifier,层层进一步的判断当前是否是某种线条,纹理,图像片段等等,来做识别。
问题:当使用fully connected Network时,总会需要太多的参数。如100*100,彩色图像会有100*100*3个维度的图像,假设第一层hidden layer有1000个neutron,如何简化neutron来简化Network的架构,如某些weight就用不到,从一开始就删掉这neutron或权重。

为什么可以把一些参数拿掉,就可以做影像处理?
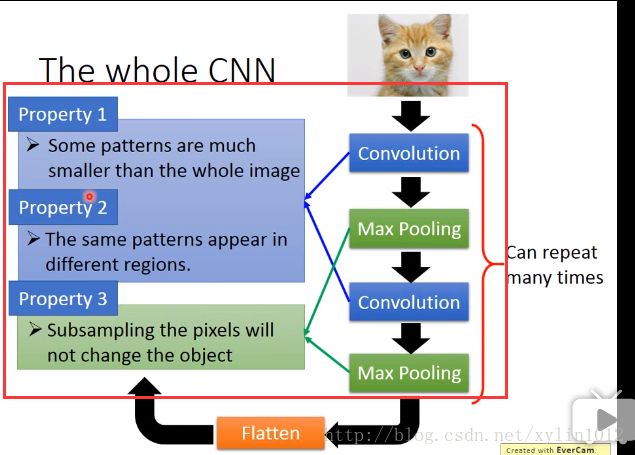
观察1 如果第一层layer就是侦测有没有某种pattern实现,大部分的pattern就比image小,只需要看imgae的一小部分就可以了。第一个hidden layer的某一个neutron侦测有没有鸟嘴的存在,只需要给neutron看红色小框框的一小部分就知道了。所以,每个neutron只需要连接到一小块区域就可以了。不需要链接完整的图。

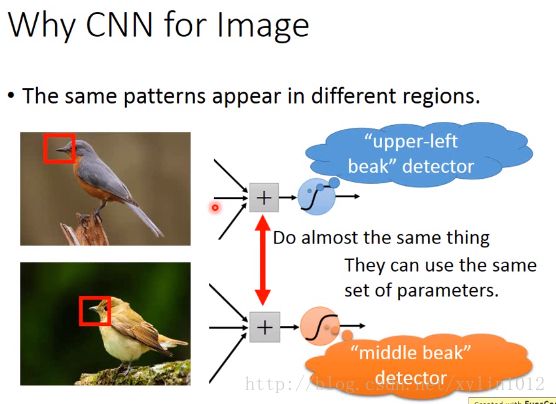
观察2, 同一个pattern,会出现在image中的不同的部分,但是代表不同的含义。如左上角的鸟嘴,中央的鸟嘴,其实只需要判断是否有鸟嘴即可。即不需要有两个neutron来对鸟嘴来判断出是左上角的鸟嘴还是中央的。所以,两个neutron使用共同的参数。
观察3,如对image可以做subsampling,即拿掉偶数列的pixel,不会影响判断。即减少image的pixel。

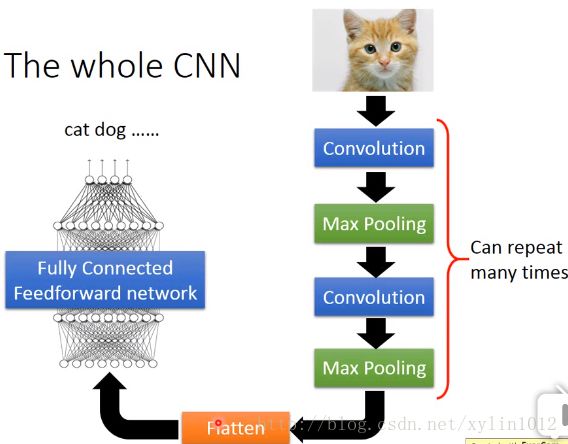
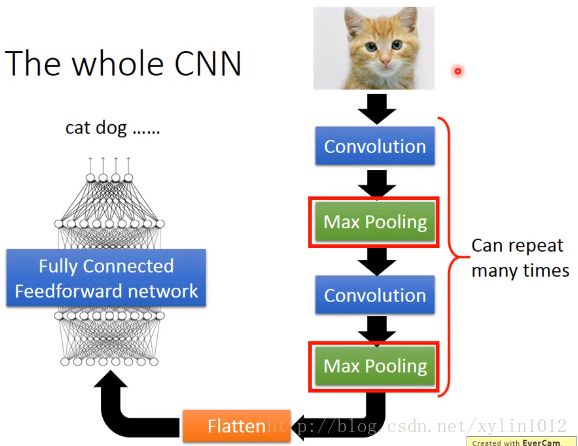
所以,如下,整个CNN架构,先通过Convolution,在做MaxPooling,再反复数次,即反复设置多个layer层次然后做flatten,然后丢到fully connected feedforword Network。
基于观察,作用Convolution和Max Pooling做左边如下几件事情:
下面介绍Convolution,
假设Network 的输入image为6*6,01代表是否有墨水,在convolution中有一堆filter,每一个都是一个Matrix,每个filter中的参数就是Network中的要学习的参数值parameters,类似于weight和bias。
假设每个filter都是3*3的黑白图片matrix(要学习的东西,类似于fully connected中的weight),则在图片中,只侦测3*3的部分的内容,判断是否出现某个pattern。即,使得pattern只看一部分图像,而不是全部,比如前面提到只看鸟嘴就可以了。
filter即感受视野,其中的权重w矩阵称为卷积核,stride叫做步长,感受视野越界时,需要对其做边界扩充。边界扩充值可以设置为0等。卷积核的权重w矩阵即神经网络layer的参数,卷积核可以附带一个便宜项b,初值可以随机初始化,在训练过程中会变化。
怎么做uperration??呢?
将filter放到左上角(其实filter就是一个neutron,其中的9个值作为参数),需要做的,将0转为-1,将9个值做内积,
然后从左到右,从上到下,挪动filter的位置,挪动的距离叫做stride步幅,可以自己设定,可以计算得到多个filter与图像对应部分的内积。
这样,经过convolution的操作,将原先的6*6的matrix,转变为4*4的matrix。
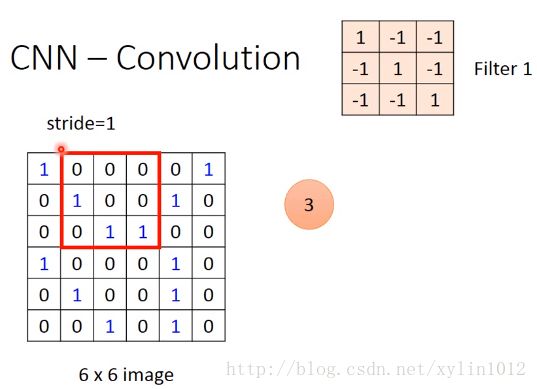
如判断是否有pattern:斜线链接三个1,这样左上角和左下角位置都用一个pattern就可以侦测出来了。这样就考虑的propery2,
将filter1根imgae做匹配。
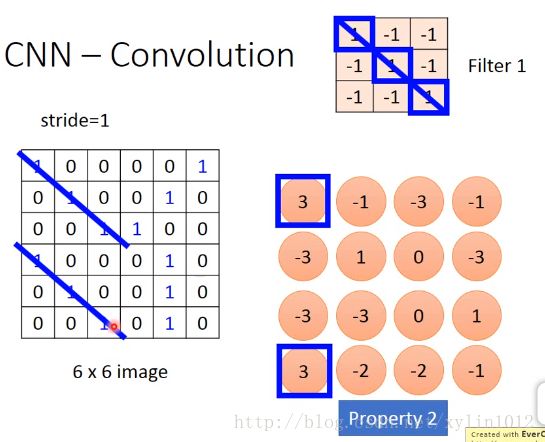 。
。
在convolution中,filter2与filter1有不同的参数,将filter2跟imgae从左到右,从上到下做convolution,做匹配,可以得到: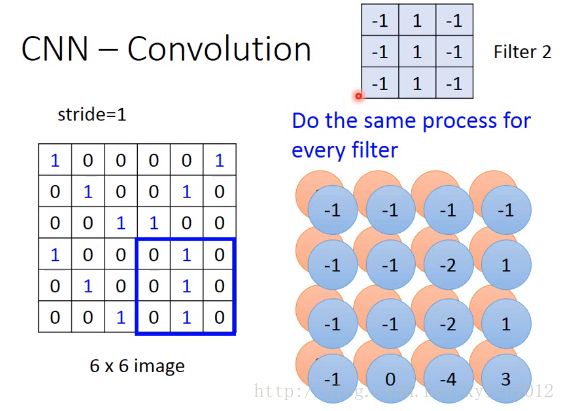
将底层红色的matrix,与上层蓝色的maxtrix合起来,当做feature map,有几个filter,如100个filter,就会得到100个image。
【feature map,特征映射图,为一个带有卷积核的感受视野扫描生成的下一层神经元矩阵,将原先的矩阵归纳并缩小了
一个feature map上的神经元使用的卷积核是相同的,共享卷积核的权重和偏置,一个feature map对应一个卷积核,即filter,若使用3个不同的卷积核,则得到3个feature map。因此训练的参数可以从6*6减少为4*4,如果有偏置,则加1,如果是3层的彩色,则乘以3倍
】
每个filtersize一样,如不同大小的鸟嘴,则不好处理。当你input一个image时,在cnn前面再做一个Network,可以处理数据,如将图像选装,处理。
如下,如果是彩色的matrix,则是好几个matrix叠加在一起,像一个立方体,此时,filter也是一个立方体,即其中一小部分。原input是3*3*6,则filte大小为3*3*3,则将每一部分的三层channel合并在一起看。
Convolution和fully connected的关系。
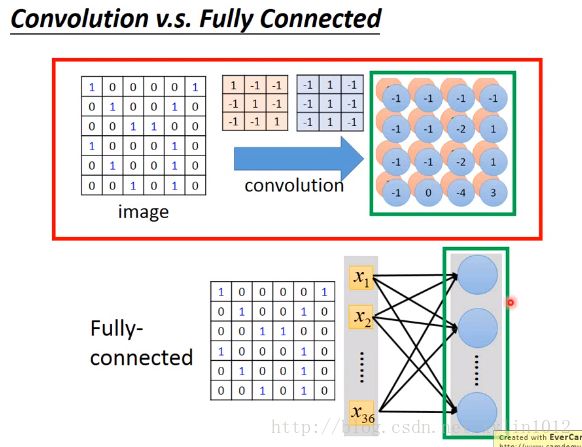
如下,convolution的事情,就是把fully connected的部分参数拿掉。一个filter就是一个fully connected拿掉一些weighted的结果。
具体,将6*6image拉直,有一个neutron的output是3,来源就是只只考虑了部分的左上角部分的pixel的值,并构成一个neutron。
x就是原图像左上角的值,weight就是filtter1的值(要学习的参数),neutron本来应该链接6*6=36个inputx值,但实际只链接9个只的pattern,此时就是用了前面提到的部分图像。
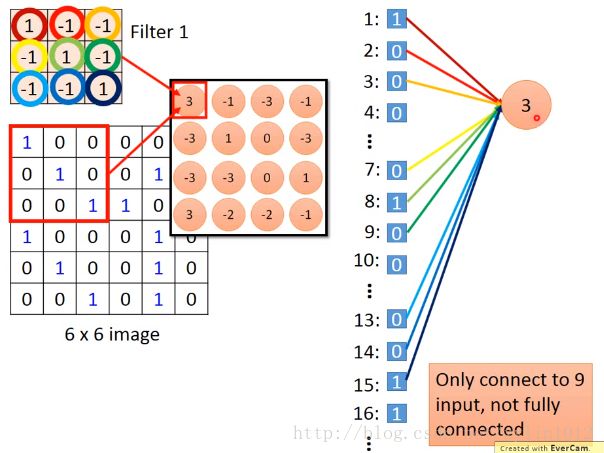

看上两幅图中的同样的weight代表同样的线条颜色,所以,右边3和-1,在原先的fullyconnected中有相同的weight。所以,使用Convolution之后,一方面只是用了部分的图像(部分输入input),而且不同的neutron实现了weights sharing
一般调用tookit,实际代码写法跟BP一样,有的位置的weight的值永远都是0,如何让不同的neutron的weights一样呢,即对不同的神经元,算出各自对应的gradient,然后将gradient平均,然后update所有的神经元的对应部分的weight的值。
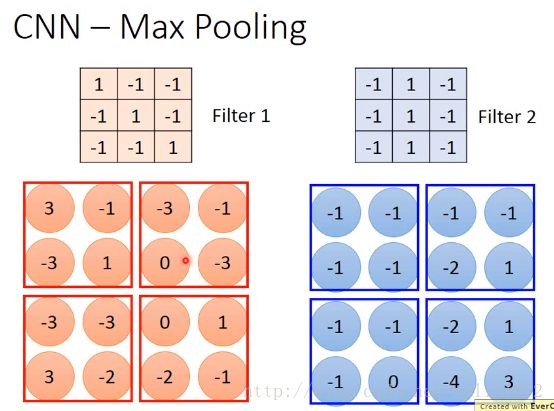
然后是做Max Pooling,就是做subsampling。
接下来做的就是,对每个filter得到的feature map,将其中每一个进行分为4组,每一组可以选他们的平均,或最小或最大
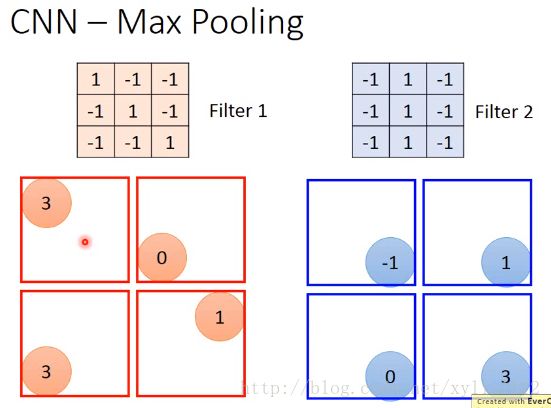
实际Max后也可以微分,尽管是挑的最大、或最小,或平均。
所以,如下,对于原先的图像,做完一次convolution,和一次maxpolling,将6*6的变成了2*2的matrix,得到新的image,如下:
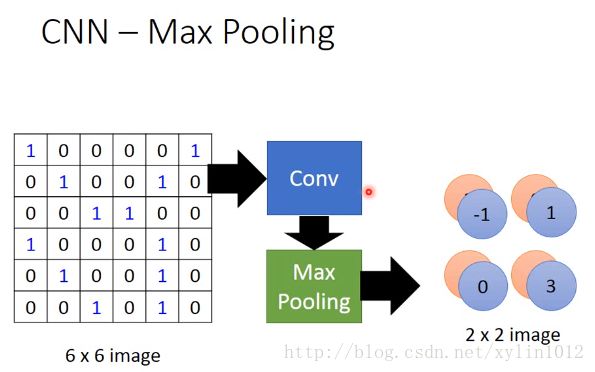
可以重复很多次,将小的,得到更小的image。
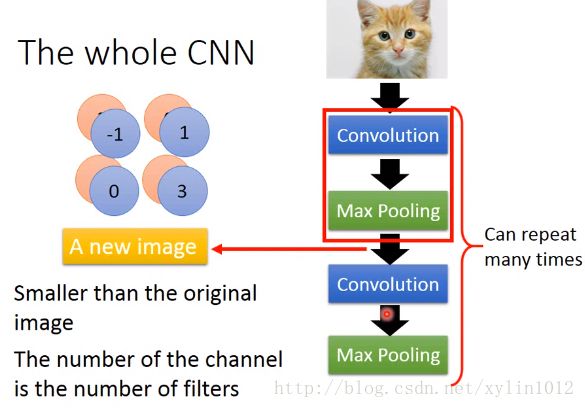
如果第一个CM,左上角有25个filter,做完一次convolution+MaxPooling,得到25个feature map,
如果第二层CM,也有25个filter,会不会得到25的平方的featuremap。因为feature map是cubic,第二层filter在考虑input时,会考虑input的深度的,不会分开考虑channel,会考虑所有的channel,所以前面输出25个feature map,后面输入25个feature map,并输出25个feature map。
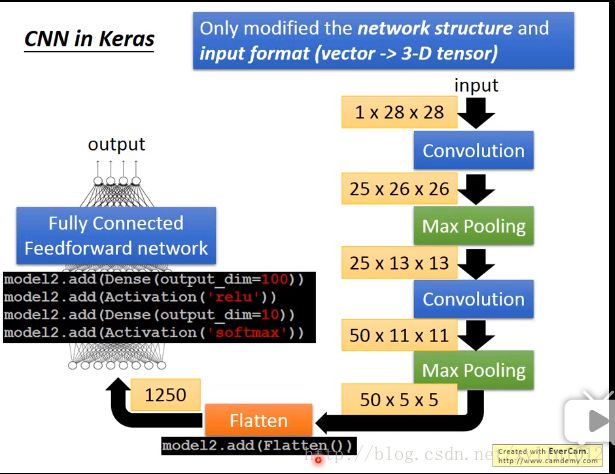
最后flatten,将feature map拉直,可以丢到fully connected work。
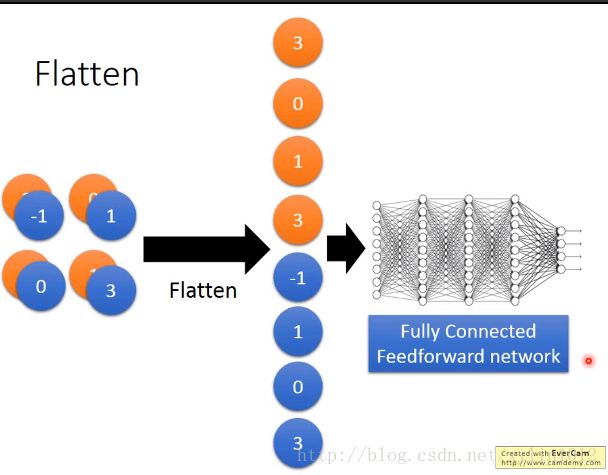
在keras中如何使用CNN?
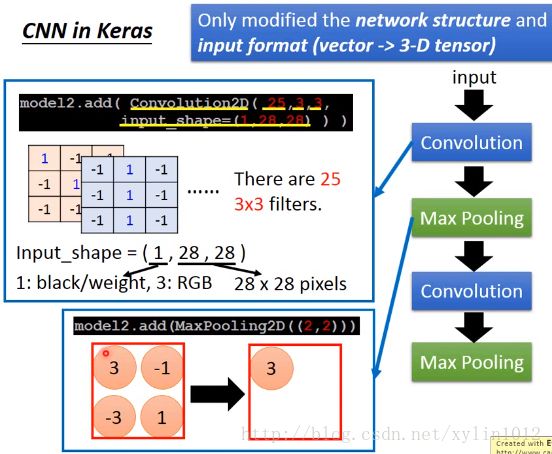
1 修改输入格式,从vector改为3-2tensor。Tensor就是高纬的vector/matrix。
2 修改网络结构,加入convolution和max pooling。
convolution2D(25,3,3),25代表filter,3,3代表3*3的filter的matxi size。
input_shape(1,28,28),代表输入的是1黑白3彩色,28*28代表图像的打小,28*28个pixel。
Maxpooling2D((2,2))代表从feature map中拿出2*2的subsampling。
如下,
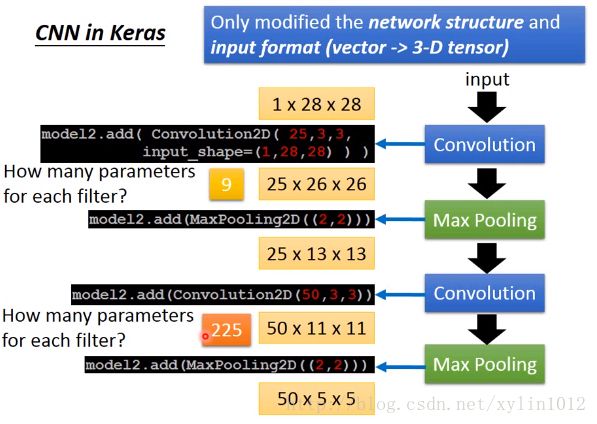
做convolution输出,建立25个filter(即神经元Neutron),得到的数目就是25个channel,因为filtersize是3*3,将原来的28*28变成了26*26,没有考虑成边边,也可以考虑,则自己补齐数据。
做激励层,因为卷积层的输出还是一个线性计算,一般使用relu函数将卷积层的输出进行一个非线性映射。
再做池化maxpooling,用来对卷积激励层的结果特征进行进一步的降维,输出深度不变。将每个filter分成2*2来做subsampling,做完之后变成25*13*13,池化视野即上文中的计算小矩阵值的方式,一般为max pooling或averagepooling。池化视野也会有步长stide。扫描方式一样。
【总结,卷积是用来获取部分特征矩阵,简化网络结构,简单化权重参数值,使其权重共享,激励层做非线性映射,池化层下采样做特征进一步的降维】
然后继续做convolution,可以设置不同的filter,如50个。13*13的matrix,通过3*3,则变成了2*2.可以继续做maxpoling。
则第一层convolution里有9个参数,第二层有3*3*25个参数,每个filter都是3*3的,高是25????
最后拉直,addflatten,变成50*5*5维度的fully connected。
切分层,对图片进行切割,独立的对某一部分区域进行单独学习,可以对特定部分进行调整感受视野,进行力度更大的学习。
融合层,对且分层进行融合,也可以对不同大小的卷积核学到的特征进行融合。如在GoogleLeNet中。
全连接层:对特种进行重新拟合,减少特征信息的丢失。
输出层:做好最后目标结果的输出
Live Demo:
假设有25个filter??,每个filter的size是3*3。1*28*28的维度的图像。经过3*3的方格选择,得到26*26的新的image,每个image的pixel都是由一个25维的vector来表示。即有25个filter,有25维的pixel。
在做subsampling变成13*13.....
dl就是黑盒子,intelligent就是你无法理解的,实际也可以分析。
下面讲CNN学到了什么?
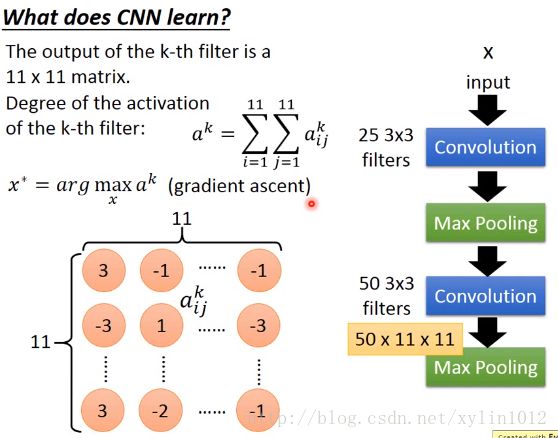
第二层的CM,50*3*3,输入时上一次的输出,权重不知道是什么,也不知道它在做什么。其中的3*3的filter考虑的input不是原先的3*3的pixel,是之前的转换结果。分析方法:
问题:?filter是一层神经元的共享参数?那么设置多个filter用处是做什么?叠加feature map?
其中的每一个filter的convolution之后的output就是一个11*11的matrix。
判断第k个filter被启动激活的程度,使用11*11上的值的和来表示。
想找一个imgae,可以将第k个filter被activited的程度最大,即找x*。maxmize用gradient ascent,minsize用gradient descent做update。【没完全听懂】
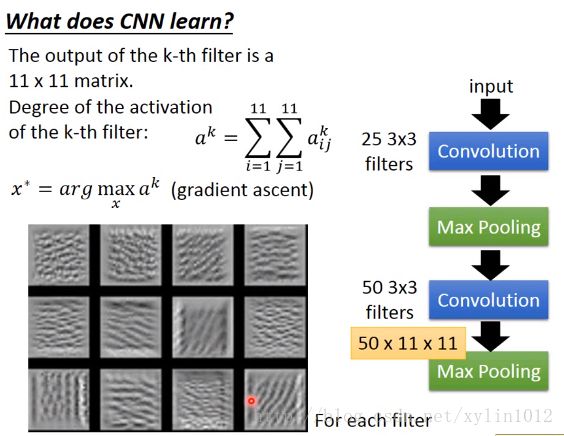
以上是某种texture是在图上不断地反复,如第三个,是斜条纹在不停地反复,这是一个很小的范围。如果出现一个这样的一个值,这个filter就会被激活,degree就会变大。每个filter就是在detect某一种不同角度的线条或者纹路。
以上分析完convolution 和max Pooling
做flatten,丢到fully connected
下面分析fully connected【没完全明白】
定义第j个neutron,output为aj,找一个image x,将其丢入到fully Network中,可以将aj被maxmize。结果如下:

以上,刚才filter中观察到的是纹路,只是小小的一部分,在做flatten之后,每个neutron就是看整张图,所以,每个neutron最activited是一个完整的图形。
47分钟 - 54分钟没看懂,先略过。
Deep Dream
目标:夸大图像里面的内容,比如图像里有个石头,形状像狗熊,则经过训练好的神经网络以后,原先的图片里的石头会变成狗熊。

原理 :利用CNN神经网络学习一系列图片时,将Network中的卷积层里的filter/全连接层里的隐藏层中的神经元的权重,大的变大,小的变小,这样可以夸大学到的东西。这样便可以将Network从狗熊的图像中中学到的东西,在输入带石头的图像时,会输出带狗熊的图像。

Deep Style,如下:左边是原先的图片,右边是参考的风格。
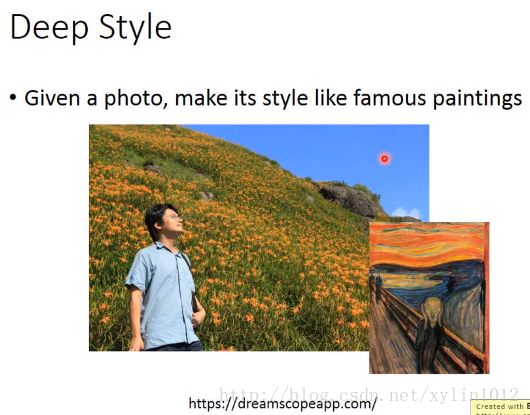
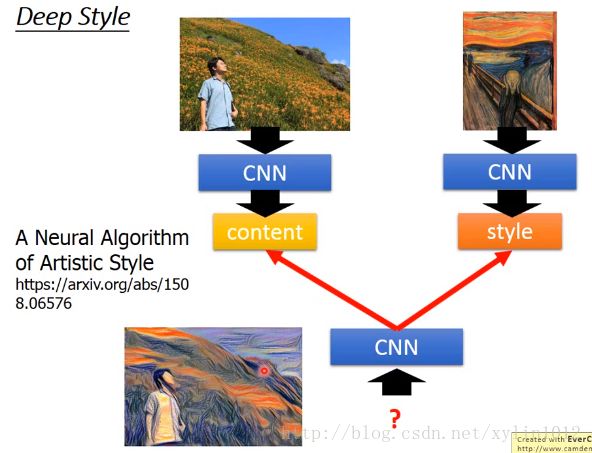
目标:input一张image,让machine去修改这张图片,使其拥有一种另外的风格,如梵高的风格。
原理:将原来的imgae丢给cnn,得到cnn的卷积核的output,该output代表这个image中有什么样的content。同理将呐喊这张图片也丢给cnn,此时考虑的不是卷积核的output,而是在意filter和filter之间output之间的correlation,这个相关性correlation代表这个哪行图片的style。最后,结合两张输入的相片输出一个新的相片,content(由卷积核output决定)像左边图,syle(不同卷积核之间的correlation)像右边图。即可以使得输入的左边图模仿了右边图的style。
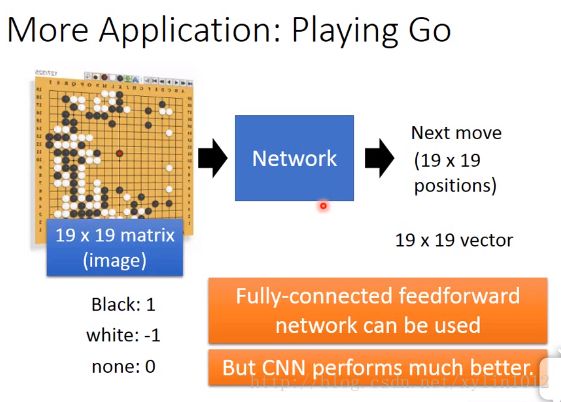
CNN应用于Playing Go
实际上,任意一个Network,如fully-connected feedforward network,input是棋盘,output是下一步的落子位置。只是采用CNN的performance更好。
一般Net:input:19*19 vector,vector每一个dimension对应到棋盘上某一个位置,+1为白字,-1位黑子,0为无子,,一个19*19的vector,落子位置为1 。
若用CNN,则需要输入matrix,即将19*19的vector表示成19*19的matrix。类似于图像的形式。输入仍然为下一步的下子位置,一个19*19的matrix,落子位置为1 。
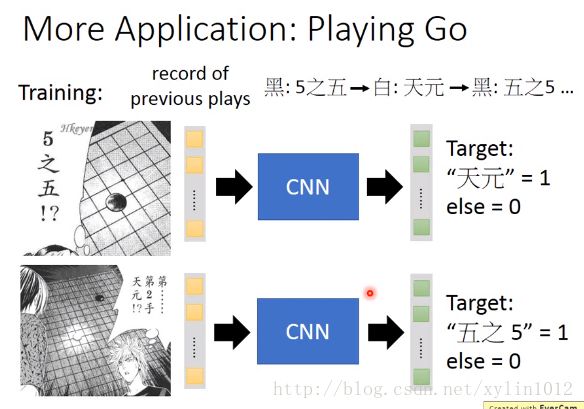
如AlphaGo的traing阶段:
这是supervized的阶段,实际还有增强学习的阶段。
什么时候可以用CNN呢?
存在image该有的特性架构,即三个观察,可以用CNN。围棋的特性跟image一样。
1. 在image上有些pattern比整张image小的多,但是起决定作用,Network只需要看到这部分内容即可做出判断。围棋一样,AlphaGo第一个filter就是5*5.
2. 同样的pattern会出现在不同的位置,但是他们会代表的是不同的信息意义。可以使用同一个detecter,来处理不同位置的pattern。
3. 对一个image做subsampling,从image中拿掉奇数列或者偶数列,仍然不会改变原样子。所以产生了max pooling. 但是对于AlphaGo怎么用怎么解释呢?在AlphaGo论文附录的CNN里,提到输入时19*19*48来表示的image,每个位置都是用48个value来描述。这些value包括dominant value,即这个位置是否处于 jiaochi的状态。19*19的image补上更多列,变成21*21个,用5*5的k个filter,stride设置为0,使用relu的activation,使用了2-12层,最后变为3*3的filter,步长依然为1......alphago没有用maxPooling

CNN用在语音识别中
将声音表示为Spectrogram,横轴是时间,纵轴是频率,即单位时间内的声音能量频率。通过频谱可以看出字来。可以将频谱作为图像,但是filter是长方形的,移动的时候,只移动竖着的方向,即频谱方向,因为在语音中,output会接LSTM、RNN等,无需再考虑时间了,用filter目的是为了同样的pattern出现在不同的位置,同样可以把它们识别出来。比如男生跟女生说的你好的pattern可能一样,但是时间频率长度不一样,所以,横坐标感觉意义不大。
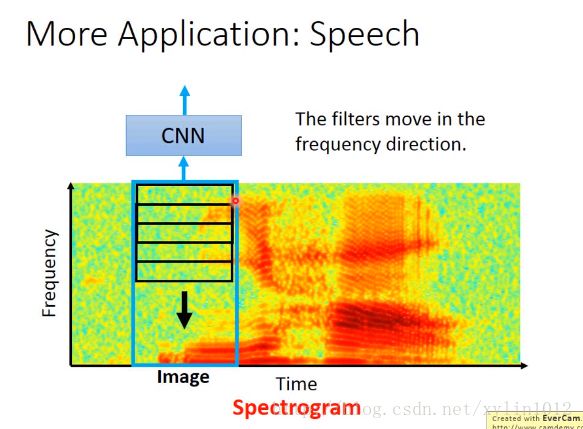
所以在做CNN的应用时,要结合实际场景、特性去修订CNN。
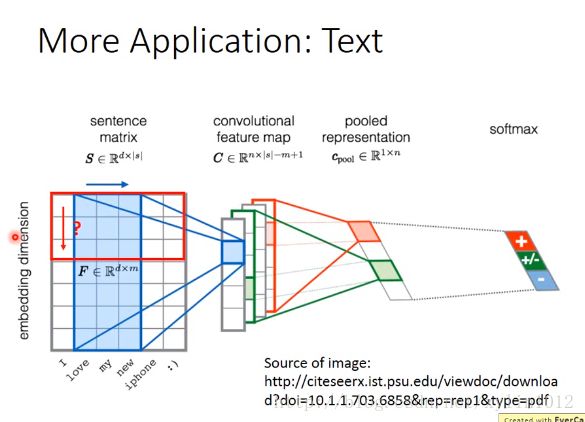
自然语言处理。
输入一个word sequence,假设输出句子是积极的,还是消极的,则将每个单词改为一个vector,叫做word embeding,则将多个word的vector之后,则将其可以看错是一个矩阵,一个matrix,则制作一个filter,沿着句子方向移动,因为这个方向有意义,词与词之间有关联关系的,这里出现了一种pattern。在word embing上每个单词的含义是有意义的,所以无效。