Bigtable 论文笔记
疑点已标红
BigTable 是的数据模型类似于mysql中的表,只是每个cell可以有多个版本。
(rowkey,column key, timestamp) 唯一的决定一个 value,每个value就是一连串的Byte
column key的结构是column family:qualifier,column family 必须是printable,qualifier可以是arbitrary 字符串
Web Page Table:

rowkey 是一个网站的url的倒序,例如com.cnn.www
这个table有很多的column family,比如anchor,contents
contents 这个column family的意义就是就是www.cnn.com 这个网站首页的内容。它可以有多个版本,图中有三个版本,时间戳分别为t3,t5,t6
一个column family下面可以有很多不同的qualifier,例如:
anchor:cnnsi.com的意思是cnnsi.com 这个网站中有一个超链接指向www.cnn.com 这个网站,anchor(锚)文本是CNN。
anchor是column family,cnnsi.com 是qualifier,
rowkey 是一个arbitrary字符串,最大64KB,一般都是10~100Byte,对一行的写和读是原子的,不管读操作或者写操作涉及到多少列。所谓行事务
BigTable以rowkey的字典序来维护数据,一个Table会被动态的分区成tablet,tablet包含的原来Table中的某个范围的行,tablet是分布式存储,负载均衡的单位。
正是由于行是以rowkey的字典序来维护的,所以应用可以利用这个特点将它们的数据组织在一起,这样以后读取数据的时候就只需要读取少部分机器了。
WebTable中将url逆序存储就是一个很好的例子。
column family是权限控制的单位。数据被存储之前首先需要定义好column family,设计者希望一个table中不同的column family的数量最多在百级别并且column family
在操作的过程中不会被改变,对表中column的数量没有限制
disk和memory的统计也是以column family为单位。
bigtable 中的timestamp是64bit的整数,这些timestamp可以由bigtable自己设置为实际的时间以微妙为单位 或者 被客户端指定timestamp,后一种情况下,客户端需要自己
避免timestamp冲突。一个cell内的多个版本的数据以降序排列。
为避免同一个cell有很多个版本的数据造成的管理开销,客户端可以指定要求 只保存最近的n个版本的数据 或者要求只保存最近7天的数据,bigtable会自己进行垃圾回收。
API
bigtable API提供了创建/删除 table , column family,更改集群,table和column family的元数据,例如acl

上图的代码段对rowkey="com.cnn.www"的行,将column key="anchor:www.c-span.org"的列的值设置为CNN
删除column key = "anchor:www.abc.com"的列。其中Apply()是原子操作

上图的代码段遍历rowkey="com.cnn.www"的行中column family="anchor"的所有列的所有版本。scan操作很灵活,比如可以过滤列,支持正则等很多。
不支持跨行事务,提供将跨行的write操作batch的接口。
bigtable可以和mapreduce一起使用,google已经提供了很多的wrapper让bigtable可以成为mapreduce的输入输出源
Building Blocks
bigtable使用gfs来存储log和数据文件。bigtable集群常常和其他的分布式应用程序共享机器,bigtable利用一个集群管理系统来调度job,管理机器资源,处理机器故障
和监控机器状态(这个系统已经有paper,dapper)
SSTable文件格式用来存储bigtable的数据,SSTable提供了持久化,有序,不可变的map,key和value都是arbitrary字符串。
可以根据key查找value,也可以遍历某个key范围内的所有key/value对。
从内部结构来看,sstable包含了连续的block,每个block 64KB,这个可以配置,block index存放在sstable的末尾,用于定位block,当sstable打开的时候,block index
被load到memory。这样的话,查找操作只需要读一次磁盘,对内存中的block index进行二分查找定位block,然后从磁盘中load整个block。还有一种方法是把sstable整个
mmap,这样以后的操作就不需要touch 磁盘了。
bigtable还依赖一个高可用的,持久化的分布式锁服务chubby。chubby由五个replicas组成,其中一个被选为master提供服务。chubby能对外提供服务的条件是大多数的replicas
正常并且相互间能够通信。chubby使用paxos算法来保证发生fail的情况下replicas的一致性。chubby提供了一个由目录和小文件组成的namespace。每个目录或者文件可以作为
一个锁,对文件的读或者写都是原子的。chubby的客户端库会一致性缓存chubby中的文件。每个chubby 客户端与chubby服务之间维护一个session,如果session过期之前client
不去renew session lease,那么session就会过期,一旦一个客户端的session过期,它会失去所有它拥有的锁和打开的handle,客户端也可以注册回调函数在
chubby的file或者目录上,当文件或者目录内容改变或者session过期时,回调函数会被调用。
bigtable使用chubby做很多工作:
1 保证任何时候只有一个bigtable master server
2 存放bigtable data的bootstrap 数据在chubby中(看后面)
3 存放bigtable的schema的信息(每个table的column family信息)
4 存放acl
如果chubby 在一段时间内unavailable,那么bigtable就unavailable
implementation
bigtable由master server,很多tablet server和链接到客户端的library,tablet server可以动态的从集群中移除和加入。
master server负责分配tablet给tablet server,tablet server的负载均衡,schema的改变,如table,column family的创建,检测tablet server的加入和移除,
GFS上文件的垃圾回收。
一个tablet server通常管理10~1000个tablet,tablet server处理对它所load的tablet的读写请求,当一个tablet太大的时候,对tablet进行分裂
和大多数单master结构的分布式存储系统一样,客户端读写tablet不通过master,而且客户端获取tablet的信息也不是从master,所以master的负载相当的低
初始的时候,一个table只有一个tablet,当table大小增长时,table被切分成了多个tablet,每个tablet大概100MB~200MB
Tablet location
使用3级的类似于B+ tree的数据结构存储tablet location信息。
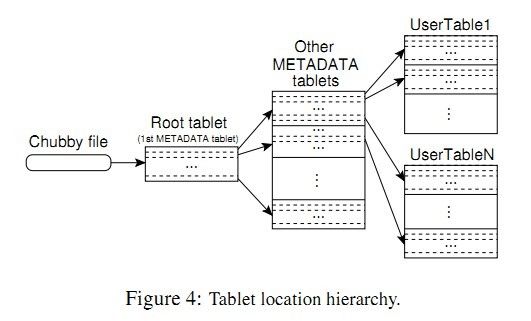
第一级就是这个chubby file(即上文中的bootstrap数据),它存储了 root tablet的位置。root tablet就是一个tablet,它不会随着大小的增大被分裂。
这个root tablet的每个entry指向一个METADATA tablet,每个METADATA tablet会包含很多的user tablet(实际数据)的位置。
图中的 Other METADATA tables有很多的tablets,每个METADATA tablet被root tablet的一行定位,这行的rowkey是它所指向的tablet的id和tablet的最后一个rowkey的组合
可以看出root tablet是一种特殊的METADATA tablet。
每个METADATA tablet(root tablet是一种特殊的METADATA tablet)的一行大约占用占用内存1KB,如果一个METADATA tablet(包括root tablet) 128MB,
那么每个METADATA tablet有2^17(128MB/1KB) 行,也就是说,可以寻址2^17行,这样,一个root tablet可以寻址2^17个METADATA tablet,每个METADATA tablet又可以
寻址2^17个user tablet,那么一共可以寻址2^34个user tablet
客户端library会cache tablet的位置信息。如果客户端不知道一个tablet的位置或者它发现cached的信息不正确,那么它就会从第一层开始找。
如果客户端library cache的信息是empty的,那么它需要三次的网络round-trip(因为三级的元数据)。如果cache的数据是stale的,那么最多6次round-trip。
虽然元数据都是存在内存中的,但是client library还可以通过预取tablet location信息来提供性能:当它每次读METADATA tablet的时候,它会多读几个tablet的位置信息。
Tablet Assignment
每个tablet每次只会被分配给一个tablet server
master维护:
1 可用的tablet server的集合
2 哪个tablet被分配到了哪个tablet server上
3 哪些tablet没有分配
当某个tablet没有被分配并且有一台tablet server有足够的空间容纳这个tablet的时候,那么master就会给这台tablet server发送load tablet的指令(数据是存在GFS上的)。
bigtable使用chubby来跟踪tablet servers。当某台tablet server启动的时候,它会在chubby的某个目录(servers)下创建一个unique名字的文件并且获得这个文件的锁,
master就是通过监控这个目录(servers)来发现tablet server的。如果tablet server 失去了对这个文件的排他锁(比如由于网络分区的出现,使得tablet server和chubby service失去联系,从而session过期),那么这个tablet server就不会对其上的tablet进行服务。chubby提供了一种有效的方法来使得在网络拥挤的情况下tablet server仍然可以check它自己是不是还hold了锁。失去了session后,只要文件还存在,tablet server就会重新要这个文件的排他锁。
如果文件不存在了,那么tablet server就会kill掉自己,再也不服务本机load的tablet了。如果集群管理系统将某个tablet server移除了bigtable的集群,那么这个tablet server
就会释放这个文件上的锁,以便master会把它load的tablet分配给别的tablet server
master负责检测tablet server是否还在服务,也负责分配 还没有分配的tablet 给tablet server。
master 会周期性的问tablet server它们持有锁的状态。如果tablet server回复说自己已经不持有文件的锁了 || master连续尝试了几次都没有连接上tablet server,那么
master就会去获取这个tablet server相对应的文件的锁,如果master获取到了这个文件的锁,那么master就知道chubby是好的,那么它就推断tablet server要么挂了要么由于
某些原因(比如网络)不能连接到chubby,那么master就会把这个文件删除掉,这样就确保这个tablet server以后就不会再服务它所load的tablet了。这些tablets
就成为了没有被分配了。为了确定bigtable集群不会由于master和chubby之间的网络问题而受到影响,所以如果master的session过期,那么master会kill自己,这并不会影响到tablet的分配关系。
当master被集群管理系统启动的时候,它需要知道tablet的分配关系,采取以下步骤:
1 获取chubby上的一把MASTER锁,以防止在并发情况下出现多个master实例
2 master扫描chubby上的servers目录来找到live的tablet servers
3 master与每台live的tablet server联系,以取到哪些tablet分配给了哪些tablet server
4 master扫描METADATA tablet,以发现还没有分配的tablet,并将其放入没有分配的tablet的列表中。
这里,如果在第三个步骤,master发现root tablet没有分配,就会把root tablet加入到未分配列表中,随后master将root tablet分配到某个tablet server上,
随后就可以坐第四步了。
存在的tablet的集合改变有四种状况:tablet创建,tablet删除,tablet合并,table分裂。
tablet能够跟踪到前三种改变,因为前三种改变时由master 发起的,最后一种改变是由tablet server发起的。
当tablet server分裂tablet的时候,它会将新的tablet的位置信息插入到METADATA tablet 中,然后通知master。万一这个通知丢失了,比如由于master挂了或者tablet server
挂了,the master tablet detects the new tablet when it asks a tablet server to load the tablet that has now split.The tablet server will notify the master of the split,because the table entry it finds in the METADATA table will specify only a portion of the tablet that the master asked it to load.
Tablet Serving
参看 http://www.nosqlnotes.net/archives/122 很详细
优化:
客户端可以指定多个column family 属于一个locality group,每个tablet中为每个locality group单独产生一个SSTable,将不常常会一起access的column family
放在不同locality group中会提高读性能。例如,网页的元数据,比如语言,校验和等可以在一个locality group,而网页的内容单独在一个locality group中。
locality group也可以被指定处于in-memory,被标识为in-memory的SSTable一旦被load进memory,那么访问属于这个locality group的column family就不需要查磁盘了。
这个机制被用于存放一些常用的数据,例如,google 将METADATA table中的location 这个column family 标识为in-memory。
caching for read performance
为了提高读性能,tablet server采用两个级别的缓存。
更高级别的Cache叫做Scan Cache,它缓存SSTable接口返回的key/value对。这个Cache对于会重复读数据的应用来说很有用。
更低级别的Cache叫做Block Cache,它会cache从SSTable中读取出来的block,这个Cache对 几次读取的数据离的比较近的数据比较有用(数据局部性原理)
Bloom Filters
如前所述,读操作需要读取组成该Tablet的所有的SSTable和memtable,那么这可能需要访问好多次磁盘,开销非常大。bigtable允许客户端指定bloom filter,
这个bloom filter用来判断某个SSTable中是否存在[指定行,指定列]相关的数据操作,对某些应用程序来说,用tablet server的一些内存来存放bloom filter
大大的提高了读性能。
Commit Log 实现
如果为每个Tablet使用一个commit log,那么会有很多文件被并行的写入GFS,根据GFS集群上机器本地的文件系统的实现来说,这会产生大量的磁盘seek。此外这种方法
也会降低group commit的作用,因为能合并的小的写操作会趋向于更小(因为对每个Tablet维护一个commit log,所有只有access同一个Tablet的操作才能被group)。
为了解决这些问题,我们在每台tablet server上使用一个commit log(commit log 还是写到GFS上),所以对于不同的Tablet的操作日志会写在同一个commit log上。
但是这种方法增加了恢复的复杂性,当某台tablet server挂了后,这台机器服务的tablets会被迁移到其它的tablet server上,而每台tablet server只能服务其中
的一小部分(因为每台tablet server可以服务上千个tablet,很多),新的tablet server恢复一个tablet,需要回放down掉的哪台tablet server机器记录的commit log,
但是这个commit log又包含了很多个tablet的commit log信息。一种方法是,将commit log全部读过来,然后扫描,只应用与需要恢复的tablet相关的log。但是下面这种情况下:
100台机器,每台机器恢复一个tablet,那么down掉的那台tablet server的commit log就需要读100次。
google通过对commit log进行按照<tablet,row name,log sequence id>进行排序来避免重复读的问题(这个排序不是写log的时候就排序,而是恢复tablet的时候才排序),
这样的话,来自同一个tablet的log 信息就是连续存放的,这样以后就可以seek一次磁盘后,连续读就ok。排序的过程进行了并行化,通过把commit log分为64MB大小的segment,
然后每台tablet server排序一个segment,排序的过程通过master进行协调。而排序过程的发起是由某一台需要恢复tablet的tablet server发起的(可以看出,发起给master,然后master进行协调)。
为了避免GFS集群中网络的情况或者load的情况带来的延迟或者性能上的脉冲,tablet server通常有两个写commit log的线程,每个线程都有自己的commit log,没一时刻只有一个
线程在写日志,当tablet server发现现在正在写的线程收到GFS的影响后,就会切换到另外一个线程去写(由于两个线程有各自的日志文件,当然日志文件在GFS上面的位置是不同的)
。因为每条log都有一个sequence number,所以回放日志的时候可以根据这个号忽略重复的log 记录。
加快tablet的恢复
在master迁移tablet从一台tablet server到另外一个tablet server的时候,源tablet server会先做一次minor compaction,这减少了需要回放log的数量,然后停止服务
tablets。由于做minor compaction的时候,还会有mutation操作,所以在这台tablet server unload这些tablet的时候,再做一次minor compaction,这样,另外一台tablet server
就不需要回放日志了。
不变性
SSTable是只读的,这样的话,就不需要将SSTable 的cache回写到磁盘。memtable是唯一可以被读写的数据结构,对它使用COW技术。
由于SSTable是不可变的,那么垃圾回收就比较容易,在METADATA table中将一个tablet的需要回收的SSTtable的信息写入到其对应的entry中,下次系统回收的时候就check这个标记。