并发写Btree原理剖析
OceanBase 0.4的UpdateServer存储引擎使用了一棵可以多线程并发修改的BTree,读写不冲突,由颜然 开发。线上运行稳定。
UpdateServer存储引擎采用类leveldb的方式,最近的更新操作都写入内存中的一个活跃memtable,当活跃memtable占用内存达到某个阈值时,即冻结,dump到磁盘上形成sstable,从而释放内存。然后会开启一个新的memtable供随后的写入。与leveldb不同的是,leveldb采用skiplist做为核心存储数据结构,而UpdateServer采用BTtree。
从需求上看,数据结构不需要支持物理删除,只需要在上层支持标记删除。翻看leveldb的skiplist,它也不支持删除,在不支持删除的情况下,skiplist很容易做到读写不冲突,只需要利用一些memory barrier。写写冲突还是有,需要外部进行同步。
同理,BTree也不支持删除, 支持插入更新,查询,节点可以分裂,不能合并。写操作基于读写锁+Copy On Write,读操作不用加锁,Copy On Write产生的老节点不立即释放,以保证读操作继续能读到老节点。
写操作流程
1. 从树根节点开始到达叶子节点,对所有的节点加上共享锁
2. 将叶子节点的共享锁升级为排他锁(锁结构用qlock表示),只有一个写线程可以升级成功,升级失败的写线程将搜索路径上所有节点的共享锁释放。
3. 升级成功的写线程检查叶子节点是否满,分两条路径:
3.1 如果不满:
3.1.1 将叶子节点A拷贝一份出来,新叶子节点记作B,然后往B中写入Key/Value对
3.1.2 修改父亲节点指针指向新的叶子节点B(有可能别的写线程由于分裂这个父亲节点的其他叶子节点导致需要分裂这个父亲节点,为了防止这种并发修改,分裂节点前需要加排他锁,修改指针需要加共享锁)
3.2 如果叶子节点满:
3.2.1 分配两个叶子节点记作C和D,将老叶子节点A的左半放入Copy到C,右半Copy到D中,同时插入输入Key/Value
3.2.2 升级父亲节点的共享锁为排他锁(如果两个写线程同时发现父亲节点需要分裂,那么只有一个写线程能够升级排他锁成功,升级失败的写线程会将自己已持有的
排他锁降级为共享锁,然后将所有的持有的共享锁都释放)
3.2.3 往父亲节点中put一个新的指针,以指向分裂后的新的叶子节点,这个put操作同时也需要递归的处理父亲节点分裂
3.2.4 put成功后,将当前节点的所有上层节点的共享锁从上往下依次释放,然后释放当前节点的排他锁。
5. 将叶子节点A加入到写操作的输入参数recycle_node中,写操作过程中所有的通过Copy On Write而遗留的老叶子节点都会加入进去,recycle_node内部是一个链表
6. 至此,写操作成功,将当前节点的所有上层节点的共享锁释放,将当前节点的排他锁释放。
内存回收
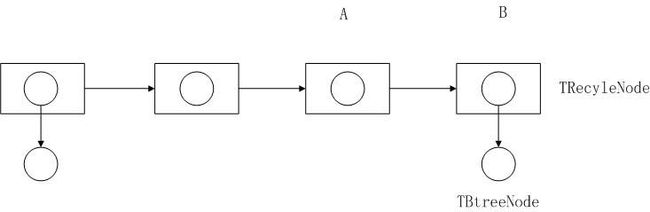
由于写操作采用Copy On Write的机制,所以每次成功的写操作都会替换下至少一个TBtreeNode节点,如上图,圆形的节点代表替换下来的TBtreeNode。每次写操作所有的替换下来的节点都用一个TRecycleNode节点管理起来,上图中的方形节点。全局只有一个这样的TRecycleNode链表,每次写操作开始都会从线程局部分配一个TRecycleNode,随后将替换下来的TBtreeNode全部纳入其中,最后写操作结束时,将TRecycleNode挂在链表的最右端,即尾部。
由于读操作不加锁,所以被某次写操作替换下来的TBtreeNode不能马上重用,因为这个节点可能正在被别的线程读。需要一种机制来从全局的TRecycleNode链表中回收不再被任何线程访问的TRecycleNode和TBtreeNode以重用。节约内存。
目前实现采用的机制比较特殊:全局有两个链表指针,一个指向链表头,一个指向链表尾。每次读写操作开始时,都需要对链表尾部节点加上引用计数。操作结束时,减引用计数。如上图中的TRecycleNode B,回收过程保证引用计数不为0的TRecycleNode及其内部的TBtreeNode不被回收或重用。由于只有写操作才需要分配TRecycleNode和TBaseNode,所以每次写操作结束后都会试图去全局TRecycleNode回收链表中去回收节点,实际上,只有线程发现线程局部可用节点数低于某个阈值才会去全局TRecycleNode回收链表中回收。
回收的过程就是去拿一把全局的锁,拿到了就可以进行回收:从链表头部开始检查回收TRecycleNode 引用计数为0的节点,一直回收到线程局部可用节点达到某个阈值上限。
显然,当TRecycleNode引用计数为0时,代表它及其内部的TBtreeNode不会再被任何线程访问,可以安全的回收。
具体实现中,这其中有一些需要注意的实现细节,不再赘述。这种方法某种程度上会影响写性能和内存突增,因为写操作结束后,回收内存的过程是多线程并发的,大家抢一把全局锁,只有抢锁成功的线程才能进行回收。没有抢到锁的线程不能回收任何节点内存到线程局部,导致后续该线程执行写操作时就需要从系统分配内存。后续将改进这个过程。
读操作全程不加锁,不赘述。
锁实现
以上描述的锁是通过qlock实现的,原理如下: