读Training Strategies for Improved Lip-Reading论文
标题:改善唇读的训练策略
关键词:数据增强、时间模型、训练策略、自蒸馏(self distillation)、DC-TCN、时间掩膜(time masking)、mixup、单词边界(word boundary)
摘要:
最近,在一系列独立的工作中,有人提出了几种训练策略和时间模型,用于孤立的单词唇读。然而,将最佳策略结合起来并研究它们各自的影响的潜力还没有被发掘出来。在本文中,我们系统地研究了最先进的数据增强方法、时间模型和其他训练策略的性能,如自我蒸馏和使用单词边界指标。我们的研究结果表明:时间掩膜(time masking)是最重要的增强方法,其次是混合(mixup),而密集连接的时间卷积网络(Densely-Connected Temporal Convolutional Networks,DC-TCN)是孤立词唇读的最佳时间模型。使用自蒸馏和单词边界也是有益的,但程度较低。综合上述所有方法,分类准确率为93.4%,比目前LRW数据集上最先进的性能绝对提高了4.6%。通过对更多的数据集进行预训练,性能可以进一步提高到94.1%。对各种训练策略的误差分析显示,通过提高难以识别的单词的分类准确率,性能得到了改善。
引言:
由于像LRW [1]这样的大型公开数据集的可用性,孤立词的唇读最近受到了很多关注。大多数作品遵循相同的唇读管道,包括视觉编码器,随后是时序模型和softmax分类层。由[2](Combining Residual Networks with LSTMs for Lipreading)提出的视觉编码器已经在大多数作品中被广泛采用,因此,最近的努力旨在改进时间模型或训练策略。双向门控循环单元(BGRUs)和多尺度时序卷积网络(MS-TCNs)是文献中最流行的时序模型,并且已经报告了关于它们的性能的矛盾结论。例如,MS-TCNs在[3](Lipreading Using Temporal Convolutional Networks)中的表现优于BGRUs,但在[4](Learn an Effective Lip Reading Model without Pains)中没有。类似地,已经提出了不同的数据扩充,如混合mixup[4,5],可变长度增强[3]和删减cutout[6](Can We Read Speech Beyond the Lips? Rethinking RoI Selection for Deep Visual Speech Recognition)。文献中提出的其他改进包括添加单词边界指示符(word boundary indicators)[7],它定义了视频中单词的开始和结束帧,以及自蒸馏[5](Towards Practical Lipreading with Distilled and Efficient Models),它通过蒸馏产生一系列具有相同架构的网络。所有这些改进都是在文献中单独提出的,并且缺少将所有这些改进结合起来并调查它们中每一个的影响的研究。
在这项工作中,我们提出了一个用一些最有前途的最新想法训练的模型,并通过消融研究评估了每个想法的贡献。这是一项有用的研究,因为当与其他增强方法或时间模型结合时,我们可以量化每种方法的效果。我们还提供了一个误差分析,展示了每种方法如何提高唇读的准确性。据我们所知,唯一存在的类似研究是[4],但尽管使用了一些最新的方法,它也只能与当前最先进的性能相匹配。
我们的结果表明:1)通过结合所有最新的数据增强方法,使用最近提出的DC-TCN、词边界指示符和自蒸馏,我们可以在LRW数据集上实现新的最先进的性能。单个模型的准确率为92.8%,集合的准确率为93.4%。通过在额外的数据集上进行预训练,性能可以分别略微提高到93.5%和94.1%。2)时间掩膜是最有效的增强方法,其次是混合。DC-TCN模型的使用明显优于MS-TCN模型,后者又优于BGRU模型。使用单词边界和自蒸馏也是有益的,前者导致更大的改进。3)误差分析表明,所有这些方法通过显著提高难词的分类精度来改善性能。
训练策略:
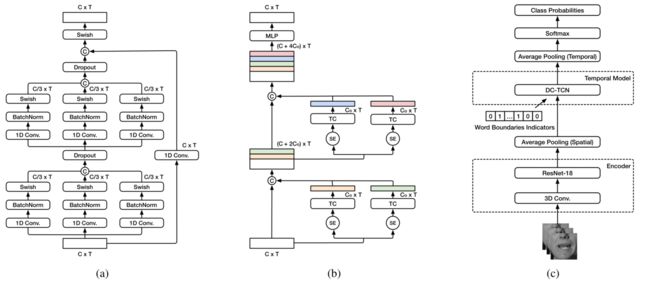
图1: (a): MS-TCN架构。“C”和“T”分别指通道号和序列长度。(二):DCTCN架构。SE和C分别表示压缩-激发(SE) [8]和通道级连接的操作。“T C”表示时间卷积块,而增长率表示为“Co”。(c)唇读模型,使用修改的ResNet-18作为编码器,使用DC-TCN作为时间模型。字边界指示符与编码器的输出特征连接在一起。
结构:
该模型的第一个构建模块(图1c)是最常用的嘴部感兴趣区域(ROI)编码器,由一个3D卷积层组成,它将5个连续帧作为输入,随后是2D ResNet-18 [2]。然后,来自编码器输出的逐帧特征被送到时序模型,以捕捉时间相关性。接下来是softmax层,它输出要分类的单词的分类概率。
在这项工作中,我们研究了三种不同的时序模型对孤立词识别的影响,BGRUs [9],MS-TCNs [3]和DC-TCNs [10]。TCNs由一堆时序卷积(TC)块组成,其中每个块由内核大小为k的几层扩展卷积组成。MS-TCN(图1a)通过添加多个具有不同内核大小的分支来扩展标准TCN,并且来自每个分支的输出的特征被连接以在几个时间尺度上混合信息。DCTCN(图1b)通过在每个TC块添加密集连接并使用压缩和激发(SE)注意机制来扩展传统TCN。
数据增强:
随机裁剪(Random Cropping):我们在训练时从口腔ROI中随机裁剪一个88 × 88的小块。在测试时,我们简单地裁剪中心补丁。这是一种常用的增强方法,已经在几个唇读作品中成功使用[3,9](End-to-end audiovisual speech recognition)。
翻转(Flipping):我们以0.5的概率随机翻转一个视频中的所有帧。这种增强通常与随机裁剪结合使用[3,9]。
混合(mixup):我们通过线性组合两个输入视频序列及其相应的标签来创建新的增强训练示例。类似于[5],我们将线性组合权重λ设置为0.4。
时间掩膜(Time Masking):我们屏蔽每个训练序列的N个连续帧,其中使用均匀分布在0和Nmax之间采样N。每个被屏蔽的帧被它所属的序列的平均帧替换。这种增强是基于SpecAugment [11](SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition)的,SpecAugment是为ASR应用提出的,旨在使模型对具有丢失帧的小段更加鲁棒。
单词边界:
在[4,7]之后,我们添加单词边界指示符作为时间模型的额外输入。指示符基本上是二进制向量,其长度与输入视频中的帧数相同。对应于存在目标单词的帧的所有向量条目被设置为1,其余的被设置为0。单词边界指示符的向量与来自编码器的逐帧视觉特征连接,并且新的向量被馈送到时间模型中。
自蒸馏:
自蒸馏[13](Born-again neural networks)基于使用蒸馏训练一系列具有相同架构的模型的思想,并且最近已经被应用于唇读[5]。具体来说,我们首先训练一个充当教师的网络,用于训练具有相同架构的学生模型。学生网络在下一次迭代中成为教师网络,我们保持训练模型,直到没有观察到改进。这背后的见解是,教师网络提供了额外的监督信号与类别间相似性信息。要优化的总损失L是hard-target的交叉熵损失LCE和soft-target的Kullback-Leibler (KL)发散损失LKD的加权组合。其中zs和zt表示来自学生和教师网络,θs和θt分别表示学生和教师模型的可学习参数,y是目标标签,δ(.)代表softmax函数,α是两项之间的平衡权重。
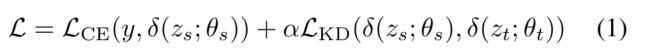
实验设置:
数据集:
在我们的实验中,我们采用LRW [1],这是最大的公开可用的孤立单词唇读数据集。该数据集以短片的形式收集自BBC节目中的1 000多名演讲者,包含500个孤立的单词。每个剪辑的时间长度为29帧(1.16秒)。孤立的单词在剪辑中居中。数据集由训练集、验证集和测试集中的488 766,25 000和25 000个短片组成。
预处理:
我们使用RetinaFace [14](RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild)跟踪器来检测面部,使用面部对齐网络(FAN) [15]来检测标志。通过将人脸配准到训练集中的平均人脸来消除大小和旋转差异。使用96 × 96的边界框来裁剪嘴部感兴趣区域。通过减去均值并除以训练集的标准差来标准化每一帧。
训练细节:
该模型被训练80个Epoch,最小批量大小为32。我们使用AdamW优化器[16],初始学习速率为3e-4。在没有预热阶段的情况下,使用余弦退火策略来衰减学习速率。我们还在所有实验中使用可变长度增广法。时间掩膜中使用的Nmax值(见第2节)设置为15帧(0.6秒),并在LRW验证集中进行了优化。
时序模型:
MS-TCN:我们采用与[3]中相同的MS-TCN体系结构,即每个块分别由3个3/5/7核大小的分支组成,我们堆叠4个这样的块以形成MS-TCN网络。
DC-TCN:本文中使用的DC-TCN通常遵循[10](Lip-reading with Densely Connected Temporal Convolutional Networks)中的结构。特别地,我们在每个TC块中选择部分密集(PD)架构,而每个块由9个密集连接的时间卷积组成,核大小为{3,5,7},膨胀率为{1,2,5}。
BGRU:具有0.2的随机失活率的四层BGRU与1024个隐藏单元一起使用。
初始化:
为了研究初始化的影响,我们考虑三种情况:
1)我们仅使用LRW训练集从头开始训练模型,
2)我们使用LiRA [12](LiRA: Learning Visual Speech Representations from Audio Through Self-Supervision)自监督方法在LRS3数据集[17]上预先训练图1的编码器,并在LRW训练集上对其进行微调。
3)我们在LRS2、LRS3和AVspeech数据集上对编码器进行预训练,如[18](Visual Speech Recognition for Multiple Languages in the Wild)中所述。
结果:
消融研究:
消融研究的结果如表1所示。通过一次移除一个增强,我们可以估计它对最终模型的贡献。我们看到时间掩膜是最重要的增强,导致了2.4%的绝对下降,随后是1.1%的混合下降。通过用MS-TCN替换DC-TCN,我们观察到性能下降了2.1 %,这证明了DC-TCN中密集连接和se注意机制的重要性。用BGRU替换DC-TCN,性能下降2.4%。此外,删除单词边界指示符会使性能下降1.7 %,这证明了包含辅助边界指示符的好处。最后,我们在LRS3 / LRS2、LRS3和AVspeech数据集上以自监督/监督的方式预训练编码器,然后在LRW训练集上微调模型,这将性能略微提高到92.3 % / 92.9 %。从表3中可以清楚地看出,所提出的模型明显优于当前最先进的模型。
表1:LRW数据集上三个时间模型的消融研究。从表现最好的DC-TCN模型开始,我们移除每个数据扩充和单词边界指标来检查它们的有效性。然后,我们用MS-TCN和BGRU替换DCTCN。“Scratch”表示不使用外部数据从零开始训练的模型。“LiRA(LRS3)”表示在LRS3数据集上使用LiRA [12]的自我监督预训练模型,而“LRS2&3+A VS”表示在LRS2、LRS3和VSpeech上的完全监督预训练模型。
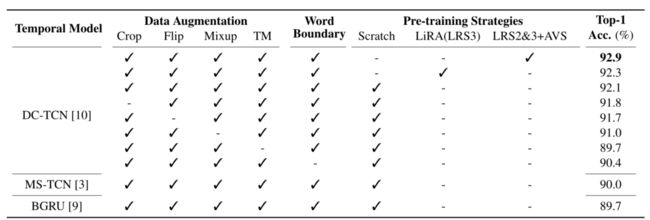
表3:在分类精度方面与LRW数据集上最先进方法的比较。实验分为两组,分别使用和不使用单词边界指示器。“S.D .”:自蒸馏。“Scratch”、“LiRA(LRS3)”和“LRS2&3+AVS”对应表1中的三种预训练策略。

自蒸馏:
自蒸馏实验的结果列于表2。我们使用表1中最好的两个模型作为第一轮的教师。显然,自蒸馏在所有情况下都导致0.6 %至0.7 %的绝对改善。此外,所有模型(所有学生+教师)的集合导致0.6 %的进一步绝对改进。这些结果表明,自蒸馏有益于唇读。然而,我们应该指出,与[5]相比,改进较小,这可能是由于更好的教师模型使得进一步的改进更加困难。
表2:自蒸馏模型的性能(教师=ResNet-18 + DC-TCN)。表1中表现最好的模型在第一排担任教师。对于每个学生模型,上面那行的模型作为它的老师,“学生i”代表第i次自蒸馏迭代后的模型。
错误分析:
为了更好地理解所提出的模型如何提高单词分类的准确性,我们进行了一些误差分析。我们将LRW数据集中的测试样本分为五组[10]。每组包含100个不同的孤立单词,并且是基于[9]中的模型的单词准确性创建的。具有最高分类准确度的100个单词被分组在“非常容易”组中,接下来的100个单词被分组在“容易”组中,以此类推。每组的平均分类精度如图2所示。为了比较,我们还包括[3]和[9]的性能。我们可以看到,我们的模型在所有组中都优于两个基线,并且在“困难”和“非常困难”组中改善更明显。
图2:我们的方法和两种基线方法((End-to-End AVR[9]和MS-TCN [3])在LRW测试集的五个难度组上的比较。

结论:
在这项工作中,我们对LRW数据集在数据增强和时间模型方面进行了详细的研究,并证明了如何通过结合最佳增强和训练策略来实现最先进的性能。我们表明,时间掩码是最重要的数据增强方法,其次是混合。我们还表明,DC-TCNs比MS-TCNs或BGRU的性能更好。使用自蒸馏和单词边界指标进一步提高了分类精度,而使用预训练则导致了轻微的改善。最后,错误分析显示,所提出的模型大大改善了难以识别的单词的分类准确性。