基于机器学习的阿里智能助理在电商领域的架构搭建与实现
在2016杭州云栖大会的“开发者技术峰会”上,来自阿里巴巴的高级技术专家陈海青带来了题为《基于机器学习的阿里智能助理在电商领域的架构构建与实践》。本次分享主要包括阿里小蜜平台介绍、智能人机交互构建技术实践、挑战与未来三部分。
以下内容根据演讲PPT及现场分享整理。
阿里小蜜平台介绍
当今人工智能的领域是从感知到认知领域发展,将会带来拟人化体验的提升;同时,这也会带来行业模式的变化,应用领域成本的降低。现阶段,自然语言交互型的私人助理已经成为人工智能的热点领域之一,如微软的小冰、苹果的Siri等,未来更是会成为入口级领域,各大公司竞争必将十分激烈。

目前阿里推出了电商领域的私人助理——阿里小蜜,它基于阿里海量消费数据,结合线上、线下的生活场景需求,以智能+人工的模式提供智能导购、服务、助理的业务体验。目前阿里形成了两个大的生态圈:一个是买家卖家的生态圈;另一个是钉钉企业级生态圈。因此阿里对应地在电商领域的两种平台化开放:商家开放——千牛平台、企业开放——钉钉平台。

上图是阿里小蜜及平台输出的展示页面,最左侧是阿里小蜜;中间是店小蜜,用于商家店铺,目前几个较大流量的商家已经部署;最右侧是企业钉小蜜。
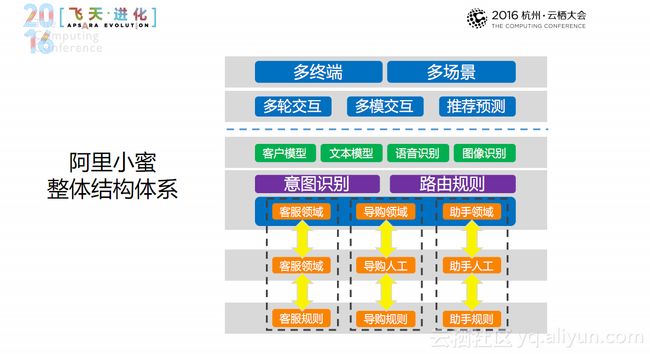
阿里小蜜的整体结构体系如上图所示,架构采用水平切分的方式:虚线上侧是前端部分,主要的任务是多终端部署和多场景识别以及多轮交互、多模交互、推荐预测;虚线下侧涉及到多种模型,如客户模型、文本模型、语音识别、图像识别;最底层分为三个领域:客服领域、导购领域和助手领域。

上图是阿里小蜜平台,其中输出平台目前包括:阿里小蜜、千牛店小蜜、钉钉企业小蜜;服务层按照领域划分为服务、导购、物流、聊天和其他;中间的技术层包含多轮交互、多模交互、推荐预测、用户模型等;数据层用于数据回流和机器学习训练以及数据挖掘、多维数据分析等。
智能人机交互构建技术实践
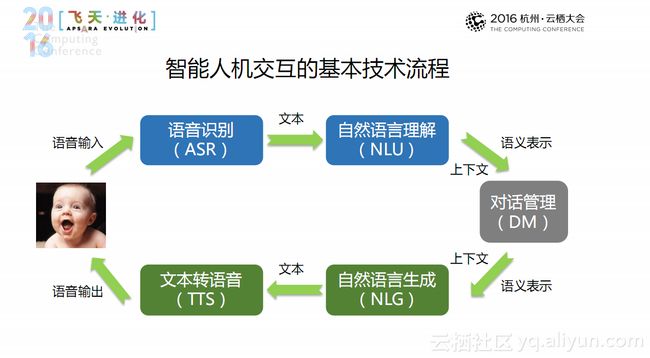
上图是通用的智能人机交互的基本技术流程:语音输入之后进行语音识别(ASR),转成文本的方式进行自然语言理解(NLU);再通过语义表示和上下文进入对话管理(DM);此后根据上下文和语义表示进行自然语言生成(NLG);再将生成的文本转语音(TTS)输出给用户。

可以将简单的一问一答按领域拆解为语义识别和对话匹配两部分。由于意图非常复杂,因此需要进一步拆分。在对话领域中,可以按照面向目标和非面向目标拆分,例如“我要订一张机票”这类的问题就属于面向目标型,而“我心情不好”这类的输入就属于非面向目标型。意图又可以分为明确意图和隐式意图,例如“我心情不好”这个输入的意图是隐式的、不明确的。总结来看,在意图层面的领域模型拆解时会分为面向目标、非面向目标和明确意图、隐式意图,不同的领域有着各自不同的技术选型和算法方案。
在问答匹配流程中,可以划分为三个类型:问答型,一问一答,通常需要知识输入,如“密码忘记怎么办?”;任务型,例如“我想订一张明天从北京到杭州的机票”;语聊型,例如“我心情不好”。
语义意图
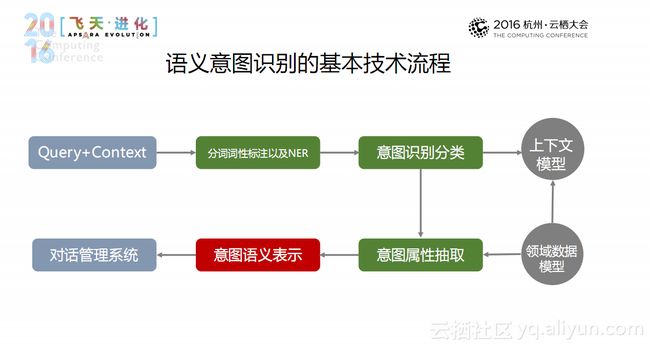
语义意图识别的基本技术流程如上图所示:输入是Query+Context;之后进行自然语言的基本处理,进行分词词性标准及NER;在对话管理中,需要数据沉淀与积累,因此需要上下文模型和领域数据模型;在整个技术流程中,意识识别分类和意识属性抽取是其中的重头戏;最后通过意图语义表示再输出给对话管理系统。
下面来具体看下技术选型和技术架构的思考。

如果构建的是相对简单对话系统,采用传统的机器学习方法即可,这里不再详细阐述。传统的方式由于部分情况用户的意图表述的并不清楚,在进行文本标注、分类时会丢失大量信息。基于深度学习以及结合用户行为可以解决传统方式无法完成的难题,这种方式适用于较大数据量积累场景:采用结合用户行为特征的深度学习意图预测模型,在文本缺失、不明确或者不完整的情况下,增加用户行为特征进行意图分类预测。

深度学习模型需要大量意图数据积累,数据必须保证相关性和多样性:
- 相关性方面:通过初步建模,匹配用户问句和知识点标题的相似度以及用户问句和历史问句的相似度建立相关性维度;
- 多样性方面:通过数据分布的维度保证多样性,常采用的方法是:随机展示(均匀采样)和按历史的知识点使用频次来推荐。

用户点击数据结合用户相关特征、用户行为序列、Query+Context构建成深度学习模型。

上图是两种深度学习模型的实现方案。第一种方案是多分类的方案,将因子+行为相关的用户特征构建成N,文本特征构建成V;再将这两个维度的特征向量化;之后在中间层简单地将两个向量进行拼接;最后再通过Softmax进行多分类;第二种方案的底层操作和第一种方案完全相同,两者的不同之处在于后者采用多个二分类。
第一种方案的优点是性能很快,但如果分类不稳定时,会直接导致成本的增加;第二种方案隐层的分类是可以复用的。
四种主流的问答匹配技术
在人工交互对话领域,问答匹配技术主要分为:基于模板式匹配(Rule-Based)、基于检索的模型(Retrieval model)、基于统计机器翻译模型(SMT)、基于深度学习模型(Deep leaning)四类。在实际实践中,根据不同分策略模块分别进行技术选型:
- 问答型采用基于知识图谱+传统检索模型的方式;
- 任务型采用的是Slots Filling;
- 语聊型采用的是传统检索模型+Deep Learning方式。
问答型领域技术构建

问答型领域首先需要构建知识图谱,知识图谱构建的第一步需要进行语义挖掘,语义挖掘又分为同义语义挖掘和词和短语挖掘,在同义语义挖掘中会采用文本相似度计算、潜在语义分析、聚类等相关技术;词和短语挖掘通过种子词获取、深度挖掘;此外,还可以通过Pattern构造模板匹配。

上图是知识图谱的构建体系,主要分为词和短句两个维度。这里采用了主题模型不断地进行模型构建,构建成短句库或实体库放到词数据库或索引中使用。

构建完成的知识图谱示例图如上所示,该示意图由实体—关系—实体的RDF三元组构成,天然支持实体间上下文与推理;同时,把核心知识的维护带给业务的成本降到最小,不需要维护复杂相似问法,通过技术挖掘生成可扩展图结构。该知识图谱精确匹配率相比之前的机器人匹配模型提升10%,用户体验得到进一步提升。
但该结构也存在一定的缺点:在模型构建初期会损失一定的覆盖率。
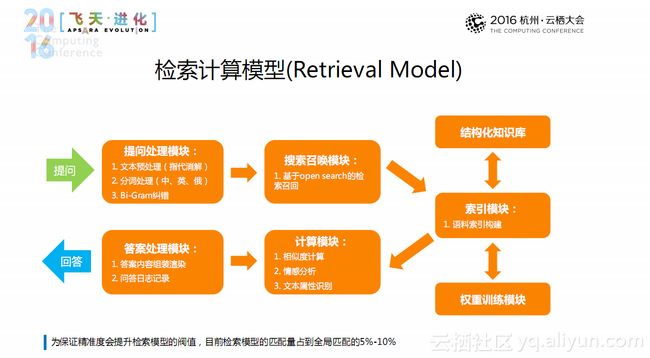
知识图谱构建完成后也可以用在检索计算模型中,上图是经典的检索计算模型架构,主要分为提问处理模块、搜索召唤模块、索引模块、计算模块、答案处理模块。为保证精准度会提升检索模型的阀值,目前检索模型的匹配量占到全局匹配的5%-10%。
任务型领域技术构建

任务型领域构建主要采用Slots Filling的方式,首先需要构建领域意图树,例如检索到输入“机票”:首先需要确定是否是“购买”行为;再确定对应的“出发地”、“到达地”、“时间”等信息。第二步通过Slots Filling的方式在Query中slot属性的抽取;之后进行获取意图树的属性进行填充,填槽之后判断意图树种填写状态;根据设定的状态结果进行返回,进行不断判断、填充、转移和完结。
语聊型领域技术构建
语聊型领域技术构建采用了传统检索模型+Deep Learning两种方案相结合的方式,这是因为传统的检索模型的答案跳不出知识图谱语料库;而Seq2Seq模型(Deep Learning模型)序列化生成的答案尽管跳出了知识图谱语料库的限制,但答案的合理性和语言的连贯性存在明显问题。
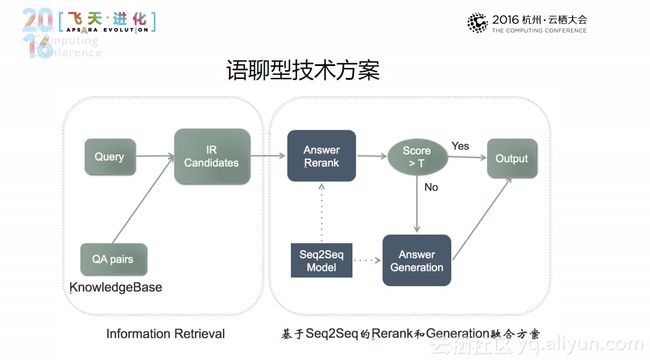
语聊型领域技术并非简单地将在传统检索模型和Deep Learning进行结合,其具体方案如图所示。左侧模块是传统的检索模型,将IR模型作为候选结果,对搜索答案进行二次排序。具体来说是先通过搜索的方式找到一百条答案;这一百条答案通过检索模型本身进行排序;之后在通过Seq2Seq模型对答案基于语义维度重新进行排序,如果最后的分值大于置信度阀值,则认为答案合理,可以用于回答;如果分值不高,再通过深度学习模型进行答案生成。
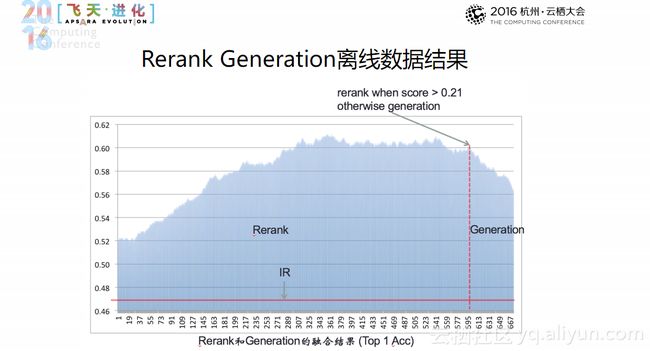
上图是Rerank Generation离线数据结果图,横轴是数据集。从图中可以看出:80%的结果选型是Rerank方式;20%的结果选型是Generation;置信度阀值为0.21。
挑战与未来
尽管人工智能领域发展十分迅速,但目前智能人机交互机器人的智能程度还比较低,还有很长一段路要走;同时工业领域由于设计的领域及复杂度情况很多,需要进行不断的细分并通过不同的方案来解决。
展望未来,人工智能交互技术领域知识体系的不断构建完善,以及与Deep Learning更好的结合与发展是未来一段时间的方向;同时,随着学术界和工业领域的不断紧密结合,未来人机交互会在更多的场景被应用,并且会进一步提升。