爬虫学习笔记
目录
一、 初识爬虫
1. 简单的爬虫
2. web请求
3. http协议
4. requests入门
二、数据解析与提取
1. 概述
2. Regular Expression 正则表达式
3. re模块
4. 豆瓣电影练习
5. 电影天堂练习
6. bs4 北京新发地、热搜榜
7. 抓取图库图片
8. Xpath语法
9. xpath猪八戒网练习
三. request模块进阶
2. 防盗链处理
3. 代理
4. 爬取网易云音乐评论
四. 多线程
1. 多线程的两种写法
2. 多进程
3. 线程池和进程池
4. 抓取新发地菜价
5. 多任务异步协程
6. aiohttp模块
7. 抓取一本电子书
8. 抓取一部视频
五、selenium
1. 拉钩网
2. 页面切换
3. 无头浏览器
4. 破解验证码并登录
5. 12306
六. 数据存储
1. json
json的保存
json的读取
2. csv
3. mysql
一、 初识爬虫
1. 简单的爬虫
from urllib.request import urlopen
url = "http://www.baidu.com/"
resp = urlopen(url)
message = resp.read().decode("utf-8")
print(message)
with open("my_spyder.html", mode="w", encoding="utf-8") as f:
f.write(message)
print("over!")
open的时候要指定encoding是utf-8,windows系统默认gbk,会乱码。
baidu网址输入的时候注意是http,没有s。
2. web请求
1.服务器渲染:再服务器那边直接把数据和html整合在一起,统一返回给浏览器
再页面源代码中能看到数据
2.客户端渲染:第一次请求html骨架,第二次请求数据。进行数据展示
在页面源代码中看不到数据
熟练使用浏览器抓包工具 f12里看
3. http协议
请求:
- 请求行:包括请求方式,请求url地址,协议
- 请求头:放一些服务器要使用的附加信息
- 请求体:一般放一些请求参数
响应:
- 状态行:协议 状态码
- 响应头:放一些客户端要使用的一些附加信息
- 响应体:服务器返回的真正客户端要用的内容
请求头重最常见的一些重要内容:
- User-Agent:请求载体的身份识别(用什么发送的请求)
- Referer:防盗链(这次请求从哪个页面来?反爬用到)
- cookie:本地字符串数据信息(用户登录信息,反爬的token)
响应头重一些重要的内容:
- cookie:本地字符串数据信息
- 各种神奇的莫名其妙的字符串(需要经验,一般都是token字样,防止各种攻击和反爬)
请求方式:
- GET: 显式提交
- POST: 隐式提交
4. requests入门
import requests
url = "https://www.sogou.com/web?query=周杰伦"
resp = requests.get(url)
print(resp)此处用vscode一直报错无法找到requests,换用pycharm可以使用,输出为200.
不知道为什么。
print(resp.text)输出页面后被拦截,因为被检测到是自动程序发出的。
打开指定页面,审查元素找到User-Agent复制过来。用来伪装成正常访问请求。
url = "https://www.sogou.com/web?query=周杰伦"
dic = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
}
resp = requests.get(url, headers=dic)修改请求头。
审查元素可以看到用的是post还是get。
百度翻译使用的是get。使用英文输入法输入单词,在network中监视,找到sug,发现翻译是通过https://fanyi.baidu.com/sug实现,并且使用的是GET。
找到form-data为输入的表单信息,因此只要替换form-data就可以实现自定义输入。
import requests
url = "https://fanyi.baidu.com/sug"
s = input("输入需要翻译的英文单词:")
dat = {
"kw": s
}
# 发送post请求,发送数据必须放在字典中
resp = requests.post(url, data=dat)
print(resp.json()) # 将服务器返回的内容直接返回为json() =>字典直接resp.text会出现乱码,用json可以解释成字典。
请求url太长可以考虑封装
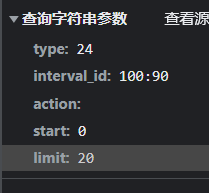 这些内容都包含在url里。
这些内容都包含在url里。
url = "https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action="重新封装
url = "https://movie.douban.com/j/chart/top-list"
# 重新封装参数
param = {
"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20
}
requests.get(url=url, params=param)
print(resp.text)如果发现异常,说明可能被挡了,优先考虑user-agent。添加后就可以了
import requests
url = "https://movie.douban.com/j/chart/top_list"
# 重新封装参数
param = {
"type": "24",
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 20
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
}
resp = requests.get(url=url, params=param, headers=headers)
print(resp.json())二、数据解析与提取
1. 概述
本课程提供三种解析方式:
- re解析,运行最快
- bs4解析,最简单,但效率不高
- xpath解析,比较流行,写起来简单
2. Regular Expression 正则表达式
上手难度高。速度快,效率高,准确性高。
正则的语法:使用元字符进行排列组合用来匹配字符串
语法测试网站:开源中国-正则表达式测试
常用元字符
每个元字符默认只匹配一个字符串。
. 匹配除换行符以外的任意字符
\w 匹配字母数字下划线
\s 匹配任意空白符
\d 匹配数字
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配字符串的开始(开始的时候必须符合要求
$ 匹配字符串的结尾(结尾的时候除了要求,不能有别的
\W 匹配非字母数字下划线
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符a或字符b
() 匹配括号内的表达式,也表示一个组
[...] 匹配字符组中的字符
[^...] 匹配除了字符组中字符的所有字符
量词:
控制前面的元字符出现的次数
* 重复零次或多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
.* 贪婪匹配(尽可能多的匹配)
.*? 惰性匹配(尽可能少的,可以理解为就近匹配)
3. re模块
# findall: 匹配字符串中所有的符合正则的内容,返回的是列表 不常用
lst = re.findall(r"\d+", "我的电话号码是:123, 我朋友的电话:456")
print(lst)
# finditer: 匹配字符串中所有的内容,返回的是迭代器
it = re.finditer(r"\d+", "我的电话号码是:123, 我朋友的电话:456")
print(it)
for i in it:
print(i.group())
# search,全文匹配,找到一个结果就返回 返回的是match对象,拿数据需要.group()
s = re.search(r"\d+", "我的电话号码是:123, 我朋友的电话:456")
print(s.group())
# match是从头开始匹配
s = re.match(r"\d+", "123, 我朋友的电话:456")
print(s)
# 预加载正则表达式 返回迭代器
obj = re.compile(r"\d+")
ret = obj.finditer("123, 我朋友的电话:456")
for it in ret:
print(it.group())
ret = obj.findall("今天100000度")
print(ret)# (?P<分组名>正则) 可以单独从正则匹配的内容中进一步提取内容
obj = re.compile(r"(?P.*?) ", re.S)
# re.S 让.能匹配换行符
result = obj.finditer(s)
for it in result:
print(it.group("number"))
print(it.group("id"))()相当于隔开,c语言里的大括号。
?P
4. 豆瓣电影练习
import requests
import re
import csv
url ="https://movie.douban.com/top250"
dic = {
"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Mobile Safari/537.36 Edg/98.0.1108.56"
}
resp = requests.get(url, headers=dic)
page_content = resp.text
# 解析数据
obj = re.compile(r'.*?.*?(?P.*?)'
r' .*?.*?
(?P.*?) '
r'.*?'
r'.*?(?P.*?)人评价 ', re.S)
# 开始匹配
result = obj.finditer(page_content)
f = open("data.csv", mode="w", encoding="utf-8")
csvwriter = csv.writer(f)
for it in result:
# print(it.group("name"))
# print(it.group("year").strip())
# print(it.group("score"))
# print(it.group("aud_num"))
dic = it.groupdict()
dic['year'] = dic['year'].strip()
csvwriter.writerow(dic.values())
resp.close()
5. 电影天堂练习
1. 定位到2022必看片
2. 从2022必看片中提取子页面的链接地址
3. 请求子页面的链接地址,拿到所需的下载地址
import re
import requests
domain = "https://dytt89.com/"
resp = requests.get(domain, verify=False)
resp.encoding = 'gb2312' # 审查元素找到mata后,指定字符集
# print(resp.text)
# 那到ul里面的li
obj1 = re.compile(r"2022必看热片.*?(?P.*?)
", re.S)
obj2 = re.compile(r".*?)
.*? '
r'', re.S)
result1 = obj1.finditer(resp.text)
child_href_list = []
for it in result1:
ul = it.group('ul')
# 提取子页面连接
result2 = obj2.finditer(ul)
for itt in result2:
# 拼接子页面的url地址: 域名+子页面地址
child_href = domain + itt.group('href').strip('/')
child_href_list.append((child_href))
# 提取子页面内容
for href in child_href_list:
child_resp = requests.get(href, verify=False)
child_resp.encoding = 'gb2312'
result3 = obj3.search(child_resp.text)
print(result3.group("movie"))
print(result3.group("download"))
resp.close()
6. bs4 北京新发地、热搜榜
1. 拿到页面源代码
2. 使用bs4进行解析,拿到数据
import requests
import re
from bs4 import BeautifulSoup
import csv
# 原网址有变化,用之前的方法可以提取
#
# url = "http://www.xinfadi.com.cn/getPriceData.html"
# resp = requests.get(url)
# obj = re.compile(r'.*?"prodName":"(?P.*?)","prodCatid".*?')
#
# result = obj.finditer(resp.text)
# for it in result:
# dic = it.groupdict()
#
# print(dic['name'])
# 视频教程方法
# 使用微博热搜榜
url = "https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6"
dic = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.56",
"cookie": "f12 复制"
}
resp = requests.get(url, headers=dic)
f = open("resou.csv", mode="w", encoding="utf-8")
csvwriter = csv.writer(f)
# print(resp.text)
# 解析数据
# 1. 把页面交给BeautifulSoup进行处理,生成bs对象
page = BeautifulSoup(resp.text, "html.parser") # 指定html解析器
# 2. 从bs对象中查找数据
# find(标签, 属性=值)
# find_all(标签, 属性=值)
tbody = page.find("tbody") # 括号里可以加上 attr={"class":""}指定
# 拿到所有数据
trs = tbody.find_all("a")[1:] # 一层层套
for tr in trs: # tr为每一行数据
name = tr.text
csvwriter.writerow([name])
f.close()
resp.close()
7. 抓取图库图片
1. 拿到主页源代码,然后提取子页面连接,href
2. 通过href拿到子页面内容,找到 img->src
3. 下载图片
import requests
from bs4 import BeautifulSoup
import time
url = "https://www.umeitu.com/bizhitupian/weimeibizhi/"
resp = requests.get(url)
resp.encoding = "utf-8"
main_page = BeautifulSoup(resp.text, "html.parser")
alist = main_page.find("div", class_="TypeList").find_all("a")
for a in alist:
href = a.get('href')
# 拿到子页面源代码
child_page_resp = requests.get("https://www.umeitu.com"+href)
child_page_resp.encoding = "utf-8"
child_page_text = child_page_resp.text
# 从子页面中拿到下载路径
child_page = BeautifulSoup(child_page_text, "html.parser")
p = child_page.find("p", align="center")
img = p.find("img")
src = img.get("src")
# 下载图片
img_resp = requests.get(src)
pic = img_resp.content #这里是字节
img_name = src.split("/")[-1] # 拿到url最后一个/以后的内容
with open("img/"+img_name, mode="wb") as f:
f.write(pic) # 图片内容保存文件
print("complete", img_name)
time.sleep(1)
img_resp.close()
child_page_resp.close()
resp.close()

点excluded后,该文件夹不会进入索引。提高pycharm速度
8. Xpath语法
Xpath是XML文档中搜索内容的一门语言
html是xml的一个子集

安装lxml模块
Title
李嘉诚
胡辣汤
from lxml import etree
tree = etree.parse("b.html")
# result = tree.xpath("/html")
# result = tree.xpath("/html/body/ul/li/a/text()")
# result = tree.xpath("/html/body/ul/li[1]/a/text()") # 顺序从1开始数
# result = tree.xpath("/html/body/ol/li/a[@href='dapao']/text()") # [@xxx=xxx] 属性筛选
ol_li_list = tree.xpath("/html/body/ol/li")
for li in ol_li_list:
# 从每一个li中提取到文字信息
result = li.xpath("./a/text()") # 在li中继续去寻找。相对查找
print(result)
result2 = li.xpath("./a/@href")
print(result2)
print(tree.xpath("/html/body/ul/li/a/@href"))
print(tree.xpath("/html/body/div[1]/text()"))
print(tree.xpath("/html/body/ol/li/a/text()"))
9. xpath猪八戒网练习
1. 拿页面源代码
2. 提取和解析数据
import requests
from lxml import etree
url = "https://beijing.zbj.com/search/f/?kw=saas"
resp = requests.get(url)
# 解析
html = etree.HTML(resp.text)
# 拿到每一个服务商的dib
divs = html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div")
for div in divs:
## '//*[@id="utopia_widget_76"]' == /div/div id在网页中应该是唯一的
price = div.xpath("./div/div/a[2]/div[2]/div[1]/span[1]/text()")[0].strip("¥")
title = "saas".join(div.xpath("./div/div/a[2]/div[2]/div[2]/p/text()")) # 因为搜索的部分高亮被跳过,一定是saas,所以用saas连接
com_name = div.xpath("./div/div/a[1]/div[1]/p/text()")[1].strip("\n\n")
location = div.xpath("./div/div/a[1]/div[1]/div/span/text()")[0]
print(title)
resp.close()
三. request模块进阶
模拟浏览器登陆 -> 处理cookie
防盗链处理 -> 抓取梨视频数据
代理 -> 防止被封ip
1. 模拟用户登录 cookie
登录 -> 得到cookie
带着cookie 去请求到书架url -> 书架上的内容
必须把上面的操作连起来
可以使用session进行请求 -> session可以认为是一连串的请求,在这个过程中的cookie不会丢失
没有书架的网站账号,用了99166网站的。
尝试用xpath一直没抓出来,网站结构写的太乱糟糟了,标签没有class,直接硬怼的属性。所以用了bs4提取。结构实在是乱,太乱了。
import requests
from bs4 import BeautifulSoup
# 会话
session = requests.session()
data = {
"username": "xxx",
"password": "xxx"
}
# 1. 登录
url = "http://www.99166.com/login.asp?action=chk"
session.post(url, data=data)
# 2. 拿数据
# session里有cookie
resp = session.get("http://www.99166.com/user/cesuanlog.asp")
resp.encoding = "gbk"
# print(resp.text)
page = BeautifulSoup(resp.text, "html.parser")
tds = page.find_all("td", attrs={"width": "320", "align": "center"})
for td in tds:
a = td.find("a")
if a != None:
print(a.text)
resp.close()
结果:

2. 防盗链处理
梨视频网页中的视频链接,和审查元素中找到的链接不同,审查元素中的链接无法访问。
找规律
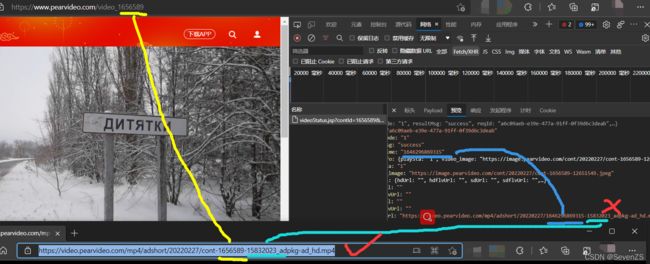
通过拼接的方式找到视频下载地址
1. 拿到contIs
2. 拿到videoStatus返回的json. -> srcURL
3. srcURL里面的内容进行修整
4. 下载视频

referer防盗链,意思是溯源后的上级,必须是xxx才是正常的。加上去就好了。

找到页面后通过json()返回字典,可以在页面审查直接看,比较清晰。
import requests
url = "https://www.pearvideo.com/video_1656589"
contId = url.split("_")[1]
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62",
# 防盗链:溯源
"Referer": url
}
videoStatusUrl = f"https://www.pearvideo.com/videoStatus.jsp?contId={contId}&mrd=0.8691664046016876"
resp = requests.get(videoStatusUrl, headers=headers)
dic = resp.json()
srcUrl = dic['videoInfo']['videos']['srcUrl']
systemTime = dic['systemTime']
srcUrl = srcUrl.replace(systemTime, f"cont-{contId}")
# 下载视频
with open("a.mp4", mode="wb") as f:
f.write(requests.get(srcUrl).content)
resp.close()
3. 代理
通过第三方的一个机器去发送请求
import requests
# 220.133.119.75:3128
proxies = {
"https": "https://220.133.119.75:3128"
}
resp = requests.get("https://www.baidu.com", proxies=proxies)
resp.encoding = "utf-8"
print(resp.text)
resp.close()
4. 爬取网易云音乐评论
页面源代码和框架源代码都没有数据。


发现表单数据加密

1. 找到未加密的参数
2. 想办法把参数进行加密(必须参考网易的逻辑) params, encSecKey
3. 请求到网易,拿到评论
如何加密的?

从下往上调用,最上面一个是发送。点击。

点左下角

这一行是发送数据。设置断点后刷新。

找到发送的参数。
url = "https://music.163.com/weapi/comment/resource/comments/get?csrf_token="
需要的是get,但是这里是cdns,因此放开,进行下一次拦截,直到出现get。
不知道为什么edge一直失败,换了chrome可以。

发现params不是人类能读懂的,因此在call stack里找怎么加密的。

一个个点开,看params什么时候能看懂。

发现在这里还是正常的,在t0x.be0x后加密了。

找到加密函数

i0x为加密前,data为加密后

i0x里面的内容为真正的参数
一行行往下跑。

bVj0x为加密后的内容。 名字可能不固定。

搜索window.asrsea,发现只有2个地方使用。


找到加密过程。带走。
function d的参数找到
var bVj0x = window.asrsea(JSON.stringify(i0x), bsR5W(["流泪", "强"]), bsR5W(Xp7i.md), bsR5W(["爱心", "女孩", "惊恐", "大笑"]));
function d(d, e, f, g)
对照看
d: 数据
e: bsR5W(["流泪", "强"])扔进console运行
f: 很长的定值
g: 定值

找到encSecKey一波带走


固定i后, h一定是固定的
记得把i给复制下来。
function d(d, e, f, g) { d:数据, e:010001, f:很长的定值, g: 定值
var h = {} # 空对象
, i = a(16); # i是一个十六位的随机值
return h.encText = b(d, g),
h.encText = b(h.encText, i), # 返回的是params
h.encSecKey = c(i, e, f), # 得到的就是encSecKey,e和f是定值,i是随机数。 把i固定后得到的一定是固定的。
h # 执行上面三行后返回h
}
完整可运行代码
# 1. 找到未加密的参数 # window.arsea(参数, xxx, xxx, xxx)
# 2. 想办法把参数进行加密(必须参考网易的逻辑) params => encText, encSecKey => encSecKey
#
# 3. 请求到网易,拿到评论
import requests
from Crypto.Cipher import AES
from base64 import b64encode
import json
url = "https://music.163.com/weapi/comment/resource/comments/get?csrf_token="
# 请求方式POST
data = {
"csrf_token": "",
"cursor": "-1",
"offset": "0",
"orderType": "1",
"pageNo": "1",
"pageSize": "20",
"rid": "R_SO_4_33756249",
"threadId": "R_SO_4_33756249"
}
# 服务于d的
e = '010001'
f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
g = '0CoJUm6Qyw8W8jud'
i = '3VjcxTHNACdNwKAo' # 手动固定 网页中是随机的
def get_encSecKey(): # 由于i固定,所以encSecKey固定,c()也是固定的
return "40ab2cd7e589b154526d013a88e1f33ab8145ad6f1080bde14b0c58bcb66a11a3dc9e4c95ec261c47fc30b8ad68ee129c8ad85067c57fca2d540229d17567d2585462d4fe598c4125072afff14843d7320d8524414727916859bb77f1de0cbab1cc328359ae80882edbf4077bf36e82be1301224d2ae9b8fd8c27bc597d6b93c"
# 把参数进行加密
def get_params(data): # 默认这里接收到的字符串
first = enc_params(data, g)
second = enc_params(first, i)
return second # 返回的是params
# 转化成16的倍数,为下方加密算法服务
def to_16(data):
pad = 16 - len(data) % 16
data += chr(pad) * pad
return data
# 加密过程
def enc_params(data, key): # 加密过程
iv = "0102030405060708"
data = to_16(data)
aes = AES.new(key=key.encode("utf-8"), IV=iv.encode("utf-8"), mode=AES.MODE_CBC)
bs = aes.encrypt(data.encode("utf-8")) # 加密,加密内容的长度必须是16的倍数 “123456 chr(10)*10” 逻辑很奇怪,如果正好16,后面要放16个chr(16)
# bs无法被utf-8识别
return str(b64encode(bs), "utf-8") # 转化成字符串返回
"""
function a(a) { # 返回随机16位字符串
var d, e, b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789", c = "";
for (d = 0; a > d; d += 1) # 循环16次
e = Math.random() * b.length, # 随机数
e = Math.floor(e), # 取整
c += b.charAt(e); # 字符串
return c
}
function b(a, b) {
var c = CryptoJS.enc.Utf8.parse(b) # b为密钥
, d = CryptoJS.enc.Utf8.parse("0102030405060708")
, e = CryptoJS.enc.Utf8.parse(a) # 数据
, f = CryptoJS.AES.encrypt(e, c, { # c为密钥
iv: d, # 偏移量
mode: CryptoJS.mode.CBC # 模式:cbc
});
return f.toString()
}
function c(a, b, c) { # c里面不产生随机数
var d, e;
return setMaxDigits(131),
d = new RSAKeyPair(b,"",c),
e = encryptedString(d, a)
}
function d(d, e, f, g) { d:数据, e:010001, f:很长的定值, g: 定值
var h = {} # 空对象
, i = a(16); # i是一个十六位的随机值
return h.encText = b(d, g), # g是密钥
h.encText = b(h.encText, i), # 返回的是params 两次加密,i是密钥
h.encSecKey = c(i, e, f), # 得到的就是encSecKey,e和f是定值,i是随机数。 把i固定后得到的一定是固定的。
h # 执行上面三行后返回h
}
function e(a, b, d, e) {
var f = {};
return f.encText = c(a + e, b, d),
f
}
"""
# 发送请求,得到评论结果
resp = requests.post(url, data={
"params": get_params(json.dumps(data)), # 用json把字典转化为字符串
"encSecKey": get_encSecKey()
})
page_content = resp.json()
page_content2 = page_content['data']['comments']
length = len(page_content2)
for i in range(0, length):
page_content2_0 = page_content2[i]
name = str(i)+"."+page_content2_0['user']['nickname']
content = page_content2_0['content']
print(name+": "+content)
resp.close()

四. 多线程
1. 多线程的两种写法
from threading import Thread
# 写法一:小脚本
# def func():
# for i in range(10):
# print("func", i)
#
# if __name__ == '__main__':
# t = Thread(target=func)
# t.start() # 给一个状态,具体时间cpu决定
#
#
# for i in range(10):
# print("main", i)
# 写法二:业界大佬
class MyThread(Thread):
def run(self): # 线程被执行的时候,被执行的是run()
for i in range(10):
print("子线程", i)
if __name__ == '__main__':
t = MyThread()
# t.run() # 方法调用了 是单线程
t.start() #开启线程
for i in range(10):
print("主线程", i)
2. 多进程
开进程资源消耗大,一般不用。两种写法和上面相似。
from multiprocessing import Process
from threading import Thread
# def func():
# for i in range(10):
# print("子进程", i)
#
# if __name__ == '__main__':
# p = Process(target=func)
# p.start()
#
# for i in range(10):
# print("主进程", i)
def func(name):
for i in range(10):
print(name, i)
if __name__ == '__main__':
t1 = Thread(target=func, args=("周杰伦",)) # args里必须是元组,因此要加逗号
t1.start()
t2 = Thread(target=func, args=("王力宏",))
t2.start()
3. 线程池和进程池
线程池:一次性开辟一些线程,用户直接给线程池提交任务。线程任务的调度交给线程池使用。
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
def fn(name):
for i in range(1000):
print(name, i)
if __name__ == '__main__':
with ThreadPoolExecutor(50) as t:
for i in range(100):
t.submit(fn, name=f"线程{i}")
# 等待线程池中的任务全部执行完毕,才继续执行守护
print("123")
4. 抓取新发地菜价
1. 如何提取单个页面的数据
2. 线程池,多个页面同时抓取
由于新发地页面变了,表格是嵌入的所以换了网址实验。
import requests
from lxml import etree
import csv
from concurrent.futures import ThreadPoolExecutor
f = open("data.csv", mode="w", encoding="utf-8")
csvwriter = csv.writer(f)
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62",
"cookie": "9PT8_2132_saltkey=b1ZDzjBp; 9PT8_2132_lastvisit=1646288784; 9PT8_2132_auth=a903Vhka5sWHUU09/bxTH+w+rJsAh6x4tJy5BqnqjMpOZ2V6eU5pYUsPrEGFerNCIGzlk/ZY3ADvY4gguiDdnsZC; 9PT8_2132_lastcheckfeed=9630|1646292433; 9PT8_2132_nofavfid=1; 9PT8_2132_ulastactivity=12eeUu18XL+NY229Pivd5vy7xlFNWDpeEj2y7ZjgCwluONc6WK7h; 9PT8_2132_visitedfid=2; 9PT8_2132_smile=1D1; 9PT8_2132_st_t=9630|1646395297|b399934743bf5543e8b1f247a0e2eea8; 9PT8_2132_forum_lastvisit=D_2_1646395297; 9PT8_2132_sid=ZgvFBC; 9PT8_2132_lip=222.94.236.130,1646396059; 9PT8_2132_st_p=9630|1646396147|23f1c7005cb442a13c0599b2c429e1fe; 9PT8_2132_viewid=tid_891; 9PT8_2132_sendmail=1; 9PT8_2132_lastact=1646396241 forum.php ajax"
}
def download_one_page(url):
# 拿到源代码
resp = requests.get(url, headers=header)
html = etree.HTML(resp.text)
table = html.xpath("/html/body/div[6]/div[4]/div/div/div[4]/div[2]/form/table")[0]
# tbodys = table.xpath("./tbody")[0]
tbodys = table.xpath("./tbody[position()>1]")
for tbody in tbodys:
txt = tbody.xpath("./tr/th/p[1]/a[2]/text()")
# 对数据做简单的处理: \\ /去掉
txt = (item.replace("\\", "").replace("/", "") for item in txt)
csvwriter.writerow(txt)
print("thread down!")
resp.close()
if __name__ == '__main__':
# for i in range(1, 29): # 效率极其低下
# download_one_page(f"http://txxxxx.xyz/forum.php?mod=forumdisplay&fid=2&page={i}")
with ThreadPoolExecutor(10) as t:
for i in range(1, 29): # 效率极其低下
t.submit(download_one_page, f"http://txxxxx.xyz/forum.php?mod=forumdisplay&fid=2&page={i}")
print("down!")

5. 多任务异步协程
time.sleep(3) #阻塞线程
input() #也是阻塞状态
request.get(csdn) #返回数据前也是阻塞状态
协程:当程序遇见了IO操作,可以选择性的切换到其他任务上
在微观上是一个任务一个任务的进行切换,切换条件一般是IO操作
在宏观上,多任务一起执行
多任务异步操作
上方所讲的一切是在单线程的条件下。
time.sleep是同步操作
import asyncio
import time
async def func1():
print("For mother RUSSIA!")
time.sleep(3) # 当程序出现同步操作的时候,异步中断
print("For mother RUSSIA!")
async def func2():
print("Kirov reporting.")
time.sleep(2)
print("Kirov reporting.")
async def func3():
print("It is a day of jugment.")
time.sleep(1)
print("It is a day of jugment.")
if __name__ == '__main__':
f1 = func1() # 此时函数是异步协程函数,此时函数执行得到一个协程对象
f2 = func2()
f3 = func3()
tasks = [
f1, f2, f3
]
t1 = time.time()
# 一次性启动多个任务(协程)
asyncio.run(asyncio.wait(tasks))
t2 = time.time()
print(t2-t1)

asyncio.sleep是异步操作,await是挂起。一定要挂起。
import asyncio
import time
async def func1():
print("For mother RUSSIA!")
# time.sleep(3) # 当程序出现同步操作的时候,异步中断
await asyncio.sleep(3)
print("For mother RUSSIA!")
async def func2():
print("Kirov reporting.")
await asyncio.sleep(2)
print("Kirov reporting.")
async def func3():
print("It is a day of jugment.")
await asyncio.sleep(1)
print("It is a day of jugment.")
if __name__ == '__main__':
f1 = func1() # 此时函数是异步协程函数,此时函数执行得到一个协程对象
f2 = func2()
f3 = func3()
tasks = [
f1, f2, f3
]
t1 = time.time()
# 一次性启动多个任务(协程)
asyncio.run(asyncio.wait(tasks))
t2 = time.time()
print(t2-t1)

一般用集成后的写法
async def main():
# 第一种写法
# f1 = func1()
# await f1 # 一般await放在协程对象前面
# 第二种写法(推荐)
tasks = [
func1(),
func2(),
func3()
]
await asyncio.wait(tasks)
# py3.8以后用这个
tasks = [
asyncio.create_task(func1()),
asyncio.create_task(func2()),
asyncio.create_task(func3()),
]
await asyncio.wait(tasks)
if __name__ == '__main__':
t1 = time.time()
asyncio.run(main())
t2 = time.time()
print(t2 - t1)

6. aiohttp模块
requests.get() 同步 -> aiohttp 异步
import asyncio
import aiohttp
urls = [
"http://kr.shanghai-jiuxin.com/file/2020/0513/a73863b7af2aceed8d89cfcc5fe02892.jpg",
"http://kr.shanghai-jiuxin.com/file/2020/1031/563337d07af599a9ea64e620729f367e.jpg",
"http://kr.shanghai-jiuxin.com/file/2020/0807/abd1252381fc4c24865ca1513766f489.jpg"
]
async def aiodownload(url):
name = "img/" + url.rsplit("/", 1)[-1]
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
# resp.content.read() # <==> resp.text
# resp.json()
with open(name, mode="wb") as f:
f.write(await resp.content.read()) # 读取内容是异步的,需要await挂起
print(name, "down")
# aiohttp.ClientSession() <==> requests
# 发送请求
# 得到图片内容
# 保存
async def main():
tasks = []
for url in urls:
tasks.append(aiodownload(url))
await asyncio.wait(tasks)
if __name__ == '__main__':
# asyncio.run(main()) # windows专属错误
# iohttp内部使用了_ProactorBasePipeTransport
# 程序退出释放内存时自动调用其__del__方法导致二次关闭事件循环。
# 一般的协程程序是不会使用_ProactorBasePipeTransport的,
# 所以asyncio.run()还是可以正常运行。
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
7. 抓取一本电子书
# 所有章节
# http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"4306063500"}
# 章节内部内容
# http://dushu.baidu.com/api/pc/getChapterContent?data={"book_id":"4306063500","cid":"4306063500|1569782244","need_bookinfo":1}
import requests
import asyncio
import aiohttp
import aiofiles
import json
"""
1. 同步操作:访问所有章节
2. 异步操作,访问章节具体内容,下载所有文章内容
"""
async def aiodownload(cid, b_id, title):
data = {
"book_id": b_id,
"cid": f"{b_id}|{cid}",
"need_bookinfo": 1
}
data = json.dumps(data)
url = f"http://dushu.baidu.com/api/pc/getChapterContent?data={data}"
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
dic = await resp.json()
async with aiofiles.open("xiyouji/"+title, mode="w", encoding="utf-8") as f:
await f.write(dic['data']['novel']['content'])
async def getCatalog(url):
resp = requests.get(url)
dic = resp.json()
tasks = []
for item in dic['data']['novel']['items']: # item对应每个章节的名称和cid
title = item['title']
cid = item['cid']
# 准备异步任务
tasks.append(aiodownload(cid, b_id, title))
await asyncio.wait(tasks)
if __name__ == '__main__':
b_id = "4306063500"
url = 'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"' + b_id + '"}'
asyncio.run(getCatalog(url))
8. 抓取一部视频
一般的视频网站怎么做?
用户上传 -> 转码(把视频做处理,2K,1080等等) -> 切片处理(单个文件拆分) 60
用户在进行拉动进度条
需要一个文件记录:1. 视频播放顺序,2.视频存放的路径
# M3U txt json ==>文本

抓取一个视频:
1. 找到m3u8
2. 通过m3u8下载到ts文件
3. 通过各种手段(不仅是变成手段)把ts合并成一个mp4文件
素材:91看剧

注意里面有个note,是做校验用的。
有的网页(很少)反爬会启用校验。启动校验的时候还具有时效性,超过一定时间note就会失效,刷新后重新分配note。

只需要注意有没有key加密。
91看剧新的网址用不了。
五、selenium
selenium是自动化测试工具,能像人一样操作浏览器。
可以从selenium中提取网页上的各种信息
pip install selenium
chromedriver.storage.googleapis.com/index.html
Microsoft Edge Driver - Microsoft Edge Developer
找对应的谷歌驱动,下载解压后放到解释器的文件夹里。运行pycharm的时候能看到。
 比如就在Anaconda里
比如就在Anaconda里
# 让selenium启动chrome
from selenium.webdriver import ChromiumEdge
# 1. 创建浏览器对象
web = ChromiumEdge()
# 2. 打开一个网址
web.get("http://www.baidu.com")
print(web.title)
web.close()
1. 拉钩网
from selenium.webdriver import ChromiumEdge
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
web = ChromiumEdge()
web.get("http://lagou.com")
# 找到某个元素 点击
el = web.find_element(by=By.XPATH, value='//*[@id="changeCityBox"]/ul/li[2]/a')
el.click() # 点击事件
time.sleep(1) # 浏览器太慢,缓缓
# 找到输入框
web.find_element(by=By.XPATH, value='//*[@id="search_input"]').send_keys("Python", Keys.ENTER)
time.sleep(2) # 不停一下后面来不及加载
# 查找存放数据的位置,进行数据提取
# 找到页面中存放数据的所有li
div_list = web.find_elements(by=By.XPATH, value='//*[@id="jobList"]/div[1]/div')
for div in div_list:
job_name = div.find_element(by=By.TAG_NAME, value='a').text
job_price = div.find_element(by=By.CLASS_NAME, value='money__3Lkgq').text
company_name = div.find_element(by=By.XPATH, value='./div[1]/div[2]/div[1]/a').text
print(f"{job_name}: {job_price}. {company_name}")
# web.close()
2. 页面切换
from selenium.webdriver import ChromiumEdge
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
web = ChromiumEdge()
web.get("http://lagou.com")
web.find_element(by=By.XPATH, value='//*[@id="cboxClose"]').click()
time.sleep(1)
web.find_element(by=By.XPATH, value='//*[@id="search_input"]').send_keys("Python", Keys.ENTER)
time.sleep(1)
# 进入第一个链接
web.find_element(by=By.XPATH, value='//*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[1]/a').click()
time.sleep(1)
# 新窗口默认不切换,要手动切换
web.switch_to.window(web.window_handles[-1])
# 提取内容
job_detail = web.find_element(by=By.XPATH, value='//*[@id="job_detail"]/dd[2]/div').text
print(job_detail)
# 关掉此窗口后,还要切换
web.close()
web.switch_to.window(web.window_handles[0])
有iframe的情况
web.get("https://www.91kanju2.com/vod-play/541-2-1.html")
iframe = web.find_element(by=By.XPATH, value='//*[@id="player_iframe"]')
web.switch_to.frame(iframe)
# web.switch_to.default_content() # 切回默认的地方
# 没找到合适的可输出文本
tx = web.find_element(by=By.XPATH, value='//*[@id="main-message"]/p').text
print(tx)
3. 无头浏览器
无头就靠前几行。直接复制就好了,一般不变。
from selenium.webdriver import ChromiumEdge
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.select import Select
import time
# 准备好参数配置
opt = Options()
opt.add_argument("__headless")
opt.add_argument("--disable-gpu") # 不显示
web = ChromiumEdge(options=opt)
web.get("")
# 定位到下拉列表
sel_el = web.find_element(by=By.XPATH, value='')
# 对元素进行包装,包装成下拉菜单
sel = Select(sel_el)
# 让浏览器调整选项
for i in range(len(sel.options)):
sel.select_by_index() # 索引位置
# sel.select_by_value() # option里的value
# sel.select_by_visible_text() # 可见文本
time.sleep(2)
# 提取数据
table = web.find_element(by=By.XPATH, value='')
print(table.text)
print("down!")
web.close()
源代码和编译后的代码不一样,怎么看编译后的代码
# 如何拿到页面代码elements(经过数据加载以及js执行之后的结果的html)
web.page_source
4. 破解验证码并登录
1. 图像识别
2. 选择互联网上成熟的验证码破解工具
超级鹰为例
from selenium.webdriver import ChromiumEdge
from selenium.webdriver.common.by import By
# 在超级鹰注册后下下来的的demo
from chaojiying import ChaojiyingClient
web = ChromiumEdge()
web.ger("http://www.chaojiying.com/user/login")
img = web.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/div/img').screenshot_as_png
chaojiying = chaojiying = ChaojiyingClient('超级鹰的id', '超级鹰的password', '创建生成的任务id')
dic = chaojiying.PostPic(img, 1902) # 1902是超级鹰网站给的验证码了类型代码
verify_code = dic['pic_str']
# 输入用户名密码
web.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input').send_keys('登陆网站的账号')
web.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input').send_keys('登陆网站的密码')
web.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input').send_keys(verify_code)
# 点击登录
web.find_element(by=By.XPATH, value='/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input').click()
5. 12306
from selenium.webdriver import ChromiumEdge
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.edge.options import Options
import time
# 如果程序被识别selenium了怎么办
# 1.chrome的版本号小于88
# 在你启动浏览器的时候(此时没有加载任何网页内容),向页面嵌入js代码,去掉webdriver
# web = ChromiumEdge()
#
# web.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument",{
# "source": """
# window.navigator.webdriver = undefined
# Object.defineProperty(navigator, 'webdriver',{
# get:() ==> undefined
# })
# """
# })
# web.get(xxx)
# 2.chrome的版本号大于88
option = Options()
option.add_argument('--disable-blink-features=AutomationControlled')
web = ChromiumEdge(options=option)
web.get("https://kyfw.12306.cn/otn/resources/login.html")
time.sleep(3)
web.find_element(by=By.XPATH, value='//*[@id="J-userName"]').send_keys('登录名')
web.find_element(by=By.XPATH, value='//*[@id="J-password"]').send_keys('登陆密码')
time.sleep(1)
web.find_element(by=By.XPATH, value='//*[@id="J-login"]').click()
time.sleep(2)
#移动再点击
# ActionChains(web).move_to_element_with_offset(start, x, y).click().perform()
# 拖拽
btn = web.find_element(by=By.XPATH, value='//*[@id="nc_1_n1z"]')
ActionChains(web).drag_and_drop_by_offset(btn, 300, 0).perform()
六. 数据存储
1. json
json的保存
在python中只有基本数据类型才能转换成json格式的字符串。即:int, float,str,list,dict,tuple。
json是列表里面放字典。
import json
persons = [
{
"username": "伊利亚",
"age": 2,
"country": "CCCP"
},
{
"username": "布拉金斯基",
"age": 3,
"country": "RUSSIA"
}
]
json_sdr = json.dumps(persons) # 直接转换成字典
# print(type(json_sdr))
# print(json_sdr)
with open('./person.json', 'w', encoding="utf-8") as fp:
# fp.write(json_sdr)
json.dump(persons, fp, ensure_ascii=False) # 传文件指针 一定要把ascii给关了,否则会转换成英文字符
dumps是直接转化dic,不可以保存为文件, dump会转换成指针可以保存为文件。
json的读取
json_str = '[{"username": "伊利亚", "age": 2, "country": "CCCP"}, {"username": "布拉金斯基", "age": 3, "country": "RUSSIA"}]'
persons = json.loads(json_str)
print(type(persons))
for person in persons:
print(person)
with open('person.json', 'r', encoding="utf-8") as fp:
persons = json.load(fp)
for person in persons:
print(person)
2. csv
读取csv文件
import csv
def read_csv_demo1():
with open('testx.csv', 'r', encoding='utf-8') as fp:
# reader是一个迭代器
reader = csv.reader(fp)
next(reader) # 跳过表头
for x in reader:
education = x[3]
age = x[0]
print({'education': education, 'age': age})
def read_csv_demo2():
with open('testx.csv', 'r', encoding='utf-8') as fp:
# 不会包含标题
# 返回字典
reader = csv.DictReader(fp)
for x in reader:
value = {"education": x['education'], 'age': x['age']}
print(value)
if __name__ == '__main__':
read_csv_demo2()
写入csv
newline默认是\n换行
def write_csv_demo1(headers, values):
with open('classroom1.csv', 'w', encoding='utf-8', newline='') as fp:
writer = csv.writer(fp)
writer.writerow(headers)
writer.writerows(values) # 写入多行数据
def write_csv_demo2(headers, values):
with open('classroom2.csv', 'w', encoding='utf-8', newline='') as fp:
writer = csv.DictWriter(fp, headers)
writer.writeheader() # 写入表托数据
writer.writerows(values)
if __name__ == '__main__':
headers = ['name', 'age', 'height']
values1 = {
('伊利亚', 2, 180),
('布拉金斯基', 2, 178),
('伊万', 2, 179)
}
write_csv_demo1(headers, values1)
values2 = [
{'name': '伊利亚', 'age': 2, 'height': 180},
{'name': '布拉金斯基', 'age': 2, 'height': 178},
{'name': '伊万', 'age': 2, 'height': 179}
]
write_csv_demo2(headers, values2)
3. mysql
import pymysql
host = 'localhost'
user = 'root'
pasw = '1234'
name = 'test'
try:
db = pymysql.connect(host=host, user=user, password=pasw, database=name)
print('ok')
cur = db.cursor()
cur.execute('drop table if exists Student')
sql = 'create table Student(Name char(20), Email char(20), Age int)'
cur.execute(sql)
print("成功")
sql = 'drop table if exists stuinfo'
cur.execute(sql)
print("删了")
except pymysql.err as e:
print("no")
插入
sql = """
insert into user(id, username, age, password) values(null, %s, %s, %s)
"""
# 不管里面是什么类型,都要写%s 字符串类型
username = 'spider'
age = 21
password = '12345'
cursor.execute(sql, (username, age, password))
conn.commit()
查找
# fetchone
sql = """
select username, age from user where id=1
"""
cursor.execute(sql)
result = cursor.fetchone()
print(result)
sql = """
select * from user
"""
cursor.execute(sql)
while True:
result = cursor.fetchone()
if result:
print(result)
else:
break
# fetchall 所有 fetchmany 前几个
sql = """
select * from user
"""
cursor.execute(sql)
results = cursor.fetchall()
for result in results:
print(result)
删除
# 删除和更新
sql = """
delete from user where id=4
"""
cursor.execute(sql)
# 插入删除更新都需要commit提交
conn.commit()
sql = """
update user set username='brakinski' where id=3
"""
cursor.execute(sql)
conn.commit()
你可能感兴趣的:(python,爬虫,学习,python)