python爬虫—视频爬虫2(m3u8)
python爬虫—视频爬虫2(m3u8)
一、视频爬虫的分析
今天我们爬的视频比上一期的要特殊一些,一些网站使用m3u8来进行视频的播放工作,特意去搜了一下m3u8与mp4相比的一些优势:
1.HTML5 直接支持m3u8协议。
2.m3u8其实是一个协议而不是一种视频格式,m3u8里面包括的多是视频块索引。可以通过网络状态自动切换码率。MP4就没有这方面优势了。
3.m3u8允许客户在进行播放时,从许多不同的备用源中下载视频块。
4.m3u8是HLS协议的部分内容。是一种能够通过http报文就能够请求和访问了。
MP4如果要实现在线播放那么就需要RTP协议来实现。两种手段有比较大的区别。
5.更高性能上能够将部分m3u8的播放块切块之后直接加载到服务器内存中,让客户端可以更快的得到数据。
6.m3u8 由于是采用切块技术,那么下载的播放文件 就可以少很多,只有当前播放的部分。这一点用在在线直播上有很大优势。
所以很多大型的网站会使用m3u8这种视频播放方式,对于这种视频咱们怎么爬取呢,还是按照爬虫的基本规则:
- 打开视频播放地址分析视频的规律,尝试可以独立打开视频下载链接
- 编写python下载视频脚本
- 拓展爬虫范围,获取视频列表
二、爬虫代码解析
这一操作其实就是为了找寻视频的下载链接;
首先让我你们打开视频的网址;这里我用的是1905电影网
上一篇我们也说了,对于视频资源一般都是通过接口来获取数据的,让我们 打开F12 从响应时间中找一下那些有肯能是视频链接的请求接口
你会发现和我们上一篇找的不一致,没有出现一个很长响应时间的求情,看着都很散,那怎么办呢,是不是说明视频流不是通过接口请求来产生的,不要慌,我们继续向下看;
你就会发现一个有意思的事情:每加载一段视频就会多一个请求接口,那我们还不是认为这些接口就是用来获取视频流的呢,
有怀疑我们就去尝试,那让我们复制链接打开看一哈;
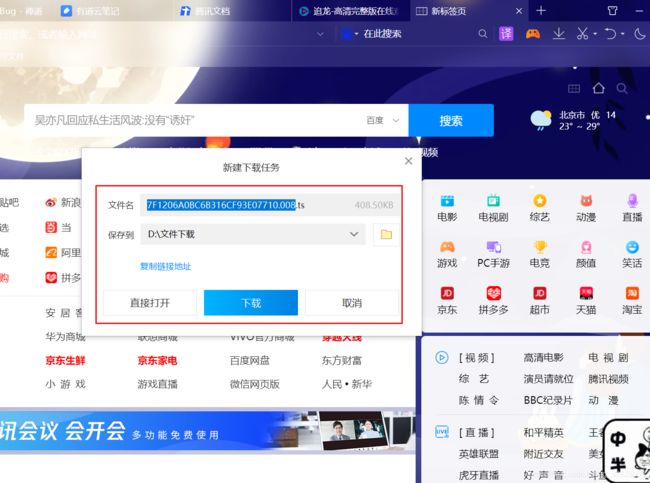
是个.ts文件(什么鬼,没听说过这种格式)直接让我们下载,那我们下载看一下是什么文件,看着大小也不大

哦? 视频文件,感觉有戏呀,怀着激动的心颤抖的手打开看一下什么视频内容;
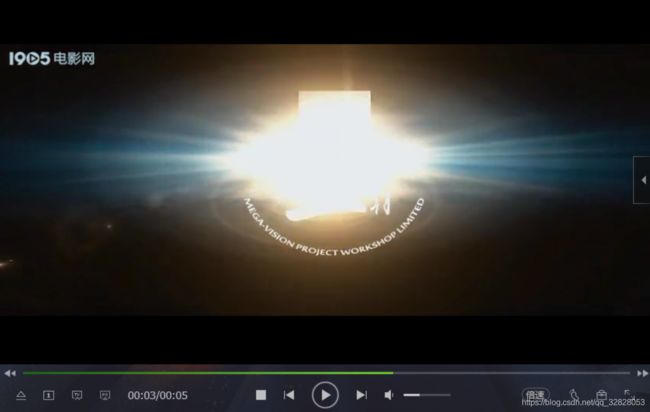
没错,我们果然是个小天才,确实是我们需要的视频,
这样我们只需要python代码吧它下载下来就可以了;
接下来问题又来了,下载下来的视频也太小了吧,不是完整的呀;
让我们回到url接口请求看一下
这些都是视频,下载两个查看发现,他们是顺序链接起来的,
那是不是说我把所有的.ts文件都下载下来最后拼接一下不就是完整的视频啦,
听着没毛病
那咱们就来做做看,但是随之又来问题了,我们总不能每次都复制.ts接口的url进行下载吧,这样不得费劲死。既然都是.ts的接口,那这些接口之间是根据什么来进行区分的呢,我们比对几个接口看看
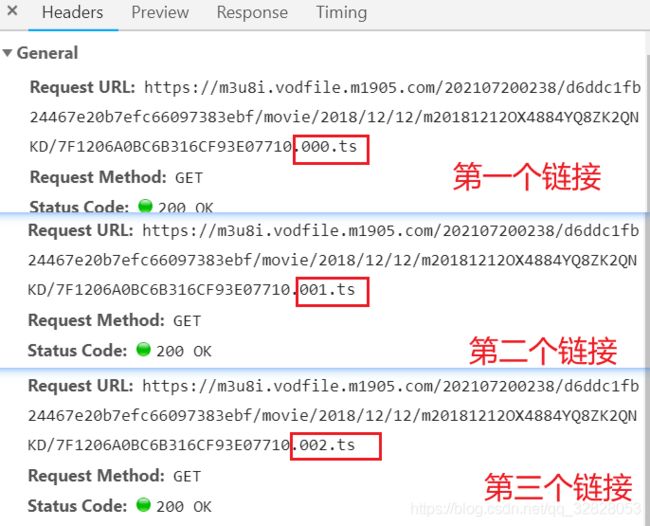
我们就会发现接口请求基本一致,不一样的都是是.ts前面的一个自增数字。
那是不是代表着我们只需要改一下数字就可以获取到我们需要的指定视频,尝试一下改成50
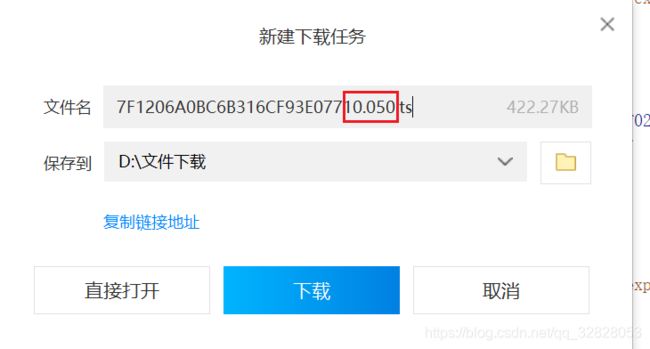
下载没问题,我们的思路是正确的,但是叒来问题了,这个自增的数会一直到多少?我们无法获取到,============既然这条路走不通那我们就换一条,我们站在程序的角度上考虑,我们不知道但是程序肯定是可以再哪个地方获取到,并且这个获取到的方式肯定是在视频产生之前也就是在001.ts之前,首先我们想到的是接口,让我们看一下前几个接口响应有没有带我们需要的东西,
挨个的找,在这个接口的响应我们就感觉熟悉了(https://m3u8i.vodfile.m1905.com/202107200238/d6ddc1fb24467e20b7efc66097383ebf/movie/2018/12/12/m20181212OX4884YQ8ZK2QNKD/7F1206A0BC6B316CF93E07710.m3u8)
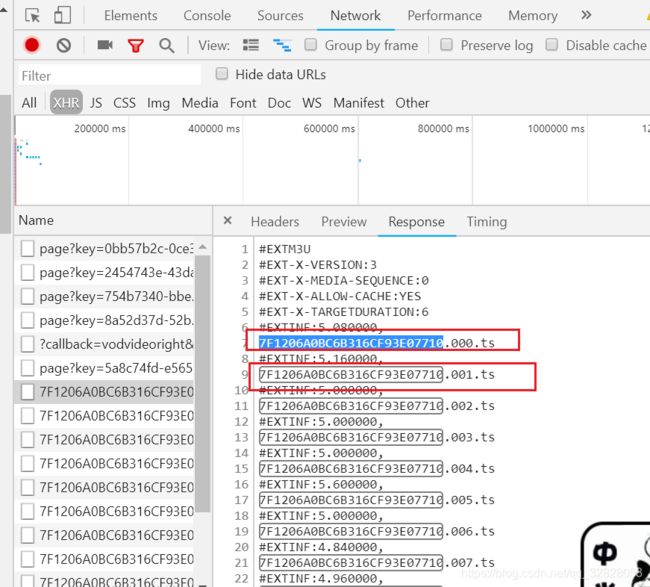
这就是我们视频下载链接的最后一些参数值吗,
我们拿到这些值,自己把链接拼起来不就解决了遇到的问题了。
话不多说让我们python写着看一下
大概分为几个动作吧:
- 获取.ts视频下载链接的列表
- 下载视频
- 拼接视频
三、代码汇总
1、编写获取.ts下载链接的列表,此时需要我们传入m3u8的链接
# 访问m3u8 获取到.ts列表
def get_ts(url_m3u8):
d_m3u8 = requests.get(url_m3u8).content.decode('utf-8') # 访问网页获取返回信息
ts_list = re.findall(r'(.*?).ts', d_m3u8) # 正则提取出列表
return ts_list
是不是感觉贼简单
2、从列表中循环取出视频链接然后进行下载
# 把ts视频下载到本地,需要传入视频的下载ts文件列表 和下载保存地址path
def dow_ts(url,path):
# for 循环拼接成完整的url下载链接
for i in range(0,len(url)):
url[i] = 'https://m3u8i.vodfile.m1905.com/202107150205/b45dc3508532eaa26d0441b7425c2619/movie/2018/12/12/m20181212OX4884YQ8ZK2QNKD/' + url[i] +'.ts'
x = 0 # 用于给多个视频进行子等命名
# for循环取数据进行下载
for url_l in url:
# 设置保存的地址
path1 = path + str(x) + '.ts'
try:
print(url_l) # 用于展示下载的是哪个视频链接
vi = requests.get(url_l,timeout=5).content # 获取到下载链接的返回值
with open(path1,'wb') as mp4: # 下载视频到本地
mp4.write(vi)
print(str(x) +'下载成功')
x = x + 1
except:
print('下载失败')
3、视频下载到本地之后进行拼接
这里分两个动作,首先是排序,然后是拼接
# 将已经下载的ts文件的路径进行排序
def file_walker(path):
# 建一个空列表用来放文件夹里面的文件
file_list = []
# for循环把文件夹中的文件输出为绝对路径的列表file_list
for root, dirs, files in os.walk(path): # 生成器
# 对列表中的数据进行排序
files.sort()
# for 为了把files列表中的数据改造成指定的类型
for i in range(0,len(files)):
files[i] = v_fi1 +files[i]
file_list = files
return file_list
# ts_path: 下载好的一堆ts文件的文件夹
# combine_path: 组合好的文件的存放位置
# file_name: 组合好的视频文件的文件名
# combine函数把文件列表读取并且合成为视频输出
def combine(ts_path, combine_path, file_name):
# 调用file_walker函数获取文件夹中的文件并且按照指定方式列表输出
file_list = file_walker(ts_path)
print(file_list)
print(type(file_list))
# 设置合成后的视频输出内容
file_path = combine_path + file_name + '.mp4'
# 读取列表信息合成视频并输出
with open(file_path, 'wb+') as fw:
for i in range(len(file_list)):
fw.write(open(file_list[i], 'rb').read())
print('合并完成')
4、全部代码
import re
import requests
# from moviepy.editor import *
import os
# 下载m3u8类型的视频
# 访问m3u8 获取到.ts列表
def get_ts(url_m3u8):
d_m3u8 = requests.get(url_m3u8).content.decode('utf-8') # 访问网页获取返回信息
ts_list = re.findall(r'(.*?).ts', d_m3u8) # 正则提取出列表
return ts_list
# 把ts视频下载到本地,需要传入视频的下载ts文件列表 和下载保存地址path
def dow_ts(url,path):
# for 循环拼接成完整的url下载链接
for i in range(0,len(url)):
url[i] = 'https://m3u8i.vodfile.m1905.com/202107150205/b45dc3508532eaa26d0441b7425c2619/movie/2018/12/12/m20181212OX4884YQ8ZK2QNKD/' + url[i] +'.ts'
x = 0 # 用于给多个视频进行子等命名
# for循环取数据进行下载
for url_l in url:
# 设置保存的地址
path1 = path + str(x) + '.ts'
try:
print(url_l) # 用于展示下载的是哪个视频链接
vi = requests.get(url_l,timeout=5).content # 获取到下载链接的返回值
with open(path1,'wb') as mp4: # 下载视频到本地
mp4.write(vi)
print(str(x) +'下载成功')
x = x + 1
except:
print('下载失败')
'''
# 指定文件夹的mp4视频进行合并,输出合并的视频,并输出到当前文件夹
def mp4_vio(path): # path是mp4视频所在的文件夹地址
L = [] # 定义一个数组
# 访问 文件夹 (假设视频都放在这里面只能拼接mp4视频)
for root, dirs, files in os.walk(path):
# 按文件名排序
files.sort()
# 遍历所有文件
print(files)
for file in files:
# 如果后缀名为 .mp4
if os.path.splitext(file)[1] == '.mp4':
# os.path.splitext(“文件路径”) 分离文件名与扩展名;默认返回(fname,fextension)元组
# 拼接成完整路径
filePath = os.path.join(root, file)
# os.path.join()函数:连接两个或更多的路径名组件
# 载入视频
video = VideoFileClip(filePath)
# 添加到数组
L.append(video)
# 拼接视频
final_clip = concatenate_videoclips(L)
# 生成目标视频文件
path1 = path + '\\全集.mp4'
final_clip.to_videofile(path1, fps=24, remove_temp=False)
'''
# 将已经下载的ts文件的路径进行排序
def file_walker(path):
# 建一个空列表用来放文件夹里面的文件
file_list = []
# for循环把文件夹中的文件输出为绝对路径的列表file_list
for root, dirs, files in os.walk(path): # 生成器
# 对列表中的数据进行排序
files.sort()
# for 为了把files列表中的数据改造成指定的类型
for i in range(0,len(files)):
files[i] = v_fi1 +files[i]
file_list = files
return file_list
# ts_path: 下载好的一堆ts文件的文件夹
# combine_path: 组合好的文件的存放位置
# file_name: 组合好的视频文件的文件名
# combine函数把文件列表读取并且合成为视频输出
def combine(ts_path, combine_path, file_name):
# 调用file_walker函数获取文件夹中的文件并且按照指定方式列表输出
file_list = file_walker(ts_path)
print(file_list)
print(type(file_list))
# 设置合成后的视频输出内容
file_path = combine_path + file_name + '.mp4'
# 读取列表信息合成视频并输出
with open(file_path, 'wb+') as fw:
for i in range(len(file_list)):
fw.write(open(file_list[i], 'rb').read())
print('合并完成')
# 需要合并文件的位置
# m3u8的链接
url_m3u8 = 'https://m3u8i.vodfile.m1905.com/202107200238/d6ddc1fb24467e20b7efc66097383ebf/movie/2018/12/12/m20181212OX4884YQ8ZK2QNKD/7F1206A0BC6B316CF93E07710.m3u8'
#下载地址
v_fi = 'D:\\test1'
v_fi1 = v_fi + "\\"
path = v_fi1
# 调用get_ts获取ts的列表
ts_list = get_ts(url_m3u8)
# 调用dow_ts下载视频到本地
d = dow_ts(ts_list,path)
# 调用combine函数 合成视频
vd = combine(v_fi,v_fi1,"全新的版本")

最终的结果(没合并视频)

四、拓展
1、每次手动输入m3u8的地址也确实有待烦,下一步就是我们从访问视频的页面获取m3u8的地址
2、从列表中获取视频的链接进行批量视频下载