2020-6-28 吴恩达DL学习-C3结构化ML项目-w1 ML策略1(1.3 单一数字评估指标,查准率/查全率/F1分数)
1.视频网站:mooc慕课https://mooc.study.163.com/university/deeplearning_ai#/c
2.详细笔记网站(中文):http://www.ai-start.com/dl2017/
3.github课件+作业+答案:https://github.com/stormstone/deeplearning.ai
1.3 单一数字评估指标 Single number evaluation metric
无论你是调整超参数,或者是尝试不同的学习算法,或者在搭建ML系统时尝试不同手段,你会发现,如果你有一个单实数评估指标,你的进展会快得多,它可以快速告诉你,新尝试的手段比之前的手段好还是差。
所以当团队开始进行ML项目时,我经常推荐他们为问题设置一个单实数评估指标。

我们来看一个例子,你之前已经学习过,应用ML是一个非常经验性的过程。
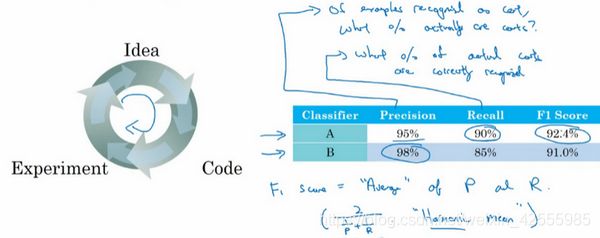
如上左图,我们通常有一个想法,编程序,跑实验,看看效果如何,然后使用这些实验结果来改善你的想法,然后继续走这个循环,不断改进你的算法。
比如说对于你的猫分类器,之前你搭建了某个分类器,通过改变超参数,还有改变训练集等手段,你现在训练出来了一个新的分类器B,所以评估你的分类器的一个合理方式是观察它的查准率(precision)和查全率(recall)。
查准率和查全率的确切细节对于这个例子来说不太重要。
但简而言之
-
查准率的定义是在你的分类器标记为猫的例子中,有多少真的是猫。所以如果分类器有95%的查准率,这意味着你的分类器 A A A说这图有猫的时候,有95%的机会真的是猫。
-
查全率的定义就是,对于所有真猫的图片,你的分类器正确识别出了多少百分比。实际为猫的图片中,有多少被系统识别出来?如果分类器 A A A查全率是90%,这意味着对于所有的图像,比如说你的开发集都是真的猫图,分类器 A A A准确地分辨出了其中的90%。
关于查准率和查全率的定义,不用想太多。
事实证明,查准率和查全率之间往往需要折衷,两个指标都要顾及到。
你希望得到的效果是,当你的分类器说某个东西是猫的时候,有很大的机会它真的是一只猫。但对于所有是猫的图片,你也希望系统能够将大部分分类为猫,所以用查准率和查全率来评估分类器是比较合理的。
但使用查准率和查全率作为评估指标的时候,有个问题,如果分类器 A A A在查全率上表现更好(上例中90%),分类器在查准率 B B B上表现更好(上例中98%),你就无法判断哪个分类器更好。
有可能你尝试了很多不同想法,很多不同的超参数,而此时不仅仅是两个分类器,也许是十几个分类器,快速选出“最好的”那个,这样你可以从那里出发再迭代。如果有两个评估指标,就很难去快速地二中选一或者十中选一。
所以我并不推荐使用两个评估指标–查准率和查全率–来选择一个分类器。你只需要找到一个新的评估指标,能够结合查准率和查全率。
在ML文献中,结合查准率和查全率的标准方法是所谓的 F 1 F_1 F1 分数。
F 1 F_1 F1分数的细节并不重要,它的定义是这个公式: 2 1 p + 1 R \frac 2{\frac 1p+\frac 1R} p1+R12
在数学中,这个函数叫做查准率 P P P和查全率 R R R的调和平均数。
但非正式来说,你可以将它看成是某种查准率和查全率的平均值,只不过你算的不是直接的算术平均,而是用这个公式定义的调和平均。
这个指标在权衡查准率和查全率时有一些优势。

如上图,在这个例子中,你可以马上看出,分类器 A A A的 F 1 F_1 F1分数更高。假设 F 1 F_1 F1分数是结合查准率和查全率的合理方式,你可以快速选出分类器 A A A,淘汰分类器 B B B。
我发现很多ML团队就是这样,有一个定义明确的开发集用来测量查准率和查全率,再加上这样一个单一数值评估指标,有时我叫单实数评估指标,能让你快速判断分类器或者分类器更好。
所以有定义明确的一个开发集,加上单实数评估指标,你的迭代速度肯定会很快,它可以加速改进您的ML算法的迭代过程。
我们来看另一个例子。
假设你在开发一个猫应用来服务四个地理大区的爱猫人士,美国、中国、印度还有世界其他地区。我们假设你的两个分类器在来自四个地理大区的数据中得到了不同的错误率,具体如下图,比如算法 A A A在美国用户上传的图片中达到了3%错误率,等等。

通过跟踪上图中四个地区的错误率数字,很难扫一眼这些数值就快速判断算法 A A A或算法 B B B哪个更好。
如果你测试很多不同的分类器,如下图,看着那么多数字,然后快速选一个最优就更难了。

所以在这个例子中,除了跟踪分类器在四个不同的地理大区的表现,也要算算平均值。假设平均表现是一个合理的单实数评估指标,通过计算平均值,你就可以快速判断。
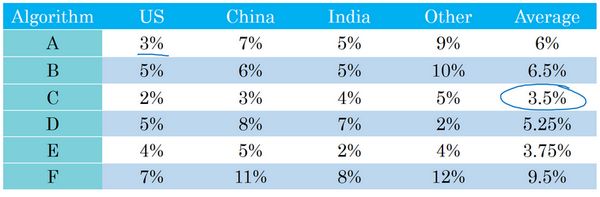
根据上图,看起来算法 C C C的平均错误率最低。你可以继续用算法 C C C,然后不断迭代。
通常你的ML的工作流程往往是你有一个想法,你尝试实现它,看看这个想法好不好。
本节中给了你一个基本的概念,有一个单实数评估指标真的可以提高你的效率,或者提高你的团队做出这些决策的效率。