TCP重传,滑动窗口,流量控制,拥塞控制
重传机制
- 超时重传
- 快速重传
- SACK
- D-SACK
超时重传
RTT 就是 数据从网络一端传送到另一端所需要的时间,也就是包的往返时间。
超时重传时间以 RTO 表示,应该略大于RTT。
如果超时重发的数据,再次超时时有需要重传,TCP的策略是超时间隔加倍。也就是每当遇到一次超时重传时,都会将下一次超时时间间隔设为之前的两倍。两次超时,就说明网络环境差,不宜频繁发送。
弊端:超时重传的周期相对长,更快的方法是快速重传。
快速重传
快速重传机制,不以时间为驱动,而是以数据驱动重传。
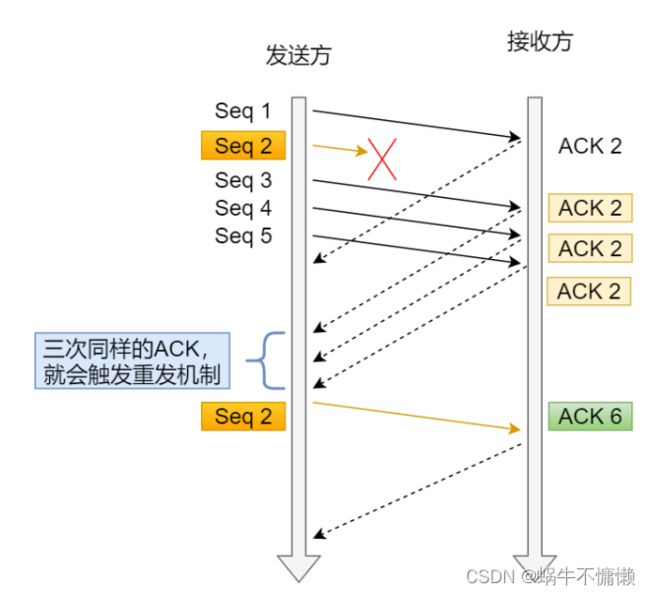
发送端收到了3个ACK=2的确认,知道了Seq2还没有收到,就会在定时器过期之前,重传丢失的Seq2。
所以,快速重传的工作方式是当收到三个相同ACK报文时,会在定时器之前过期,重传丢失的报文段。
问题:重传的时候,是重传之前的一个,还是重传所有的问题。
SACK 方法
SACK (选择性确认)
在TCP头部[选项]字段里加一个SACK的东西,它可以将缓存的地图发送给对方,发送方就知道哪些数据收到哪些没收到,只重传丢失的数据。
D-SACK
主要是用SACK来告诉发送方有哪些数据被重复接受了。
D-SACK有这么几个好处:
- 可以让发送方知道,是发出去的包丢了,还是接收方回应的ACK包丢了。
- 可以知道是不是 发送方的数据包被网络延迟了;
- 可以知道网络中是不是把发送方的数据包复制了
滑动窗口
以往的传输方式是 发一个,回应一次,才能继续发。这样的缺点是往返时间长,通信效率低。
为解决这个问题,引入窗口的概念,即使在往返时间较长的情况下,它也不会降低网络通信的效率。窗口大小就是指无需等待确认应答,而可以继续发送数据的最大值。
- 发送窗口
- 接受窗口
流量控制
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yv6gj1wI-1663423189830)(C:\Users\chenzhengchang\AppData\Roaming\Typora\typora-user-images\image-20220917174123355.png)]](http://img.e-com-net.com/image/info8/e452717f084940bcb06a2e5122dba6af.jpg)
为了解决这种现象发⽣,TCP 提供⼀种机制可以让「发送⽅」根据「接收⽅」的实际接收能⼒控制发送的数据量, 这就是所谓的流量控制。
- 操作系统缓冲区与滑动窗口的关系
- 窗口关闭
- 糊涂窗口综合症
操作系统缓冲区与滑动窗口的关系
实际上,发送窗口和接受窗口所存放的字节数,都是放在操作系统的内存缓冲区中的,而操作系统的缓冲区,会被操作系统调制。
操作系统的缓冲区是如何影响发送窗口和接收窗口的呢?
两个例子
- 假设服务端作为接收端,服务端非常繁忙,收到客户端的数据时,应用层不能及时读取数据,最终客户端收到确认和窗口报文后,发送窗口减少为0.
- 当服务端系统资源非常紧张时,可能会直接减小接收缓冲区大小,这时应用程序又无法及时读取缓存数据,这样就会出现数据包丢失的现象。
所以,如果发生了先减少缓存,再收缩窗口,就会出现丢包现象。
为了防止这种情况,TCP规定不允许同时减少缓存又收缩窗口,而是先收缩窗口,果断时间再减小缓存。
窗口关闭
如果窗口大小为0,就会阻止发送方给接收方传递数据,直到窗口变为非0,这就是窗口关闭。
窗口关闭潜在危险
当发送窗口关闭,接收方处理完数据后,会向发送方发送一个窗口非0的ACK报文,如果这个报文丢失,那么将会形成死锁。
解决方法
TCP为每个连接设有一个持续定时器,只要TCP连接的一方收到零窗口通知,就启动持续定时器。定时器超时,就会发生窗口探测报文,对方确认后,就会回应。打破死锁的局面。
窗口探测一般为3次,3次过后接收窗口还是0的话,有的TCP就会发RST报文来中断连接。
糊涂窗口综合症
当发送窗口越来越小时,如果接收⽅腾出⼏个字节并告诉发送⽅现在有⼏个字节的窗⼝,⽽发送⽅会义⽆反顾地发送这⼏个字节, 这就是糊涂窗⼝综合症。
现象来源:
- 接收方可以通告一个小窗口
- 发送方可以发送小数据
解决方法
- 当窗口大小小于 min(MSS,缓存空间/2),也就是小于MSS与1/2缓存大小中的最小值时,就会向发送方通告窗口为0,阻止对方发数据。等接收方处理了一些数据,满足条件后再打开窗口。
- 使用Nagle算法,延时处理数据,避免发送方发送小数据。
拥塞控制
与流量控制的区别
前面的流量控制是避免 [发送方] 的数据填满 [接收方] 的缓存,但是并不知道网络中发生了什么。
在网络出现拥堵时,如果继续发生大量数据包,可能会导致数据包时延,丢失等,这时TCP就会重传,一重传加重网络负担,于是更多包延迟或者丢包,形成恶性循环。
拥塞控制就是用来避免 [发送方] 的数据填满整个网络。
为了在[发送方]调节要发送数据的量,定义了一个叫做 拥塞窗口的概念。
什么是拥塞窗口?
拥塞窗口 cwnd 是发送方维护的一个状态变量,它会根据网络的拥塞程度动态变化的。
拥塞窗口cwnd的变化规则:
- 只要网络中没有出现拥塞,cwnd就会增加;
- 但网络中出现拥塞,cwnd就会减少;
PS:发送窗口 swnd ,接收窗口 rwnd
那么怎么知道网络是否出现拥塞?
只要[发送方]没有在规定时间内收到ACK应答报文,也就是发生了超时重传,就认为网络出现了拥塞。
拥塞控制主要是四个算法:
慢启动
慢启动算法只要记住一个规则就行:当发送方每收到一个ACK,拥塞窗口cwnd的大小就会加1。
cwnd为多大,表示可以传多大的数据。
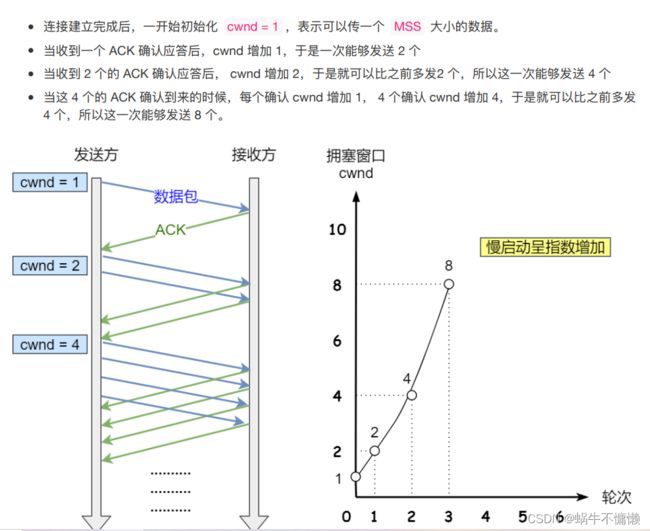
慢启动什么时候停止
慢启动是指数增长。
有一个叫慢启动门限 ssthresh 的状态变量
- 当cwnd< ssthresh时,使用慢启动算法
- 当cwnd>ssthresh时,使用 拥塞避免算法
拥塞避免算法
cwnd超过 慢启动门限 ssthresh就会进入拥塞避免算法。
一般来说ssthresh的大小是65535字节。
进入拥塞算法后,它的规则是:每当收到一个ACK,cwnd增加 1/cwnd
这样就从慢启动的指数增长变成线性增长了。
但是一直增长下去,网络还是会拥塞,出现丢包现象,这时需要对丢弃的数据进行重传,当重传机制启动,也就进入了 拥塞发生算法
拥塞发生
当网络出现拥塞,也就是发生数据包重传,重传机制有两种。
- 超时重传
- 快速重传
这两种拥塞发生的算法是不同的。
当发生了超时重传
- ssthresh 设为 cwnd/2;
- cwnd = 1;
接着就开始慢启动。但是这种方法太激进了,反应很强烈,会造成网络卡顿。
还有更好的方式:快速重传
当发生了快速重传
- cwnd = cwnd/2;
- ssthresh = cwnd;
- 进入快速恢复算法
快速恢复
快速恢复算法是和快速重传同时使用的。
快速恢复算法如下:
- 拥塞窗口 cwnd =ssthresh +3 (意思是确认有3给数据包被收到了)
- 重传丢失的数据包;
- 如果收到重复的ACK,那么cwnd加1
- 如果收到新数据的 ACK 后,把 cwnd 设置为第⼀步中的 ssthresh 的值,原因是该 ACK 确认了新的数据,说 明从 duplicated ACK 时的数据都已收到,该恢复过程已经结束,可以回到恢复之前的状态了,也即再次进 ⼊拥塞避免状态

图片来着 小林coding (侵删)。