CenterTrack结构解析
前言
本文我们将介绍一个真正意义上将目标检测和数据关联统一的MOT框架 ,CenterTrack!
提到CenterTrack就不得不提到anchor-free目标检测的经典之作, CenterNet,之前我也做过一个有关CenterNet的解析,链接如下:https://zhuanlan.zhihu.com/p/212305649
CenterNet的论文名叫做《Objects as Points》。
CenterTrack的论文叫做《Tracking Objects as Points》。
CenterNet的思想非常简单,其网络结构如下

输出三个分支,分别为
(1)HeatMap,大小为(W/4,H/4,80),输出不同类别(80个类别)物体中心点的位置
(2) Offset,大小为(W/4,H/4,2),对HeatMap的输出进行精炼,提高定位准确度
(3) Height&Width,大小为(W/4,H/4,2),预测以关键点为中心的检测框的宽高
那么Center-Track的结构是不是也是类似呢?论文中提到
CenterTrack localizes objects and predicts their associations with the previous frame
这个意思不就是多出来一个分支用来做时间维度的association吗?是的,论文中提到:
The architecture of CenterTrack is essentially identical to CenterNet, with four additional input channels
也就是相比于CenterNet,CenterTrack多出来了四个额外的输入通道。
为什么是四个额外的输入通道呢?
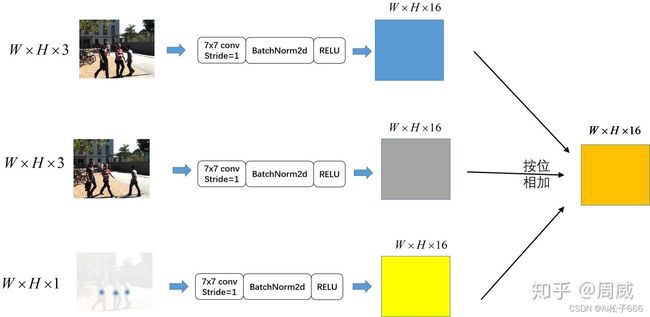
通篇来看发现CenterTrack的输入为两个RGB图片(当前帧和前一帧)+一张heatmap图(前一帧中物体中心分布的热力图),这不比CenterTrack多了一张RGB(3通道)和一个单通道的heatmap嘛。所以我们给出CenterTrack的大致结构图。

那么为什么作者要提出CenterTrack呢?动机是什么呢?
这在JDE解析的时候给出了分析,目前多数MOT都是Tracking-by-Detection的,MOT系统的整体检测速度约等于检测器速度+追踪器速度。而一些作者提到他们的追踪器速度可以达到实时,仅仅说的是追踪器的速度,并不是整体MOT系统的速度(真鸡贼)。
所以JDE说为了加速MOT系统的速度,将检测和embedding用同一个网络输出了,这的确加速了整个MOT的速度,但是JDE仍然是双阶段的,即
(1)检测+embedding
(2)数据关联匹配,实现追踪
有没有一种方法,不用双阶段,也就是合并检测阶段和匹配阶段,直接实现MOT呢?本文的主角,CenterTrack就是这样的网络。合并检测和追踪过程到同一个网络,可以加速MOT系统的整体检测速度,实验证明,CenterTrack的确是一种速度和精度trade-off的模型。
接下来我们将对CenterTrack进行详细解析。用到的代码是https://link.zhihu.com/?target=https%3A//github.com/xingyizhou/CenterTrack
网络结构解析
上面我们已经分析过CenterTrack的网络结构了,并给出了详细的结构图。下面我们结合代码来详细聊聊这个结构设计的巧妙之处。
我们知道和CenterNet不同,CenterTrack的输入有三个,分别为
(1)当前帧的RGB图片,大小为(W,H,3)
(2) 前一帧的RGB图片,大小为(W,H,3)
(3) 前一帧预测的heatmap,大小为(W,H,1)
那么为什么CenterTrack需要三个输入呢?
因为目标追踪问题并不像目标检测问题那样仅需要知道当前帧即可计算获得检测框,目标追踪实际上是一个物体在时间上的关联匹配问题,仅仅知道一帧,而不知道之前帧的信息,是不可能实现目标追踪的。这其实很好理解,我相信大家都可以理解,最重要的是三个不同的输入需要怎么进行信息的融合呢?
作者在这里用了非常简单的方法:先是通过简单的卷积层、批归一化层和激活函数,然后按位相加即可。
代码实现是这样的:
def forward(self, x, pre_img=None, pre_hm=None):
y = []
x = self.base_layer(x)
if pre_img is not None:
x = x + self.pre_img_layer(pre_img)
if pre_hm is not None:
x = x + self.pre_hm_layer(pre_hm)
其中一些函数定义如下:
self.base_layer = nn.Sequential(
nn.Conv2d(3, channels[0], kernel_size=7, stride=1,
padding=3, bias=False),
nn.BatchNorm2d(channels[0], momentum=BN_MOMENTUM),
nn.ReLU(inplace=True))
if opt.pre_img:
self.pre_img_layer = nn.Sequential(
nn.Conv2d(3, channels[0], kernel_size=7, stride=1,
padding=3, bias=False),
nn.BatchNorm2d(channels[0], momentum=BN_MOMENTUM),
nn.ReLU(inplace=True))
if opt.pre_hm:
self.pre_hm_layer = nn.Sequential(
nn.Conv2d(1, channels[0], kernel_size=7, stride=1,
padding=3, bias=False),
nn.BatchNorm2d(channels[0], momentum=BN_MOMENTUM),
nn.ReLU(inplace=True))
过程实际如下图所示,这很好理解。
接着按位相加的特征图作为一个特征提取网络的输入,作者在代码中给出了一些选项:
_network_factory = {
'resdcn': PoseResDCN,
'dla': DLASeg,
'res': PoseResNet,
'dlav0': DLASegv0,
'generic': GenericNetwork
}
这么多函数我不一一解释了,这些网络有个共同的特点,这些网络都会经历一系列下采样与一定比例的上采样,输入特征图宽高为(W,H),输出特征图宽高为(W/4,H/4)。
这里不妨以 PoseResNet为例,该特征提取网络非常简单,先通过一个ResNet下采样32倍(我相信大家都熟悉),获得特征图宽高大小(W/32,H/32)。然后以该特征图为基础执行3次上采样(反卷积,步长为2)。那么最终会获得一个宽高为(W/4,H/4)的特征图。

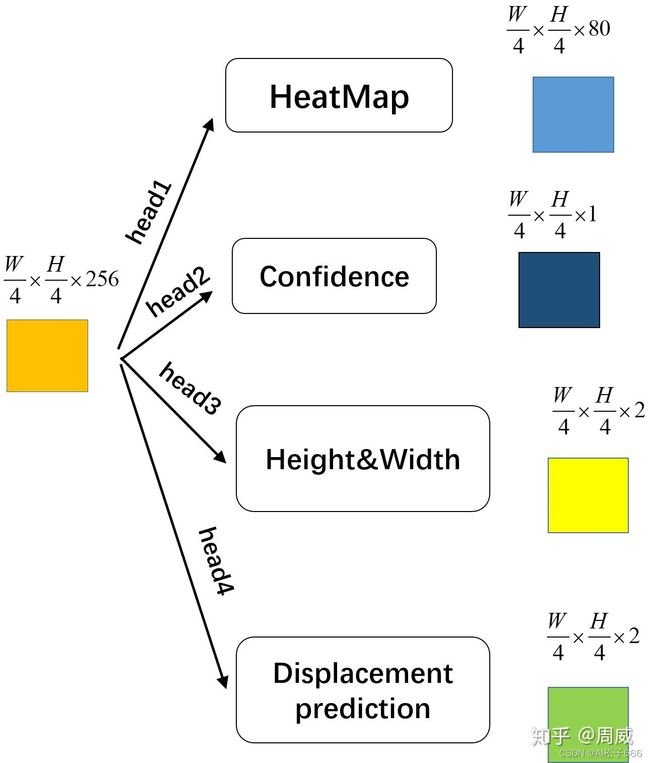
其实相较于CenterNet,CenterTrack的输出有四个,这四个输出都是由上述CNN获得的特征图分别通过各自的head模块获得的,如下图所示为简易版本。
其实上述的每个head定义也很简单,简单看了下源代码,head定义如下:
fc = nn.Sequential(conv, nn.ReLU(inplace=True), out)
其中相关的conv和out定义如下:
out = nn.Conv2d(head_conv[-1], classes,
kernel_size=1, stride=1, padding=0, bias=True)
conv = nn.Conv2d(last_channel, head_conv[0],
kernel_size=head_kernel,
padding=head_kernel // 2, bias=True)
每个head由两个卷积层,中间一个RELU激活函数组成,非常简单。最终获得的四个输出特征图如下:
(1)HeatMap,大小为(W/4,H/4,80),检测框中心点位置分布热力图
(2)Confidence,大小为(W/4,H/4,1),相关点为前景中心的置信度图
(3)Height&Width,大小为(W/4,H/4,1),点对应的检测框的宽高
(4)Displacement prediction, 大小为(W/4,H/4,2),检测框中心点在前后帧的位移(有点类似于光流)
至此,有关CenterTrack的网络结构就解析完毕了。
一些小细节
上述网络的输出,前三个我们在CenterNet解析时就已经说过了,这里不多说,有关Displacement prediction,作者在原始论文中给出相关的图例进行说明 。
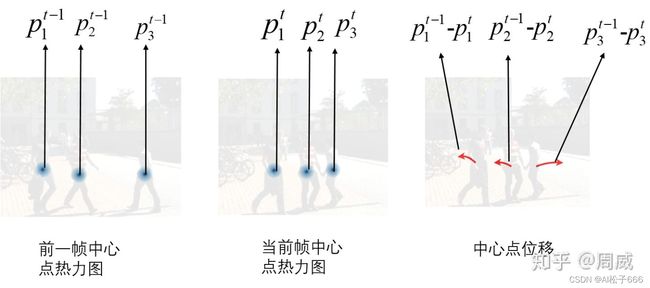


上式中,t是当前时刻,i是第i个物体, Pi是第i个物体的检测框中心点坐标。
聪明的读者肯定已经发现了,这个CenterTrack只关联连续两帧之间的检测框,那么很难形成长期的关联和依赖,这样其实非常容易产生ID切换等情况的发生。但是作者论文中提到,

也就是虽然这种CenterTrack只关联连续两帧之间的检测框,但是却很好地平衡了检测速度和检测精度,通过实验发现,该办法精度还是不错的。
总结
至此,有关CenterTrack的解析就结束了。和CenterNet类似,这种基于关键点的检测或者追踪方法非常简单,也非常容易理解。作者能够考虑到将检测和匹配问题用一个网络学习到,可真是挺令人amazing的呀!