一起自学SLAM算法:7.2 SLAM中的概率理论
连载文章,长期更新,欢迎关注:
考虑实际机器人问题中存在的众多不确定性因素,比如传感器测量噪声、电机控制偏差、计算机软件计算精度近似等。利用概率描述机器人中的不确定性,这样机器人中的不确定性就可以在概率理论框架下被计算和推演,这就是著名的概率机器人学[4]。为了帮助大家理解不确定性是如何被计算的,下面用概率机器人学[4] p6中的经典例子给大家作说明。

图7-3 概率机器人学
如图7-3所示,假设机器人在长长的走廊上漫步,由于种种原因机器人无法知道自己的位置坐标。这里可以用简单的一维坐标x表示机器人在走廊的位置,那么可以将x看成一个随机变量,x的概率分布反映其不确定特性。机器人最开始进入走廊时,完全没有先验信息可考,也就是说机器人出现在走廊的任何位置都是可能的,即x的概率分布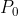 是均匀的。假设走廊上门的位置是已知量,机器人可以对其进行观测,观测可以用条件概率
是均匀的。假设走廊上门的位置是已知量,机器人可以对其进行观测,观测可以用条件概率 表示,也就是机器人位置x越靠近门,观测到门的可能性越大,观测过程的概率分布
表示,也就是机器人位置x越靠近门,观测到门的可能性越大,观测过程的概率分布 在门附近为尖峰状。观测发生前的机器人位置信息和观测信息可以帮助我们更好地计算机器人位置,这里采用简单的乘法运算来累积这些信息,那么通过观测后,机器人位置x的概率分布变为
在门附近为尖峰状。观测发生前的机器人位置信息和观测信息可以帮助我们更好地计算机器人位置,这里采用简单的乘法运算来累积这些信息,那么通过观测后,机器人位置x的概率分布变为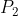 。假设机器人可以在走廊上移动,并且机器人能知道自身的位移量u,这样随机器人的移动,之前的位置信息概率分布也将发生位移量u,考虑位移量u也具有一定的不确定性,概率分布在坐标轴移动u的同时还需要乘以位移量u的概率分布,整个位移过程可以用函数
。假设机器人可以在走廊上移动,并且机器人能知道自身的位移量u,这样随机器人的移动,之前的位置信息概率分布也将发生位移量u,考虑位移量u也具有一定的不确定性,概率分布在坐标轴移动u的同时还需要乘以位移量u的概率分布,整个位移过程可以用函数![]() 表示,经过位移后机器人位置x的概率分布变为
表示,经过位移后机器人位置x的概率分布变为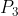 ,不仅在的基础上发生u的偏移,其尖峰的锋利度由于位移u存在的不确定性而有所下降。重复观测和位移过程,可以继续得到概率分布
,不仅在的基础上发生u的偏移,其尖峰的锋利度由于位移u存在的不确定性而有所下降。重复观测和位移过程,可以继续得到概率分布![]() 、
、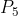 和
和![]() 。从中不难发现一个有趣的现象,如果机器人仅凭位移量u,机器人位置x的概率分布将逐渐变平坦,也就是说不确定性越来越大;而如果不断引入观测信息,机器人位置x的概率分布将向尖峰状聚集,并且随着不断增加的观测信息尖峰将变得越来越聚集,也就是说不确定性越来越小。虽然机器人运动过程和观测过程都存在不确定性,但是通过上面这种概率推演计算可以逐渐降低该不确定性。描述机器人位置x的概率分布
。从中不难发现一个有趣的现象,如果机器人仅凭位移量u,机器人位置x的概率分布将逐渐变平坦,也就是说不确定性越来越大;而如果不断引入观测信息,机器人位置x的概率分布将向尖峰状聚集,并且随着不断增加的观测信息尖峰将变得越来越聚集,也就是说不确定性越来越小。虽然机器人运动过程和观测过程都存在不确定性,但是通过上面这种概率推演计算可以逐渐降低该不确定性。描述机器人位置x的概率分布 也称为置信度,在实际工程中可以直接取置信度最大的区间作为随机变量的估计值。
也称为置信度,在实际工程中可以直接取置信度最大的区间作为随机变量的估计值。
上面只是一个简单的例子,帮助大家更好地理解不确定性被计算推演的过程。下面将结合实际的SLAM问题,对SLAM中的状态估计问题、概率运动模型、概率观测模型和概率图模型进行讨论。
7.2.1 状态估计问题
现在来讨论SLAM中的不确定性,即状态估计问题[2],如图7-4所示,机器人在环境中运动,用 表示机器人位姿,用
表示机器人位姿,用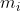 表示环境中的路标特征,机器人在运动轨迹上的每个位姿处都能观测到对应的一些路标特征(比如
表示环境中的路标特征,机器人在运动轨迹上的每个位姿处都能观测到对应的一些路标特征(比如![]() 表示机器人在
表示机器人在 处观测到了
处观测到了![]() 路标特征),运动轨迹上的相邻两个位姿可以用
路标特征),运动轨迹上的相邻两个位姿可以用 表示其运动位移量。在没有误差的理想状态,运动轨迹上的机器人位姿可以由运动位移量准确计算,由于机器人每个位姿都是准确的并且观测也是理想情况,观测路标特征的坐标也可以准确计算出来。实际情况是存在误差的,运动位移量一般由轮式里程计或者IMU反馈得到,观测z通常由机器人上的激光雷达或相机来完成,运动过程和观测过程都存在误差。随时间推移,描述机器人位姿的受误差影响将偏离于真实位姿;由于机器人位姿的偏差,加上观测误差的影响,观测到的路标特征坐标也自然会偏离于真实路标特征坐标。也就是说机器人位姿和路标特征坐标的真实值是无法直接通过观测信息得到的,因为误差渗透进了各个地方。那么SLAM问题其实就是一个状态估计问题,待估计量是机器人位姿和路标。通过机器人运动过程和观测过程所提供的信息,利用统计手段逐步减小状态估计量与真实值的偏差,从而完成对机器人位姿和路标的估计。
表示其运动位移量。在没有误差的理想状态,运动轨迹上的机器人位姿可以由运动位移量准确计算,由于机器人每个位姿都是准确的并且观测也是理想情况,观测路标特征的坐标也可以准确计算出来。实际情况是存在误差的,运动位移量一般由轮式里程计或者IMU反馈得到,观测z通常由机器人上的激光雷达或相机来完成,运动过程和观测过程都存在误差。随时间推移,描述机器人位姿的受误差影响将偏离于真实位姿;由于机器人位姿的偏差,加上观测误差的影响,观测到的路标特征坐标也自然会偏离于真实路标特征坐标。也就是说机器人位姿和路标特征坐标的真实值是无法直接通过观测信息得到的,因为误差渗透进了各个地方。那么SLAM问题其实就是一个状态估计问题,待估计量是机器人位姿和路标。通过机器人运动过程和观测过程所提供的信息,利用统计手段逐步减小状态估计量与真实值的偏差,从而完成对机器人位姿和路标的估计。

图7-4 状态估计问题
为了更清楚地说明这个状态估计问题的过程,下面以一个通用机器人框架为例,利用数学符号对其中的概率问题进行展开讨论。如图7-5所示,机器人利用激光雷达或者相机获取对环境的观测 ,同时机器人在环境中运动,运动位移量可以由速度控制量、轮式里程计或者IMU得到。机器人通过观测与运动两个过程与环境发生交互,同时运行在机器人上的SLAM算法不断地对环境路标和机器人位姿进行估计。用条件概率描述观测过程和运动过程的不确定性,分别如式(7-3)和式(7-4)所示。
,同时机器人在环境中运动,运动位移量可以由速度控制量、轮式里程计或者IMU得到。机器人通过观测与运动两个过程与环境发生交互,同时运行在机器人上的SLAM算法不断地对环境路标和机器人位姿进行估计。用条件概率描述观测过程和运动过程的不确定性,分别如式(7-3)和式(7-4)所示。

而SLAM问题就是对环境路标和机器人位姿的状态估计问题,概率描述如式(7-5)所示。
![]()
显然,可以利用概率关系,通过式(7-3)和式(7-4)来求解式(7-5)中的状态估计问题,求解方法主要有滤波和优化两种,将在7.2.4节中展开讨论。而机器人中运动和观测的概率模型具体形式,将在7.2.2节和7.2.3节中分别展开讨论。
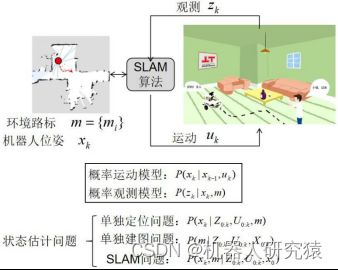
图7-5 状态估计问题的概率描述
从状态估计问题的概率表述中可以发现,单独的定位问题是在环境路标 已知的前提下对机器人位姿进行估计,单独的建图问题是在机器人各个位姿
已知的前提下对机器人位姿进行估计,单独的建图问题是在机器人各个位姿![]() 已知的前提下对环境路标进行估计,而SLAM问题是同时对机器人位姿和环境路标进行估计。由于单独定位问题的概率分布乘以单独建图问题的概率分布并不等于SLAM问题的概率分布,这也说明SLAM问题并不等效于定位和建图两个独立过程。
已知的前提下对环境路标进行估计,而SLAM问题是同时对机器人位姿和环境路标进行估计。由于单独定位问题的概率分布乘以单独建图问题的概率分布并不等于SLAM问题的概率分布,这也说明SLAM问题并不等效于定位和建图两个独立过程。
7.2.2 概率运动模型
机器人如何感知自身在环境中运动了多远呢?工程中常用的是前馈和反馈两种表示方法,如图7-6所示。在机器人底盘没有配备任何运动感知传感器的情况,可以直接利用发送给底盘的控制命令(即前馈速度![]() )来预测底盘的运动情况,一般假设底盘在
)来预测底盘的运动情况,一般假设底盘在 时间内以前馈速度
时间内以前馈速度![]() 做匀速运动,那么底盘的运动就可以用
做匀速运动,那么底盘的运动就可以用![]() 来表示。底盘实际运动速度显然会与控制命令有很多出入,所以底盘基本上都配备了轮式里程计来获取实际运动反馈量,轮式里程计并不需要底盘匀速运动的假设条件就能有效预测底盘的运动情况。这两种方式就是所谓的速度运动模型和里程计运动模型[3,4]。
来表示。底盘实际运动速度显然会与控制命令有很多出入,所以底盘基本上都配备了轮式里程计来获取实际运动反馈量,轮式里程计并不需要底盘匀速运动的假设条件就能有效预测底盘的运动情况。这两种方式就是所谓的速度运动模型和里程计运动模型[3,4]。

图7-6 前馈与反馈运动表示
1.速度运动模型
(先占个坑,有时间再来补充详细内容,大家可以直接看文后的参考文献)
2.里程计运动模型
(先占个坑,有时间再来补充详细内容,大家可以直接看文后的参考文献)
7.2.3 概率观测模型
机器人如何感知周围的环境呢?工程中常用的环境观测传感器是激光雷达和相机。激光雷达是典型的角度距离传感器,利用观测角度和测量距离表示环境路标;相机根据种类的不同,观测环境路标的方式更为丰富。关于激光雷达和相机的具体工作原理,在第4章中已经进行了详细讨论,这里不再赘述。
传感器观测分为两步:第一步是提取环境路标特征;第二步是数据关联。依据不同的传感器和提取算法,路标特征的形式将会不同。比如单线激光雷达,路标特征就可以用观测角度和测量距离来表示;而多线激光雷达,路标特征除了包含观测角度和测量距离,还可包含高层级点云轮廓信息等;而相机中,路标特征就可以用像素坐标、像素颜色、高层级特征(比如第3章中提到的SIFT、SURF、ORB等特征)等更丰富的信息表示。路标特征提取出来后,就需要判断路标特征是否为新路标,并将新出现的路标特征融入已有地图中,这就是数据关联。依据不同的传感器和路标特征表示,数据关联方法也大不相同,比如最近邻数据关联、特征匹配数据关联、分支界定数据关联等。
由于相机传感器的观测涉及的内容太复杂,关于其特征提取和数据关联的内容将放在第9章中具体的视觉SLAM算法实例中讨论。下面主要讨论激光雷达的观测,讨论重心为其观测模型的不确定性问题,主要通过波束模型和似然域模型[4]对观测不确定性进行建模,即所谓的概率观测模型。
1.波束模型
(先占个坑,有时间再来补充详细内容,大家可以直接看文后的参考文献)
2.似然域模型
(先占个坑,有时间再来补充详细内容,大家可以直接看文后的参考文献)
7.2.4 概率图模型
当有了概率运动模型和概率观测模型后,怎么描述运动模型与观测模型之间的概率关系呢?这就要引出接下来要讨论的概率图模型,概率图模型[5]是概率理论和图论结合的产物。
在概率理论中,用一种联合概率分布表示随机变量之间的关系。而图论,是一种数据结构化的表示方法。那么,将随机变量之间的概率关系用图结构进行表示,就是所谓的概率图模型。显然,图结构使得概率模型中各个随机变量之间的关系变得更为直观,并且复杂的概率计算过程可以利用图结构进行简化。
先来看看概率理论的基本内容,随机变量 的各个取值可能性大小用概率分布
的各个取值可能性大小用概率分布 表示。假如随机变量代表买彩票的中奖金额,其概率分布的形式如下式(7-25)所示。获得0元中奖金额的概率是0.999,获得100元中奖金额的概率是0.0006,获得10000元中奖金额的概率是0.0003,获得1000000元中奖金额的概率是0.0001,并且所有概率之和为1。从该概率分布中可以发现随机变量的一些特性,比如中奖金额越大概率越小。
表示。假如随机变量代表买彩票的中奖金额,其概率分布的形式如下式(7-25)所示。获得0元中奖金额的概率是0.999,获得100元中奖金额的概率是0.0006,获得10000元中奖金额的概率是0.0003,获得1000000元中奖金额的概率是0.0001,并且所有概率之和为1。从该概率分布中可以发现随机变量的一些特性,比如中奖金额越大概率越小。

上面这个例子中,随机变量的取值是离散形式,可以直接用数值对每一个概率取值情况进行列举。但是如果随机变量的取值是连续形式(比如表示温度),其概率分布就需要用概率密度函数![]() 来表示。关于随机变量离散形式与连续形式更详细讨论,请参考概率理论相关文献,就不展开了。
来表示。关于随机变量离散形式与连续形式更详细讨论,请参考概率理论相关文献,就不展开了。
在实际问题中,往往涉及到多个随机变量(比如A、B、C、D),如何描述该问题所涉及到的随机变量集合![]() 中各个随机变量的概率分布关系呢?概率加法运算和乘法运算就是最基本的描述方式,如式(7-26)和式(7-27)所示。
中各个随机变量的概率分布关系呢?概率加法运算和乘法运算就是最基本的描述方式,如式(7-26)和式(7-27)所示。

式(7-26)通过累加来求随机变量A的概率分布,该分布也称为边缘分布。式(7-27)通过链式乘法来求随机变量集合![]() 的整体分布,该分布也称为联合分布。大家可能会疑惑,为什么式(7-26)和(7-27)的计算搞得这么复杂,不能直接用各个随机变量的概率分布直接相加和相乘吗?如果随机变量集合
的整体分布,该分布也称为联合分布。大家可能会疑惑,为什么式(7-26)和(7-27)的计算搞得这么复杂,不能直接用各个随机变量的概率分布直接相加和相乘吗?如果随机变量集合![]() 中各个随机变量是相互独立的,那么直接相加和相乘是可行的。实际情况中,随机变量之间往往具有相关性,正是由于这种相关性导致计算变得复杂。值得注意的是,式(7-27)中的条件概率可以利用贝叶斯准则来简化计算。贝叶斯准则,如式(7-28)所示。贝叶斯准则更一般的形式,如式(7-29)所示。
中各个随机变量是相互独立的,那么直接相加和相乘是可行的。实际情况中,随机变量之间往往具有相关性,正是由于这种相关性导致计算变得复杂。值得注意的是,式(7-27)中的条件概率可以利用贝叶斯准则来简化计算。贝叶斯准则,如式(7-28)所示。贝叶斯准则更一般的形式,如式(7-29)所示。

贝叶斯准则等式的左边是后验概率,等式的右边是先验概率,后验概率往往不能通过观测直接计算,贝叶斯准则利用先验概率推导出了后验概率,在实际应用中非常有意义。
利用图论结构化的数据表示方式,可以让随机变量之间的依赖关系变得更为直观。图结构由节点和边组成,图中的每个节点都代表一个随机变量,连接在节点之间的边代表随机变量之间的概率依赖关系。如果连接节点的边有方向,就是有向图,也称为贝叶斯网络;如果边没有方向,就是无向图,也称为马尔可夫网络。
贝叶斯网络的结构如图7-12所示,图中的每一个节点表示一个随机变量,连接两个节点的箭头也叫有向边,箭头的方向代表两个随机变量之间的依赖为因果关系。贝叶斯网络是有向无圈图,也就是说箭头指向的路径不能闭合。根据随机变量集的属性,还可以分为静态贝叶斯网络和动态贝叶斯网络。随机变量集![]() 中的各个随机变量都对应一个特定的事件,网络结构描述各个事件之间的因果关系,就构成了静态贝叶斯网。有时候,随机变量集
中的各个随机变量都对应一个特定的事件,网络结构描述各个事件之间的因果关系,就构成了静态贝叶斯网。有时候,随机变量集![]() 是由随机变量s的时序状态构成,每个状态
是由随机变量s的时序状态构成,每个状态 产生对应的观测
产生对应的观测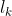 ,两个状态节点之间的箭头表示状态更新过程,状态节点与观测节点之间的箭头表示观测过程,就构成了动态贝叶斯网。很显然,动态贝叶斯网络可以描述机器人运动模型与观测模型之间的概率关系,稍后将重点展开讲解。
,两个状态节点之间的箭头表示状态更新过程,状态节点与观测节点之间的箭头表示观测过程,就构成了动态贝叶斯网。很显然,动态贝叶斯网络可以描述机器人运动模型与观测模型之间的概率关系,稍后将重点展开讲解。

图7-12 贝叶斯网络
构建图的目的是为了更方便地表示概率分布,这个过程也称为图结构参数化。贝叶斯网络的参数化,是将随机变量集上的联合概率分布分解为局部条件概率分布的乘积,也就是式(7-27)所示的链式乘法运算。由于图结构给出了随机变量之间具体的依赖关系,所以条件概率计算过程将比式(7-27)更为简洁,以图7-12a为例,其对应的联合概率分布如式(7-30)所示。

可以看出,联合概率分布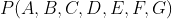 分解成了各个随机变量条件概率分布的乘积。讨论更一般的情况,将图结构中各个随机变量记为随机变量集
分解成了各个随机变量条件概率分布的乘积。讨论更一般的情况,将图结构中各个随机变量记为随机变量集![]() ,式(7-30)可以写成式(7-31)所示的更一般形式。其中随机变量
,式(7-30)可以写成式(7-31)所示的更一般形式。其中随机变量 的条件概率分布记为
的条件概率分布记为![]() 联合概率分布能被分解成乘积项,正是基于随机变量在局部的这种条件独立。
联合概率分布能被分解成乘积项,正是基于随机变量在局部的这种条件独立。
![]()
马尔可夫网络的结构如图7-13所示,图中的每一个节点表示一个随机变量,连接两个节点的边是没有方向的,边代表两个随机变量之间的相关性。在贝叶斯网络中,有向边代表了随机变量之间的显示关系,即直观上知道两个随机变量的因果关系。然而在很多实际问题中,随机变量之间的显示因果关系很难知晓,往往只知道两随机变量之间具有某种相关性,具体怎么相关不得而知。无向图正是用来构建这种非直观相关关系的模型,相关性是不分方向的,所以连接两节点的边是没有方向的。
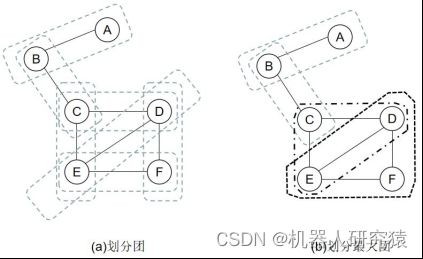
图7-13 马尔可夫网络
相比于贝叶斯网络的参数化过程,马尔可夫网络的参数化更为抽象,其联合概率分布分解为团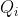 的势能函数
的势能函数![]() 的乘积。团是一个节点集合,团中的节点必须两两之间都有边连接。以团中包含的随机变量作为自变量,构建团的势能函数。团的势能函数是一个抽象函数,需要根据实际问题中被具体化为特定形式。以每条边上的两个节点作为一个团是最简单的,如图7-13a所示,划分出来的团依次为
的乘积。团是一个节点集合,团中的节点必须两两之间都有边连接。以团中包含的随机变量作为自变量,构建团的势能函数。团的势能函数是一个抽象函数,需要根据实际问题中被具体化为特定形式。以每条边上的两个节点作为一个团是最简单的,如图7-13a所示,划分出来的团依次为![]() 、
、![]() 、
、![]() 、
、![]() 、
、![]() 、
、![]() 、
、![]() ,则其联合概率分布可用式(7-32)所示的势能函数乘积表示。其中Z是归一化常数,以确保计算结果仍为合法概率分布。
,则其联合概率分布可用式(7-32)所示的势能函数乘积表示。其中Z是归一化常数,以确保计算结果仍为合法概率分布。
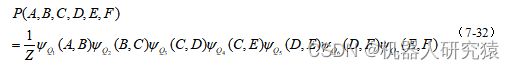
显然上面的分解方法可以更简洁,这里引入最大团的概念。如果往团中加入团外的其他任何节点,将不再成团,这样的团就是最大团。上面的团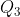 、
、![]() 、
、![]() 可以合并成一个最大团
可以合并成一个最大团![]() ,团
,团![]() 、
、![]() 、
、![]() 可以合并成一个最大团
可以合并成一个最大团![]() 。式(7-31)中的联合概率分布在最大团上表示,将更简洁,如式(7-33)所示。
。式(7-31)中的联合概率分布在最大团上表示,将更简洁,如式(7-33)所示。

讨论更一般的情况,将图结构中各个随机变量记为随机变量集![]() ,图结构划分出来的所有最大团记为
,图结构划分出来的所有最大团记为![]() 。那么式(7-33)可以写成式(7-34)所示更一般的形式。
。那么式(7-33)可以写成式(7-34)所示更一般的形式。

以一个最大团中的随机变量为自变量构造出来的势能函数只能笼统地表示各随机变量之间的整体关系,各随机变量之间更直接的关系显然没有表现出来。将势能函数进行因式分解,分解出来的因子项能描述随机变量间更具体的关系。假如式(7-33)中的![]() 团的势能函数
团的势能函数![]() 可以分解成为3个因子项,如式(7-35)所示。
可以分解成为3个因子项,如式(7-35)所示。

当然,一个函数的因式分解结果一般不唯一,比如式(7-35)还可以分解成式(7-36)所示的形式。
![]()
这样,马尔可夫网络就可以用因子图更为显示地表示。式(7-35)和(7-36)的因子图表示如图7-14所示。因子图中,除了随机变量节点(圆形节点),还引入了另一种因子节点(方形节点),因子节点与随机变量节点用边连接。很显然,各个因子函数对随机变量间的概率分布关系描述得更详细,也就是说因子图是马尔可夫网络的细粒度参数化形式。
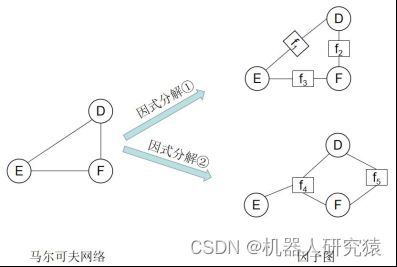
图7-14 因子图
当然,贝叶斯网络也是可以转化成马尔可夫网络或因子图来表示。如图7-15所示。关于转化的具体过程就不展开了,感兴趣的读者可以参考文献[6] p399~411中的内容。
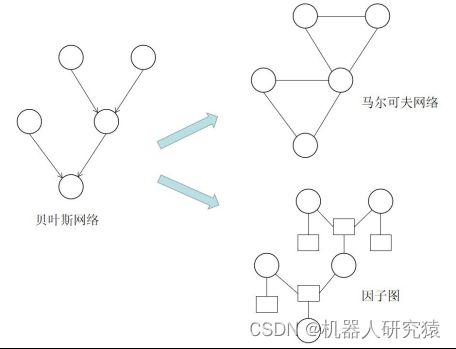
图7-15 贝叶斯网络转化成马尔可夫网络或因子图
最后,归纳总结一下概率图模型中各主要模型之间的关系,如图7-16所示。按图中的边是否有方向,可以分为有向图和无向图,分别对应贝叶斯网络和马尔可夫网络。贝叶斯网络可以分为静态贝叶斯网络和动态贝叶斯网络,动态贝叶斯网络中随机变量集![]() 是由随机变量s的时序状态构成,最常见的动态贝叶斯网络应用举例就是隐马尔可夫模型和卡尔曼滤波。而马尔可夫网络细粒度参数化后,就是因子图,最常见的马尔可夫网络应用举例有吉布斯/玻尔兹曼机和条件随机场。值得注意的是,贝叶斯网络、马尔可夫网络和因子图这三者之间可以互相转化。
是由随机变量s的时序状态构成,最常见的动态贝叶斯网络应用举例就是隐马尔可夫模型和卡尔曼滤波。而马尔可夫网络细粒度参数化后,就是因子图,最常见的马尔可夫网络应用举例有吉布斯/玻尔兹曼机和条件随机场。值得注意的是,贝叶斯网络、马尔可夫网络和因子图这三者之间可以互相转化。

图7-16 概率图模型
概率图模型是人工智能领域热门研究方向之一,概率图模型利用图结构表示随机变量之间的依赖关系,在图结构中能非常方便地进行推理和学习,比如模式识别、自然语言处理、机器人SLAM等。本章讨论重点在SLAM上,所以下面将展开讲解利用概率图模型进行SLAM问题的表示及推理过程。
1.贝叶斯网络
(先占个坑,有时间再来补充详细内容,大家可以直接看文后的参考文献)
2.因子图
(先占个坑,有时间再来补充详细内容,大家可以直接看文后的参考文献)
参考文献
【1】 张虎,机器人SLAM导航核心技术与实战[M]. 机械工业出版社,2022.