pytorch 神经网络基础入门笔记【b站小土堆】
文章目录
- python深度学习
- 配置环境
-
- anaconda+pycharm+pytorch
- python学习中的两大法宝函数
- 加载数据
- Tensorboard使用
- torchvision中的transforms
-
- tensor数据类型
- transform该如何使用
- 为什么我们需要Tensor类型
- 更好的使用transforms
-
- ToTensor
- Normalize
- Resize
- Compose
- RandomCrop
- 总结
- torchvision数据集的使用
- DataLoader的使用
- 神经网络的基本骨架 nn.Module的使用
- 神经网络基本结构的使用
-
- 1. 卷积操作
- 2. 最大化池的使用
- 3. 非线性激活
- 4. 线性层
- 搭建小实战和Sequential使用
- 损失函数与反向传播
- 优化器
- 模型的保存与读取
b站课程PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
虽然是CV的内容,不过胜在浅,很适合像我这样啥也不懂
该篇笔记并不完整,因为大部分代码都没打上去,推荐0基础的去看这个课,我的笔记可以提供一些帮助,主要还是自用
python深度学习
配置环境
anaconda+pycharm+pytorch
anaconda创建了虚拟环境
上面那个是今天创建的
下面那个是anaconda base的
希望以后能找到

在conda里自己创建的环境,都在anaconda3/envs里可以找到
python学习中的两大法宝函数
对于一个package(pytorch)来说
- dir():打开、看见
- help():说明书
加载数据
深度学习的数据集一半都是有规定结构的
通过Dataset()读取数据集
读取数据集路径由三部分构成
root_dir 根目录
label_dir 标签(比如apple/banana)
Img_name 图片名(比如000001.jpg)
Tensorboard使用
-
在pycharm设置环境
-
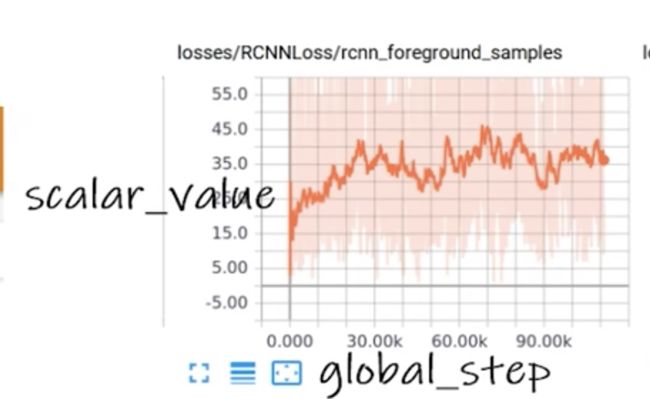
add_scalar()方法
def add_scalar(
self,
tag,
scalar_value,
global_step=None,
walltime=None,
new_style=False,
double_precision=False,
):
"""Add scalar data to summary.
Args:
tag (str): Data identifier
scalar_value (float or string/blobname): Value to save
global_step (int): Global step value to record
walltime (float): Optional override default walltime (time.time())
with seconds after epoch of event
new_style (boolean): Whether to use new style (tensor field) or old
style (simple_value field). New style could lead to faster data loading.
Examples::
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x = range(100)
for i in x:
writer.add_scalar('y=2x', i * 2, i)
writer.close()
Expected result:
.. image:: _static/img/tensorboard/add_scalar.png
:scale: 50 %
- 下载
pip install tensorboard - 打开log
终端输入:tensorboard --logdir logs
格式:logdir 事件文件所在文件夹名
默认为6006端口,为防止端口冲突可以修改端口:
tensorboard --logdir logs --port=6007
打开后,应该是有函数图片的,如果没有请检查一下,输入指令时终端目录一定要是log文件夹的父目录(不是就cd一下),还要激活你创建的虚拟环境
- Add_image()方法
- 注意一下图片的size,dataformats参数指定
def add_image(
self, tag, img_tensor, global_step=None, walltime=None, dataformats="CHW"
):
"""Add image data to summary.
Note that this requires the ``pillow`` package.
Args:
tag (str): Data identifier
img_tensor (torch.Tensor, numpy.ndarray, or string/blobname): Image data
global_step (int): Global step value to record
walltime (float): Optional override default walltime (time.time())
seconds after epoch of event
dataformats (str): Image data format specification of the form
CHW, HWC, HW, WH, etc.
- 利用opencv读取图片,获得numpy型图片数据
- 用opencv导入图像需要注意BGR转成RGB
- 从PIL到numpy,需要在add_image()中指定shape中每一个数字/维度表示的含义
- step多少。主要显示多少训练中的过程
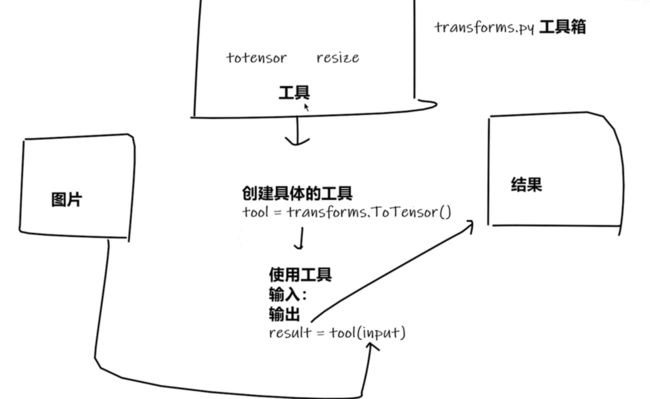
torchvision中的transforms
其实就是一个py文件,像一个工具箱
其中有很多工具,包括
- totensor
- resize
图片经过这个工具,会输出一个结果
tensor数据类型
其python的用法
通过 transform.ToTenser去看两个问题
- transform该如何使用(python)
- 为什么我们需要Tenser数据类型
transform该如何使用
def __call__(self, pic):
"""
Args:
pic (PIL Image or numpy.ndarray): Image to be converted to tensor.
Returns:
Tensor: Converted image.
"""
return F.to_tensor(pic)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
上面的代码相当于实例化了一个ToTensor()类
然后调用了其中的call方法(—call—函数起到了直接调用类实例的作用)
tensor_img = tensor_trans(img)调用了call方法,相当于tennsor_img = tensor_trans.call(img)
实例化对象后面加个括号就是调用__call__方法(__call__是魔术方法,自动触发)
进行完这个步骤后,整个过程应该是更加具体了
tool是transforms的实例,result是tool这个实例的结果
为什么我们需要Tensor类型
Tensor类包装了我们神经网络所需要的一些基础的参数
更好的使用transforms
属于是对上面的补充

PIL、tensor、narrays三种类型输入,对应不同方法,需要注意
几个方法
ToTensor
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path = "../data/hymenoptera_data/train/ants_image/0013035.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs")
## ToTensor
# 将图片转换为Tensor类型,并通过Tenserboard显示
tensor_trans = transforms.ToTensor()
img_tensor = tensor_trans(img)
writer.add_image("tensor_img", img_tensor) # 上次传的是numpy型图片,这次传tensor类型的
Normalize
## Normalize 归一化
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("image_img", img_norm)
writer.close()
Resize
# 将图片短边缩放至x,长宽比保持不变 transforms.Resize(x)
## Resize
print(img.size)
trans_resize = transforms.Resize((512,512))
# img PIL -> resize -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> totensor -> img_resize tensor
img_resize = tensor_trans(img_resize) # 只有tensor格式才能在tensorboard上显示
writer.add_image("Resize", img_resize, 0)
print(img_resize)
Compose

# Compose
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2, tensor_trans])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2, 1)
- 这里就是说compose需要你提供以恶搞转换的列表
- 列表中第一个trans_resize_2是转化图片大小
- 第二个将这个转化为tensor格式
- 相当于一个合并的功能,按照写的列表去执行流程
- 要注意前一个的输出,要跟后一个的输入相匹配
RandomCrop
随机裁剪
# RandomCrop
trans_random = transforms.RandomCrop(512)
trans_compose_2 = transforms.Compose([trans_random, tensor_trans])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("ImgCrop", img_crop, 1)
总结
注意方法的输入与输出
学会看帮助文档
学会看源码,关注方法要什么参数
不知道返回值的时候
-
print
-
print(type())
-
Debug
一般来说,和图像本身处理相关的不改变数据格式,数学相关的都是基于Tensor,中间的桥梁是toTensor
torchvision数据集的使用
下载的数据集
import torchvision
# 转成tensor数据类型
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True)
print(test_set[0])
print(test_set.classes)
img, target = test_set[0]
print(img)
print(target)
print(test_set.classes[target])
img.show()
writer = SummaryWriter("p10");
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set",img,i)
writer.close()
Tensorboard logdir p10
DataLoader的使用
dataloader是将数据如何加载到神经网络中,从dataset中取数据
其一些参数:
dataset: Dataset[T_co]
batch_size: Optional[int]
num_workers: int
pin_memory: bool
drop_last: bool
timeout: float
sampler: Union[Sampler, Iterable]
pin_memory_device: str
prefetch_factor: int
_iterator : Optional['_BaseDataLoaderIter']
__initialized = False
- dataset加载的数据集
- batch_size:一次抽几张
- shuffle:第二次抽牌和第一次抽牌,是否打乱,默认是false,一般为true
- num_workers:几个进程进行加载
如果报了broken pipe可以把这个设置为0,看能否解决问题
- drop_last抽牌之后,如果有剩余的是舍去还是不舍去
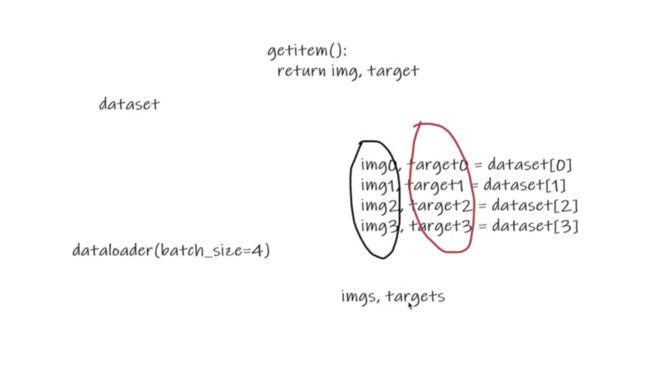
- 测试代码
import torchvision
from torch.utils.data import DataLoader
# 准备的测试集
from torch.utils.tensorboard import SummaryWriter
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_set, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
# 测试数据集中第一张图片及target【就是标签】
img, target = test_set[0]
print(img.shape)
print(target)
# 输出
# torch.Size([3, 32, 32]) 三通道,32长,32宽
# 3 # 标签为3 test_set.classes里的第三种
writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:
imgs, targets = data
print(imgs.shape)
print(targets)
writer.add_images("test_data", imgs, step) # 注意方法是add_images,有s
step = step + 1
writer.close()
# 输出 其中一次循环
# torch.Size([4, 3, 32, 32]) #前面的4是4张图片的意思,一次取四张图 默认是随机抓取
# tensor([2, 5, 5, 6]) # 4张图片的标签
神经网络的基本骨架 nn.Module的使用
Neural Network
nn
container是骨架
- 例子
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
- 继承nn.Module
- 主要是写两个函数
- 初始化
- forward(前向传播)
- 例子中的x就是输入经过了一次卷积、一次非线性、又一次卷积、又一次非线性的前向传播处理
- pycharm继承后重写操作
- code->generate->重写方法
- 测试代码
- 因为集成的nn.Module中forword方法是__call__()方法的实现,可调用对象会调用__call__()方法
import torch
from torch import nn
class Wang(nn.Module):
def __init__(self) -> None:
super().__init__()
def forward(self, input):
output = input+1
return output
wang = Wang()
x = torch.tensor(1) # 将1转换为tensor格式并赋值
output = wang(x) # x(input)->神经网络->output
print(output)
- 输出结果:tensor(2)
神经网络基本结构的使用
1. 卷积操作
卷积层
演示卷积代码
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
from torch import nn
from torch.nn import Conv2d
class Wang(nn.Module):
def __init__(self):
super(Wang, self).__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self, x):
x = self.conv1(x)
return x
- 打印
wang = Wang()
print(wang)
输出:Wang(
(conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1))
)说明:该神经网络Wang有一层卷积层conv1,参数定义in_channel=3,out_channel=6,卷积核大小为3*3,stride(1,1)表示横向走一步纵向走一步
- 加入图片演示
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
from torch import nn
from torch.nn import Conv2d
dataset = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Wang(nn.Module):
def __init__(self):
super(Wang, self).__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
def forward(self, x):
x = self.conv1(x)
return x
wang = Wang()
print(wang)
writer = SummaryWriter("logs")
step = 0
for data in dataloader:
imgs, targrts = data
output = wang(imgs)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30])->[-1, 3, 30, 30] -1为自动根据后面数值计算
# 这里的卷积核个数确实是2,实际操作中一般都是大于等于两个卷积和的,并且我们不会去观察其中间的输出,
# 所以通道数变成几都无所谓,这里只是up想让结果可视化,但通道只有等于3的时候才能可视化
output = torch.reshape(output, (-1, 3, 30, 30) )
writer.add_images("output", output, step)

2. 最大化池的使用
最大化池
Dilation:空洞卷积
ceil/floor:向上/下取整
ceil_mode =True在边缘的时候进行保留
ceil_mode =False在边缘的时候不进行保留
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]], dtype=torch.float32)
input = torch.reshape(input, (-1,1,5,5))
print(input.shape)
class Wang(nn.Module):
def __init__(self):
super(Wang, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
wang = Wang()
output = wang(input)
print(output)
-
为什么要用最大池化
-
保留特征但是数据量减少
-
效果类似于把1080p变成720p
-
池化不影响通道数
池化并不是一定需要,参考李宏毅老师所讲,alphago 只有卷积与激活函数,没有池化
- 使用图片的效果

3. 非线性激活
提一下padding层,填充边缘的,一般用不到,就算在卷积层也有相应直接填充0的
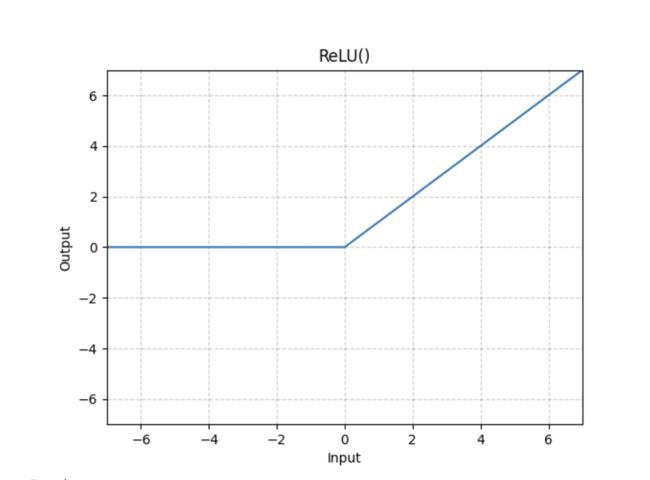
- 两个比较常用的
- RELU
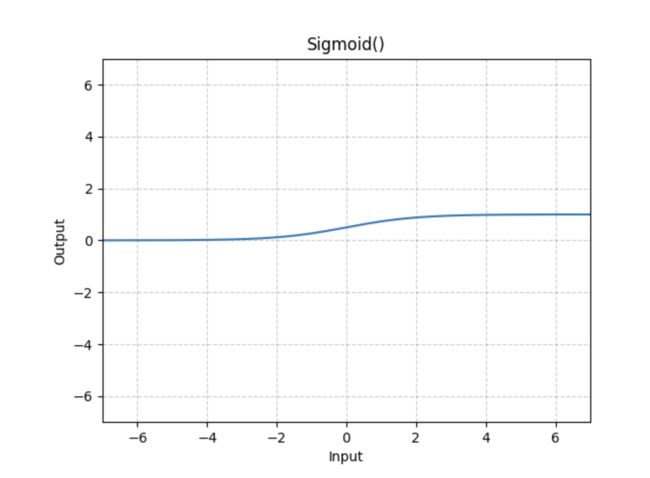
- Sigmoid
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# input = torch.tensor([[1,-0.5],
# [-1,3]], dtype=torch.float32)
#
# output = torch.reshape(input,(-1,1,2,2))
dataset = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Wang(nn.Module):
def __init__(self):
super(Wang, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input) # 默认inplace是false,不直接替换
return output
wang = Wang()
writer = SummaryWriter("logs_sigmoid")
step = 0
for data in dataloader:
imgs, targrts = data
writer.add_images("input", imgs,global_step = step)
output = wang(imgs)
writer.add_images("output", output, step)
step += 1
writer.close()
- 图像处理结果

- 加入非线形使得神经网络的泛化能力更好,不会什么都直愣愣的
4. 线性层
全链接的操作,把数据变成一层
四个参数:[batchsize,深度,高,宽]
全链接后变成[batchsize1,深度1,高1,宽自设]
为什么要展平:在普通神经网络里,输入是一个二维矩阵,不需要摊平。而在卷积神经网络里,在网络的最后几层里,会把卷积层摊平放到全连接里进行计算。
搭建小实战和Sequential使用
搭建一个经典的神经网络
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Wang(nn.Module):
def __init__(self):
super(Wang, self).__init__()
self.conv1 = Conv2d(3, 32, 5, padding=2) # 参数:in_channel out_channel kernel_size padding
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32,32,5,padding=2)
self.maxpool2 = MaxPool2d(2) # 池化可以起到非线性化的作用
self.conv3 = Conv2d(32,64,5,padding=2) # kernel是5的话 要保证 kernel的中心块能置于输入的四个角 才能尺寸不变 5的kernal 中心块的个方向都有2个块 所以padding是2
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
# 全链接
self.linear1 = Linear(1024,64)
self.linear2 = Linear(64,10) # 最后分成10个类别
def forward(self,x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
wang = Wang()
print(wang)
input = torch.ones((64,3,32,32))
output = wang(input)
print(output.shape)
加入序列化sequence后,代码就十分简洁
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Wang(nn.Module):
def __init__(self):
super(Wang, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self,x):
x = self.model1(x)
return x
wang = Wang()
print(wang)
input = torch.ones((64,3,32,32))
output = wang(input)
print(output.shape)
writer = SummaryWriter("logs_seq")
writer.add_graph(wang, input)
writer.close()
然后就得到了可视化的网络
损失函数与反向传播
loss 误差(output和target的差距)
loss越小越好,通过loss function去接近目标
利用误差消除误差
目的
- 计算实际输出和目标的差距
- 为我们更新输出提供一定的依据(反向传播)
损失函数
只有了损失,才能计算梯度,然后才能更新参数,趋向最优
-
L1Loss函数
import torch from torch.nn import L1Loss inputs = torch.tensor([1,2,3] ,dtype=torch.float32) targets = torch.tensor([1,2,5] ,dtype=torch.float32) inputs = torch.reshape(inputs,(1,1,1,3)) # 这个变形相当于转换为tensor类型,[1,2,3]就是最后的(1,3) targets = torch.reshape(targets,(1,1,1,3)) print(inputs) loss = L1Loss() result = loss(inputs,targets) print(result)- 计算[1,2,3]与[1,2,5]的loss(平均或求和都可以设置,这里是平均)
- loss= (0+0+2)/3=0.667
- 跟程序输出结果一致
-
MSEloss
- 每个差的平方和
-
CrossEntroyLoss
- 交叉熵
- 在分类问题中常用的损失函数
- 输出评估分数为[0.1,0.2,0.3]时,class1的交叉熵
x = torch.tensor([0.1,0.2,0.3])
y = torch.tensor([1])
x = torch.reshape(x,(1,3))
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x,y)
print(result_cross)
-
总结:根据需求去选用loss function,同时要注意输入和输出
-
loss计算实际输出和目标之间的差距
-
为我们更新输出提供了一定的依据(反向传播)。
-
比如说对于卷积层来说,每个卷积核其中的参数是我们需要调优的,每个节点(参数)都被设置了一个梯度grad,根据梯度进行优化,达到整个loss下降的目的
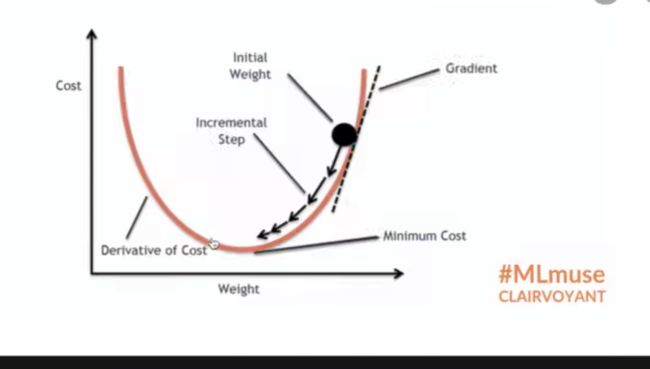
科普:反向传播意思就是,尝试如何调整网络过程中的参数才会导致最终的loss变小(因为是从loss开始推导参数,和网络的顺序相反,所以叫反向传播),以及梯度的理解可以直接当成“斜率”
- 在上一节课的模型基础上添加loss调试
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=1, drop_last=True)
class Wang(nn.Module):
def __init__(self):
super(Wang, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self,x):
x = self.model1(x)
return x
wang = Wang()
loss = nn.CrossEntropyLoss()
for data in dataloader:
imgs, targets = data
outputs = wang(imgs)
result_loss = loss(outputs,targets)
result_loss.backward()
print(result_loss)
# print(output)
# print(targets)
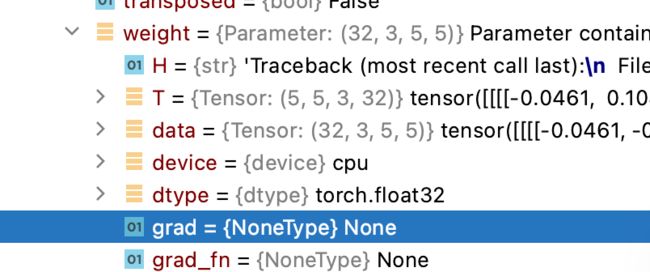
断点打在第40行调试,在40行没执行前,一步步找到神经网络某个卷积层,发现其weight权重参数下有个grad是空的
运行40行后,发现grad有值
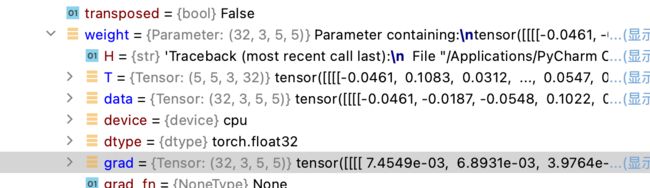
- 下一节的优化器,就会根据这些梯度grad,对参数进行更新,使整个loss变小, 模型更好
- 而这些梯度grad,必须要通过反向传播,才能计算
优化器
torch.optim
- 先构建一个优化器
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer = optim.Adam([var1, var2], lr=0.0001)
- 优化步骤
for input, target in dataset:
optimizer.zero_grad()# 一定要先清零,以防上一个循环中每个参数对应梯度的影响
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
第四行:反向传播,得到每个要更新参数对应的梯度 ;
第五行:每个参数会根据上一步得到的梯度进行优化
- 再讲讲优化器的算法

- 打开其中一个优化器后发现,除了要传入神经网络需要调节的params是啥,和lr(learning rate)学习速率外,其余的参数都是不同算法不一样的
,download=True)
dataloader = DataLoader(dataset, batch_size=1, drop_last=True)
class Wang(nn.Module):
def __init__(self):
super(Wang, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10),
)
def forward(self,x):
x = self.model1(x)
return x
wang = Wang()
loss = nn.CrossEntropyLoss()
optim = torch.optim.SGD(wang.parameters(),lr=0.01) # 学习速率不大不小,开始我们选用小的学习速率
for epoch in range(5):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = wang(imgs) # 前向传播输出
result_loss = loss(outputs,targets) # 计算loss
optim.zero_grad() # 清空优化器中的grad
result_loss.backward() # 反向传播,生成grad
optim.step() # 优化器根据grad计算,调整神经网络中的参数
running_loss += result_loss
print(running_loss)
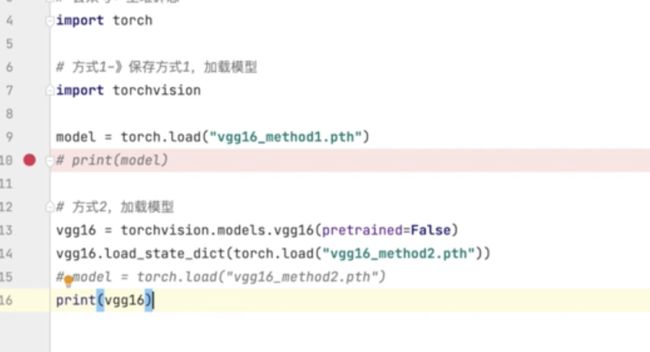
模型的保存与读取
-
模型保存
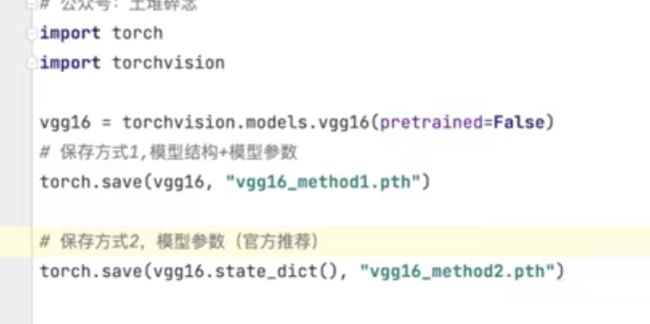
-
模型加载