认识PASCAL VOC数据集(目标检测)
数据集详解(只介绍目标检测中):
目标检测主要用Annotations保存标签数据、ImageSets保存具体数据集的索引、JPEGImages保存图片。其他为分割。有20个类别
Annotations:
文件保存位置:VOC2012/Annotations的xml文件
保存信息:
1、物体name:如fperson;
2、size:width,height,depth
3、bbox: xmin、xmax、ymin、ymax

ImageSets:
包括 Action,Layout,Main,Segmentation 四个文件夹。
Action:存放的是人的动作(例如running、jumping等等)
Layout:存放的是具有人体部位的数据(人的head、hand、feet等等,这也是VOC challenge的一部分
Main:存放的是图像物体识别的数据,总共分为20类。
Segmentation:存放的是可用于分割的数据。
ImageSets/Main/ 文件夹以 , {class}_trainval.txt ,{class}_val.txt 的格式命名。 train.txt, val.txt 例外
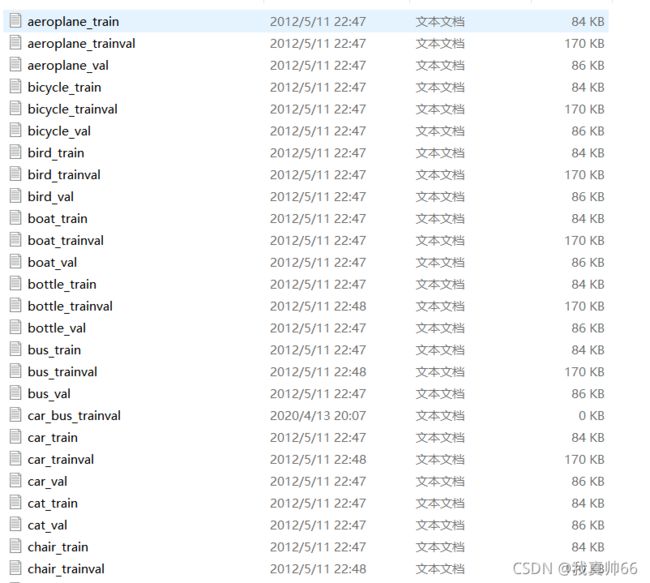
1、 {class}_train.txt 保存类别为 class 的训练集的所有索引,每一个 class 的 train 数据都有 5717 个。
2、{class}_val.txt 保存类别为 class 的验证集的所有索引,每一个 class 的val数据都有 5823 个
3、{class}_trainval.txt 保存类别为 class 的训练验证集的所有索引,每一个 class 的val数据都有11540 个
每个文件内容:
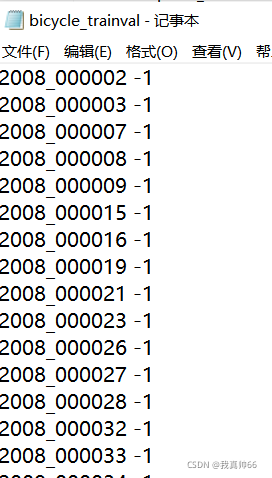
其中1表示正样本,-1表示负样本
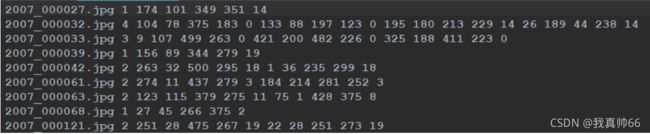
VOC2012/ImageSets/Main/train.txt 保存了所有训练集的文件名,ImageSets/Main/val.txt 保存了所有验证集的文件名从 VOC2012/JPEGImages/ 找到文件名对应的图片文件,VOC2012/Annotations找到文件名对应的标签文件
JPEGImages:
需要解码获得图像数据
import os
import sys
import os.path
import random
import numpy as np
import torch
import torch.utils.data as data
import torchvision.transforms as transforms
import cv2
class yoloDataset(data.Dataset):
'''
自定义封装数据集
'''
image_size = 224
def __init__(self,root,list_file,train,transform):
print('数据初始化')
self.root=root
self.train = train
self.transform=transform #对图像转化
self.fnames = [] #图像名字
self.boxes = []
self.labels = []
self.mean = (123,117,104) #RGB均值
with open(list_file) as f:
lines = f.readlines()
# 遍历voc2012train.txt每一行
for line in lines:
splited = line.strip().split()
# 赋值图像名字
self.fnames.append(splited[0])
# 赋值一张图的物体总数
num_faces = int(splited[1])
box=[]
label=[]
# 遍历一张图的所有物体
# bbox坐标(4个值) 物体对应的类的序号(1个值) 所以要加5*i
for i in range(num_faces):
x = float(splited[2+5*i])
y = float(splited[3+5*i])
x2 = float(splited[4+5*i])
y2 = float(splited[5+5*i])
c = splited[6+5*i]
box.append([x,y,x2,y2])
label.append(int(c)+1)
# bbox 写入所有物体的坐标值
self.boxes.append(torch.Tensor(box))
# label 写入标签
self.labels.append(torch.LongTensor(label))
# 数据集中图像总数
self.num_samples = len(self.boxes)
def __getitem__(self,idx):
'''
继承Dataset,需实现该方法,得到一个item
'''
fname = self.fnames[idx]
# 读取图像
img = cv2.imread(os.path.join(self.root+fname))
# clone 深复制,不共享内存
# 拿出对应的bbox及 标签对应的序号
boxes = self.boxes[idx].clone()
labels = self.labels[idx].clone()
# 如果为训练集,进行数据增强
if self.train:
# 随机翻转
img, boxes = self.random_flip(img, boxes)
#固定住高度,以0.6-1.4伸缩宽度,做图像形变
img,boxes = self.randomScale(img,boxes)
# 随机模糊
img = self.randomBlur(img)
# 随机亮度
img = self.RandomBrightness(img)
# 随机色调
img = self.RandomHue(img)
# 随机饱和度
img = self.RandomSaturation(img)
# 随机转换
img,boxes,labels = self.randomShift(img,boxes,labels)
h,w,_ = img.shape
boxes /= torch.Tensor([w,h,w,h]).expand_as(boxes)
img = self.BGR2RGB(img) #因为pytorch自身提供的预训练好的模型期望的输入是RGB
img = self.subMean(img,self.mean) #减去均值
img = cv2.resize(img,(self.image_size,self.image_size)) #改变形状到(224,224)
# 拿到图像对应的真值,以便计算loss
target = self.encoder(boxes,labels)# 7x7x30 # 一张图被分为7x7的网格;30=(2x5+20)
#一个网格预测两个框 一个网格预测所有分类概率,VOC数据集分类为20类
# 图像转化
for t in self.transform:
img = t(img)
#返回 最终处理好的img 以及 对应的 真值target(形状为网络的输出结果的大小)
return img,target
def __len__(self):
'''
继承Dataset,需实现该方法,得到数据集中图像总数
'''
return self.num_samples
def encoder(self,boxes,labels):
'''
boxes (tensor) [[x1,y1,x2,y2],[x1,y1,x2,y2],[]]
labels (tensor) [...]
return 7x7x30
'''
target = torch.zeros((7,7,30))
cell_size = 1./7
# boxes[:, 2:]代表 2: 代表xmax,ymax
# boxes[:, :2]代表 :2 代表xmin,ymin
# wh代表 bbox的宽(xmax-xmin)和高(ymax-ymin)
wh = boxes[:,2:]-boxes[:,:2]
# bbox的中心点坐标
cxcy = (boxes[:,2:]+boxes[:,:2])/2
# cxcy.size()[0]代表 一张图像的物体总数
# 遍历一张图像的物体总数
for i in range(cxcy.size()[0]):
# 拿到第i行数据,即第i个bbox的中心点坐标(相对于整张图,取值在0-1之间)
cxcy_sample = cxcy[i]
# ceil返回数字的上入整数
# cxcy_sample为一个物体的中心点坐标,求该坐标位于7x7网格的哪个网格
# cxcy_sample坐标在0-1之间 现在求它再0-7之间的值,故乘以7
# ij长度为2,代表7x7框的某一个框 负责预测一个物体
ij = (cxcy_sample/cell_size).ceil()-1
# 每行的第4和第9的值设置为1,即每个网格提供的两个真实候选框 框住物体的概率是1.
#xml中坐标理解:原图像左上角为原点,右边为x轴,下边为y轴。
# 而二维矩阵(x,y) x代表第几行,y代表第几列
# 假设ij为(1,2) 代表x轴方向长度为1,y轴方向长度为2
# 二维矩阵取(2,1) 从0开始,代表第2行,第1列的值
# 画一下图就明白了
target[int(ij[1]),int(ij[0]),4] = 1
target[int(ij[1]),int(ij[0]),9] = 1
# 加9是因为前0-9为两个真实候选款的值。后10-20为20分类 将对应分类标为1
target[int(ij[1]),int(ij[0]),int(labels[i])+9] = 1
# 匹配到的网格的左上角的坐标(取值在0-1之间)(原作者)
# 根据二维矩阵的性质,从上到下 从左到右
xy = ij*cell_size
#cxcy_sample:第i个bbox的中心点坐标 xy:匹配到的网格的左上角相对坐标
# delta_xy:真实框的中心点坐标相对于 位于该中心点所在网格的左上角 的相对坐标,此时可以将网格的左上角看做原点,你这点相对于原点的位置。取值在0-1,但是比1/7小
delta_xy = (cxcy_sample -xy)/cell_size
# x,y代表了检测框中心相对于网格边框的坐标。w,h的取值相对于整幅图像的尺寸
# 写入一个网格对应两个框的x,y, wh:bbox的宽(xmax-xmin)和高(ymax-ymin)(取值在0-1之间)
target[int(ij[1]),int(ij[0]),2:4] = wh[i]
target[int(ij[1]),int(ij[0]),:2] = delta_xy
target[int(ij[1]),int(ij[0]),7:9] = wh[i]
target[int(ij[1]),int(ij[0]),5:7] = delta_xy
return target
此处未定义随机裁剪等图像转化的函数
参考:
PASCAL VOC 2012 数据集详解_wenxueliu的博客-CSDN博客_voc2012数据集