PTA 天梯赛习题集 L1-064 估值一亿的AI核心代码 部分测试点错误分析和排查测试点错误技巧的分享附带详细题解
估值一亿的AI核心代码

以上图片来自新浪微博。
本题要求你实现一个稍微更值钱一点的 AI 英文问答程序,规则是:
无论用户说什么,首先把对方说的话在一行中原样打印出来;
消除原文中多余空格:把相邻单词间的多个空格换成 1 个空格,把行首尾的空格全部删掉,把标点符号前面的空格删掉;
把原文中所有大写英文字母变成小写,除了 I;
把原文中所有独立的 can you、could you 对应地换成 I can、I could—— 这里“独立”是指被空格或标点符号分隔开的单词;
把原文中所有独立的 I 和 me 换成 you;
把原文中所有的问号 ? 换成惊叹号 !;
在一行中输出替换后的句子作为 AI 的回答。
输入格式:
输入首先在第一行给出不超过 10 的正整数 N,随后 N 行,每行给出一句不超过 1000 个字符的、以回车结尾的用户的对话,对话为非空字符串,仅包括字母、数字、空格、可见的半角标点符号。
输出格式:
按题面要求输出,每个 AI 的回答前要加上 AI: 和一个空格。
输入样例:
6
Hello ?
Good to chat with you
can you speak Chinese?
Really?
Could you show me 5
What Is this prime? I,don 't know
输出样例:
Hello ?
AI: hello!
Good to chat with you
AI: good to chat with you
can you speak Chinese?
AI: I can speak chinese!
Really?
AI: really!
Could you show me 5
AI: I could show you 5
What Is this prime? I,don 't know
AI: what Is this prime! you,don't know
现在是凌晨1点28分,我开始写这个博客,这道题我打算尽可能详细的写一下。因为这道题,让我废了不少功夫,坑多,有很多细节。下面我也会列出一些测试点错误和坑的分析。废话不多说进入正题。
这道题乍一看挺简单,就是根据要求替换字符串即可。但是一提交总有一个两个测试点不通过。接下来我们逐一分析。
无论用户说什么,首先把对方说的话在一行中原样打印出来;
第一个要求不难,输入啥输出啥即可。
消除原文中多余空格:把相邻单词间的多个空格换成 1 个空格,把行首尾的空格全部删掉,把标点符号前面的空格删掉;
这个要求是消除原文中的空格。要求也是看着简单明了。删除行首行尾的空格这个应该不难理解。
注意!!!(为了方便查看本文章用#代替空格)
####abc#d,#ef####
###abcabc#d
sbdd,#####
#,dav##tt
abc,#d#
不管是前面空格有几个一个还是多个全部清除
abc#d,#ef
测试点1 貌似就是测试这个前后空格消除情况的。
测试点样例测试,如果测试点1不能通过可以测试一下面的数据:
1
#####abcd#####,####123478#####?#####
正确输出:
#####abcd#####,####123478#####?#####
AI:#abcd,#123478!
PS:AI:#这个的空格(#)不是字符串前面的那个是题目要求输出格式AI:加个空格。也就是AI:#,所以正确输出时字符串首尾是不存在空格的
这个比较简单不多赘述了。继续往后看。把相邻单词间的多个空格换成 1 个空格和把标点符号前面的空格删掉。这两个要求拿到一起分析。因为标点和单词可以结合的。单词中间多余的空格删除,这个不难理解。
apple#
##can####I
这里标红不是指必须删除那几个空格。标红是笔者随机标的。你删除哪个空格都可以只要再在单词间留下一个空格就行。
apple#can#I
!!!注意:这里指的单词可不是我们理解的那个英文单词。这里说的单词就是数字和字母单独或者混合的组合,中间没有空格和标点符合的话就是属于单词。
例如:
aaa
a123
2345
56kda345
以上都属于此题中的单词。
单词加上标点符合就开始有猫腻了。标点符号前面的空格可以删后面的不能删。
例如:
12
#,##abc
dbc##,#aa#,
上面特殊标记的空格都得删。
12,#abc
dbc,#aa,
下面看见几个特殊情况,也是这个题的诸多坑之一。
#,abc,#
虽然最后一个空格是标点符号后面的空格,但是这个空格属于尾部空格,上面要求了得删除首尾空格。这个必须得删。
,abc,
在看一个特殊例子。
aab,
####,###abc
标记的空格都得删,虽然对第一个逗号来说那个空格在它后面但是对于第二个逗号来说空格全在它前面,所以都得删。
aab,#abc
再来一个特例。开局直接标点符号。测试点4的测试数据就是这种。
,abc
,#abc
这两个样例没有需要删除的空格。输出和原样一样.
测试点4样例测试,如果测试点无法通过尤其是测试点4运行超时的可以测试下面的样例。
测试1
1
,dac
正确输出
,dec
AI: ,dec
测试2
#,dab
正确输出
#,dab
AI: ,dab
单词和标点符号差不多了,我们继续往下看。
把原文中所有大写英文字母变成小写,除了
I;
把原文中所有独立的can you、could you对应地换成I can、I could—— 这里“独立”是指被空格或标点符号分隔开的单词;
把原文中所有独立的I和me换成you;
这里就坑多了。首先我们得了解什么是独立的词。根据题目描述,被空格和标点符号隔开的单词就是独立的。
例如:
I
can you###Abc###could you
###abc##bc,##ab
I##can you,ibc
abds,==b==##,could you
could you,BC,bnm
me#Dc,nn
上面红色的空格都是需要被删除的空格,黄色的是属于独立的单词或者词组。can you 和could you虽然中间有一个空格但是题目要求把他整体看所以他整体看成一个单词或者不可分割的词组。
把原文中所有大写英文字母变成小写,除了
I;
现在题目要求是把除了I以外的字母都转换成小写。这个并不难。但要注意一点那就是I是大写不是小写。接下来要有大坑了。
把原文中所有独立的
can you、could you对应地换成I can、I could
把原文中所有独立的I和me换成you;
这两句话有一个大坑。我举个例子就清楚了。
我们首先看几个例子,这个是测试点2出错的朋友可以试试
测试1
1
could#youI
正确输出
could#youI
AI: could#youI
测试2
1
could#youI#Ican#you#Ime#MEI#Icound#meyou
正确输出
could#youI#Ican#you#Ime#MEI#Icound#meyou
AI:#could#youI#Ican#you#Ime#meI#Icound#meyou
其实我感觉如果独立的单词词组那个条件把握好了的话上面这几个样例其实都不会出错的。就是考验判断是否是独立单词独立词组那个,那个是需要严谨的,如果没问题上面这几个一般也没事。
接下来才是大坑所在,也是举例说明。
测试点1不能通过的可以试试下面几个测试数据。
1
can#me
正确输出
can#me
AI: can#you
错误输出
can#me
AI: I#can
我们分析一下错误输出怎么来的。
首先原文是can me然后根据要求me 被替换成了you ,can me变成了can you,之后can you被按照要求替换成了I can.这个题目里两次这种变化不允许的。只能在原文的基础上进行修改,不能修改已经修改过的字词。再看一个例子。
1
can#you
正确输出
can#you
AI: I#can
错误输出
can#you
AI: you#can
我们继续分析一下错误输出。原文是can you 被替换为I can.随后I can又被替换为you can。又是被重复替换了这是不可以的。所以一定要避免这个坑。
再列举一个比较特殊的例子。测试点4不通过的也可以试试这个测试数据
1
}7`@ir%>kaV&I2X
正确输出
}7`@ir%>kav&I2x
AI: }7`@ir%>kav&I2x
错误输出
}7`@ir%>kaV&you2X
AI: }7`@ir%>kaV&you2X
这个样例里面有个I,这个I前面是符号但是后面是数字,我们上边说过,字母和数字紧贴着的组合在本题中是被当作一个单词看待,所以不满足独立单词的条件。里面的I不是一个独立单词不能替换。
接着我们看看下一个要求。
把原文中所有的问号
?换成惊叹号!;
这个就简单了。找到所有的问号进行替换即可。记住是所有的问号都需要替换,一个都不能漏
在一行中输出替换后的句子作为 AI 的回答。
最后一个就是简单的输出格式了,把加工好的句子加上前缀AI:#(空格)根据要求输出即可。
现在是凌晨3点47分不知不觉写了两个小时了,比较累,内容还有一些,剩下的内容明天补吧。
翌日下午14点20分续写文章
上面题目要求分析完毕了。接下来说一下这道题上碰见问题后如何进行测试点判断的。就是找出那些特殊的测试用例的办法。首先当然是自己根据题目要求造特殊测试用例。不过有时候有些特殊用例,特殊情况我们不一定能立马想到。那么就去查资料,但是不一定所有问题都能找到资料。那怎么办?我们可以想想,既然特殊情况我们人工想不到那么随机生成一堆测试数据,海量数据测试也许就能随机出那种特殊数据了。但是海量测试数据我们人工生成显然是不可能的。几千个上万个输入我们人工实现,效率不高而且也没啥用。这种枯燥乏味的工作计算机做是最佳选择。那我们动手写一个随机生成测试数据的程序。
首先既然是处理字符串我们需要一个随机生成字符串的函数
string rand_str(const int len) /*参数为字符串的长度*/
{
/*初始化*/
string str; /*声明用来保存随机字符串的str*/
char c; /*声明字符c,用来保存随机生成的字符*/
int idx; /*用来循环的变量*/
/*循环向字符串中添加随机生成的字符*/
for (idx = 0; idx < len; idx++)
{
/*rand()%95是取余,余数为0~94加上32,就是我们要的字符,详见asc码表*/
c = 33 + abs(rand() % 95);
str.push_back(c); /*push_back()是string类尾插函数。这里插入随机字符c*/
}
return str; /*返回生成的随机字符串*/
}
把我们的代码进行调整和适配工作,给代码增加自动生成测试数据并自动进行测试的功能。也就是给代码加一个壳,这个壳能自动生成测试数据并运行代码进行测试。
自动生成测试数据并自动测试的代码
#if 1 //测试数据自动生成并验证
#include 到了这里我们已经得到了一个可以自动生成测试数据并能进行自动测试的代码了我们只要运行代码写入某个数字例如100,代码就会模拟一百次测试用随机数据测试一百次代码。但是不难看出好像没什么用,自动生成的测试数据的数据量非常庞大,这个确实是我们想要的效果。但是测试是可以测试了也能用庞大的测试数据进行,大量测试了。可是程序输出结果是不是正确的,如果不正确的话用哪些些测试数据的时候不正确。这些是对我们来说异常重要的信息。但是目前的测试程序无法给我们提供这些信息。那该怎么办呢?
解决这个问题我们首先可以想办法把程序输出结果保存到某个文件中。然后再和一个拥有标准输出的文件内容做对比,看看那里有问题。这就好比,我们做考试卷把答案写在答题卡上,写完答案拿出标准答案核对一样,一个道理。说到标准答案了那我们又会想到一个问题,哪里找标准答案呢?貌似我们没有标准答案。题目测试数据拿到那个也太难了。既然拿不到标准答案那我们完全可以自己做标准答案。网上找个或者自己用土方法,甚至是枚举方法写一个程序。这个程序有什么作用呢?这个程序可以调用能够AC代码进行随机数据测试并把测试记录保存下来。什么意思呢?就是说你可以找一个能AC的代码然后用一个程序自动生成测试数据,并自动调用AC代码进行输入输出的测试并把测试结果也就是输入的测试数据和输出的运行结果都保存起来。这样的话我们就得到了一个自己做的标准答案。至于那些特殊例子或者样例如果随机生成测试数据是海量数据的话也是也有可能生成出类似的特殊例子的。
自动生成测试数据并测试还能把测试数据和结果进行记录
#include细心的朋友已经发现了某些细节。是的,随机生成字符串的函数改了改成这样的。
//新版随机字符串生成函数
string rand_str(const int len) /*参数为字符串的长度*/
{
/*初始化*/
string str = ""; /*声明用来保存随机字符串的str*/
string word_str[99] = { "I", "me", "can you", "could you" };
for (int i = 4; i < 99; i++)
word_str[i] = 28 + i;
// char c; /*声明字符c,用来保存随机生成的字符*/
int idx; /*用来循环的变量*/
/*循环向字符串中添加随机生成的字符*/
for (idx = 0; idx < len; idx++)
{
/*rand()%95是取余,余数为0~94加上32,就是我们要的字符,详见asc码表*/
//c = word_str[rand() % 94];
//str.push_back(c); /*push_back()是string类尾插函数。这里插入随机字符c*/
str += word_str[rand() % 99];
}
return str; /*返回生成的随机字符串*/
}
随机抽取的字符串是从一个字符串数组里面了。这样我们能更加自由的自定义随机字符串的内容。比如本题的"me""I can"这种字符串随机生的时候生成出来难度还是挺大的。我们有了上面的改进,能更容易生成出我们需要的字符串格式了。好了,继续我们的研究。
现在我们拥有了记录随机生成的海量测试数据与标准输出结果的文件。现在我们把我们的代码简单改装一下让我们的代码能调用我们生成的输入文件里的内容,还能把输出结果写入文件保存。这样我们就更容易找出我们的错误了。
实现上面功能的代码如下:
#if 1
#include 好的我们已经可以拿到根据输入我们程序输出的结果文件了。

但是我们又面临了一个新问题那就是数据量太大了。我们打开文件可以看一下。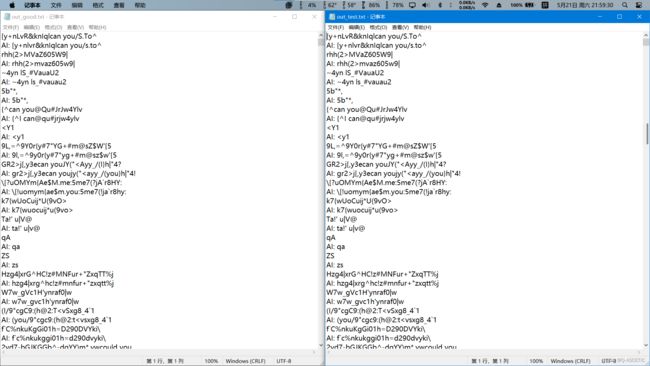
这密密麻麻的字符串我人工核对找出不同。这就会是一个巨大的挑战。一般来说这种无聊枯燥又需要细腻的工作一般是计算机做对不对?那要让计算机如何帮我们完成这个找不通任务呢?
用cmd有一个命令叫做FC它可以帮你核对两个txt文件给你列出不同的地方。
如图:
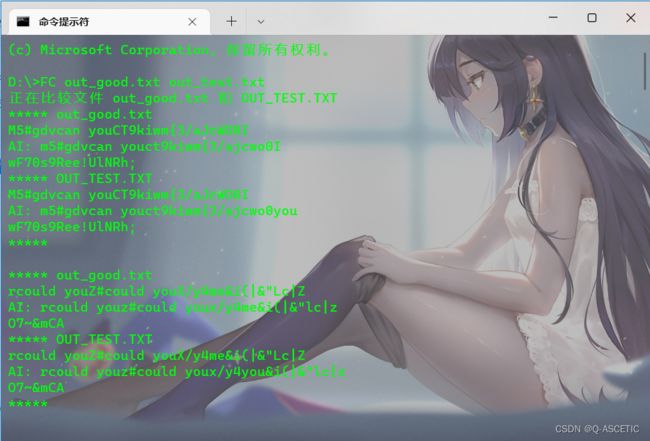
那么我们现在就可以根据这些和标准答案不同的输出找到这些特殊的测试用例进行测试来完善我们的程序了,这样就能慢慢攻破我们打不败的测试点了。祝大家好运!
PS:细心阅读我代码的朋友可能发现了这道题的测试数据不是那么的严谨有漏洞,一些错误代码也能通过。上面代码里有些代码重构的时候我不小心逻辑写错了但是还能通过。相关的漏洞代码如下。
//有漏洞!!!
//代码重构
if (isFlag && !isalpha(oldStr[i + subStr.size()]) && !isdigit(oldStr[i + subStr.size()]))
{
bool needFlag = false;
if (i >= 0)
{
needFlag = true;
if (i != 0)
//此处if条件是isalpha(oldStr[i - 1]) || isdigit(oldStr[i - 1]) 才对
if (isalpha(oldStr[i - 1]) && !isdigit(oldStr[i - 1]))
needFlag = false;
}
if (needFlag)
{
oldStr.replace(i, subStr.size(), newStr);
i = i + newStr.size();
}
}
相关漏洞测试数据,有这个漏洞的代码下面的测试数据是无法通过的。
测试1
1
M5#gdvcan youCT9kiwm{3/aJcWO0I
错误输出:
M5#gdvcan youCT9kiwm{3/aJcWO0I
AI: m5#gdvcan youct9kiwm{3/ajcwo0you
正确输出
M5#gdvcan youCT9kiwm{3/aJcWO0I
AI: m5#gdvcan youct9kiwm{3/ajcwo0I
测试2
1
rcould youZ#could youX/y4me&i(|&"Lc|Z
错误输出
rcould youZ#could youX/y4me&i(|&"Lc|Z
AI: rcould youz#could youx/y4you&i(|&"lc|z
正确输出
rcould youZ#could youX/y4me&i(|&"Lc|Z
AI: rcould youz#could youx/y4me&i(|&"lc|z
测试3
1
s"&zd3Q`$[Fcan youxme$.Xk.Q;'xSI8can you
错误输出
s"&zd3Q`$[Fcan youxme$.Xk.Q;'xSI8can you
AI: s"&zd3q`$[fcan youxme$.xk.q;'xsI8I can
正确输出
s"&zd3Q`$[Fcan youxme$.Xk.Q;'xSI8can you
AI: s"&zd3q`$[fcan youxme$.xk.q;'xsI8can you
好了,这篇文章差不多也改落幕了。感谢阅读,创作不易,这篇文章如果对你起到有帮助的话顺手点个赞吧,谢谢。你的支持就是我的动力呀。