《On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima》-ICLR2017文章阅读
这是一篇发表在ICLR2017上面的文章。
这篇文章探究了深度学习中一个普遍存在的问题——使用大的batchsize训练网络会导致网络的泛化性能下降(文中称之为Generalization Gap)。文中给出了Generalization Gap现象的解释:大的batchsize训练使得目标函数倾向于收敛到sharp minima(类似于local minima),sharp minima导致了网络的泛化性能下降,同时文中给出了直观的数据支持。而小的batchsize则倾向于收敛到一个flat minima,这个现象支持了大家普遍认为的一个观点:小的batchsize存在固有噪声,这些噪声影响了梯度的变化。文中还给出了一些方法去尝试消除Generalization Gap现象。
论文地址:https://openreview.net/pdf?id=H1oyRlYgg
1:背景介绍
一般的深度学习算法都是通过优化一个目标函数来训练网络参数的,这是一个非凸的优化问题。整个过程可以表达为下面的式子:
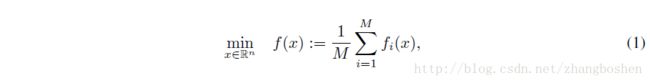
f(x)是损失函数。SGD是一种常见的优化方法:
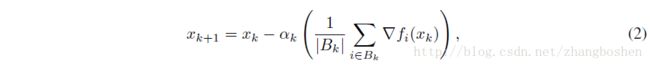
Bk是batchsize的大小,一般取值{32,64,…,512},经过实践的检验,这些常见的batchsize大小设置可以有以下的优点:
1:收敛到凸函数的最小值点以及非凸函数的驻点;
2:避免鞍点的出现;
3:对输入数据具有鲁棒性。
SGD的主要缺点——并行化困难,一个常见方法是增大batchsize,然而这导致了Generalization Gap的出现。
作者观察到Generalization Gap的出现是和大batchsize训练时候的最优值的锐度(sharpness)相关的,后面的工作为这个现象提供实验支持,并且尝试解决Generalization Gap这个问题。
2:大Batch方法的缺点
首先,大Batch方法与小Batch方法在训练的时候实际上得到的目标函数的值是差不多的,这个现象的可能原因有下面几点(LB=Large-Batch;SB=Small-Batch):
1:LB方法过度拟合模型;
2:LB方法被吸引到鞍点;
3:LB方法缺乏SB方法的探索性质,并倾向于放大最接近初始点的最小值;
4:SB和LB方法收敛到具有不同泛化特性的定性不同的最小化。
文章主要研究上面的3、4两点可能原因。
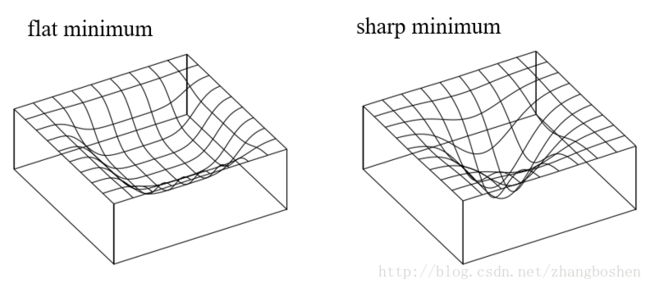
作者认为大Batch方法之所以出现Generalization Gap问题,原因是大Batch方法训练时候更容易收敛到sharp minima,而小Batch的方法则更容易收敛到flat minima。并且大Batch方法不容易从这些sharp minima的basins中出来。下图给出了sharp minima和flat minima的一个示意图。
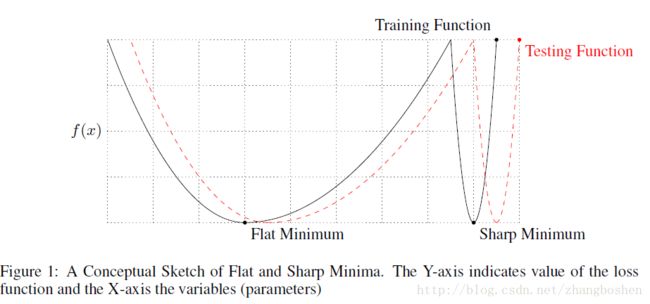
sharp minima的存在是导致Generalization Gap出现的最重要原因,如下图所示:
下面作者进行了一系列可视化的数据实验来验证上面的观点:首先,Table1是作者选用的几种网络结构以及数据集。其中C1和C3是Alex-Net结构,C2和C4是Google-Net结构。
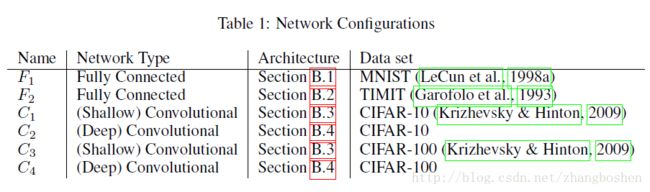
实验用到的数据库:
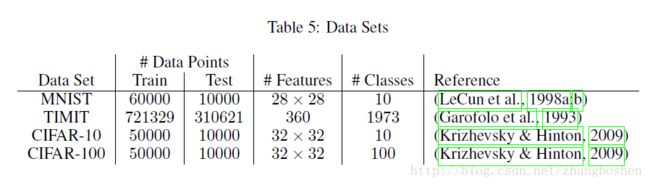
其中,TIMIT是一个语音识别的数据库。
考虑到文章的目的是探索LB和SB方法的最小值的性质,而不是追求state-of-art或者是时间消耗,最终的实验结果是用最后的testing accuracy来表示的。
实验中LB方法的Batchsize定义为整个数据集的10%,SB方法的Batchsize定义为256。优化器使用ADAM(ADAGRAD、adaQN等几个方法得到的结论是类似的)。损失函数使用的是交叉熵形式。
对应Table1中6个网络的实验的结果如table2所示。可以看到,SB和LB两种算法在Training阶段取得的结果非常相近,而Testing阶段LB方法明显出现了Generalization Gap的现象。
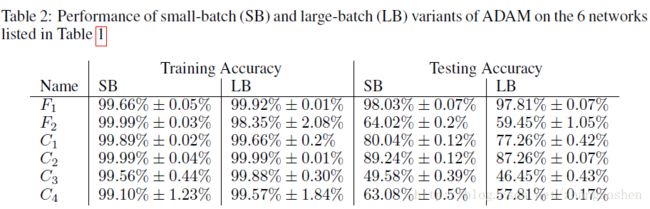
这里再一次强调,LB方法出现的Generalization Gap现象并不是过拟合造成的,这可以由figure2的图看出,这个F2和C1网络的训练-测试曲线,提前停止训练(防止过拟合)的方法对这个实验并没有帮助。
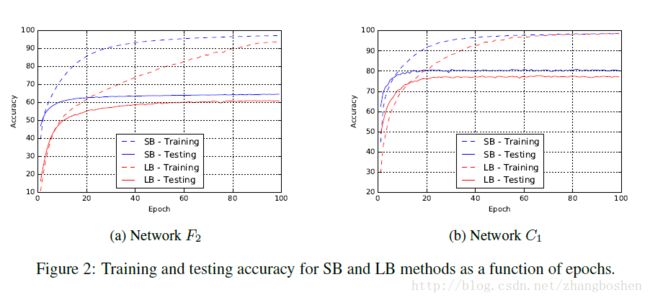
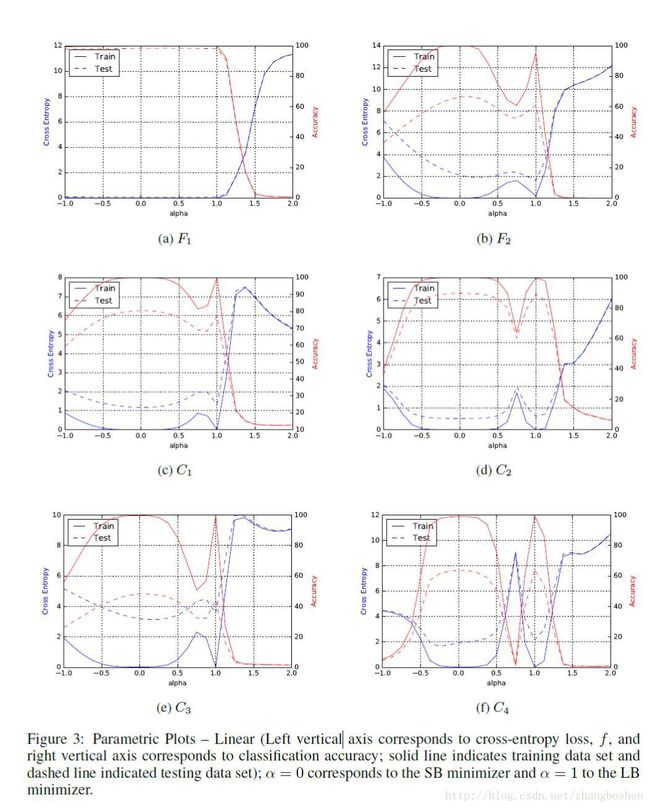
Figure3给出的是一维的参数曲线,Xs和Xl分别表示SB和LB方法在ADAM优化器中得到的预测结果,其中 α 在-1到2之间:
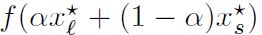
α =0对应SB方法的最小值,alpha=1对应LB方法的最小值。可以看到LB方法的最优值明显比SB方法的最优值锋利(sharpness)得多:
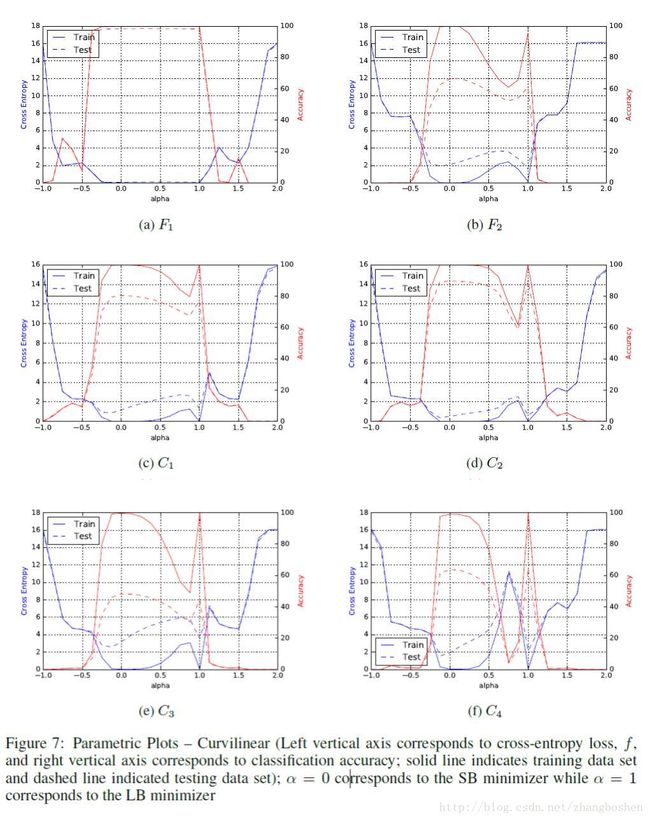
上面figure3给出的只是目标函数的一个现行切分,figure7则给出了一个非线性切分的结果图:
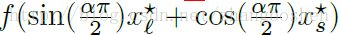
可以观察到此时的LB与SB方法的锐度(sharpness)区别更为明显。
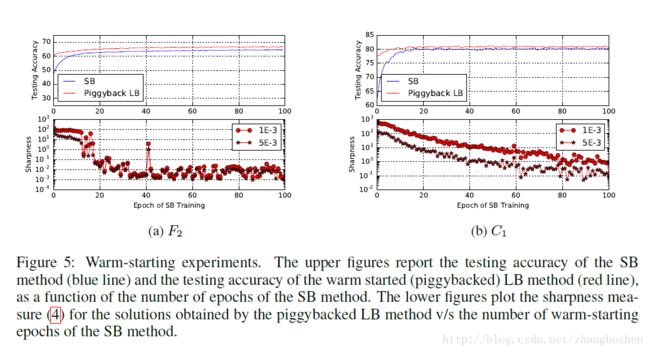
上面所做的工作对于sharpness的应用和解释都是比较松弛的,事实上,sharpness的定义可以由目标函数的Hessian矩阵计算,但是神经网路的Hessian矩阵计算非常困难。下面作者介绍了一个锋利度sharpness的数学定义,虽然不完美,但是计算开销上是具有可行性的,这个定义只在最优值的一个邻域内计算,但是考虑到最优值可能在多个方向上得到,作者给出了两种方案:一是在整个空间上面Rn进行优化过程,二是在一个随机大小的子空间上面进行优化。这里作者给出了一个矩阵A(n*p)的概念,A是一个在全空间随机抽样产生的矩阵,列数p就是随机产生的子空间维数,文中设置为p=100。
(3)式是一个范围限定集,(4)式就是本文中对于锋利度sharpness的数学定义。

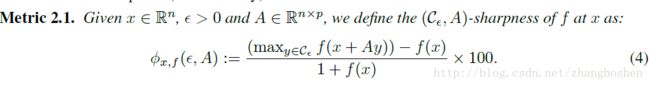
Table3、4是文中对于六个网络结构的优化过程中的锋利度sharpness的计算结果。其中table3表示了整个空间上的最小值锋利度,而table4则是子空间(100维)。
作者还指出,sharp minima并不出现在所有方向上,根据作者的实验观察,只有5%的子空间上会出现,在其他方向上,minima相对比较flat。
3:小Batch方法的优点
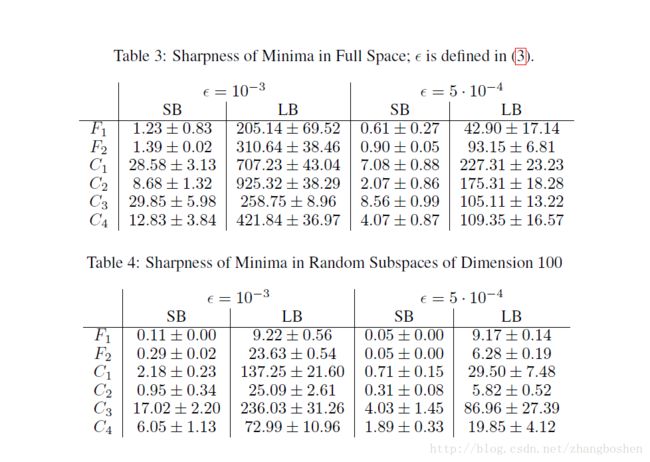
事实上关于batchsize的选择是存在一个阈值的,batchsize大于这个阈值会导致模型质量的退化。这个现象可以由figure4看出来,figure4中的F2的约15000和C1的约500,大于这个阈值网络准确度大幅下降。
现在思考一下SB方法的原理,它使用的梯度具有内在的噪声,从实验以及经验来看,这些噪声使得SB方法的minimum在到达一个相对sharp的区域时,能够将最优值推出去,到达一个相对flat的区域,而这些噪声不足以将一个本来就很flat的minimum推出去。而LB方法明显大于上面所说的阈值的时候,梯度内存在的噪声不足以将minimum推出sharp区域。
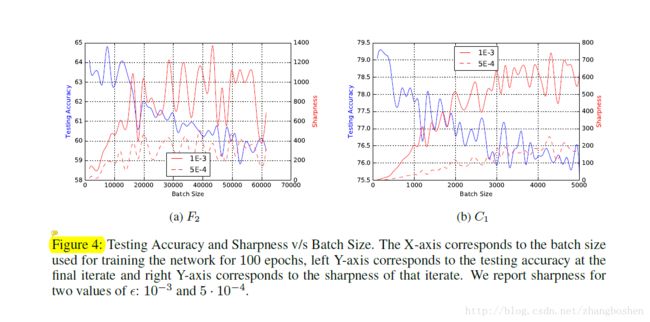
下面作者又做了这样一个实验:用256的小batch训练一个网络100个epoch,每一个epoch以后保留迭代的结果,将这100个结果作为LB大一个起始训练点,称之为piggybacked LB。
Figure5给出了实验的结果,起始几个epoch时候SB或者是piggybacked LB都还没有完成各自的优化过程,所以test accuracy都比较低,sharpness比较高。当到达一定数量的训练epoch时候,两个方法的sharpness都下降了,test accuracy都提高,这个时候说明SB已经完成了它的“探索”过程,找到了一个比较flat的minimum,并且引导piggybacked LB的LB也收敛到这个比较flat的minimum。
还有一点推测是LB方法倾向于被初始点X0附近的minima吸引,SB方法则会相对原理这些初始点附近的minima,作者的实验支持了这个猜想,他们观察到:小batch的最优值与起始点的距离是大batch的最优点与起始点距离的3到10倍。
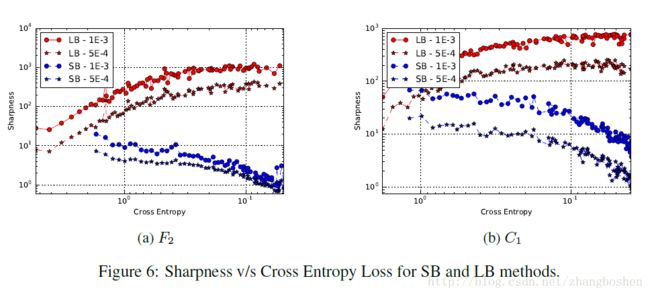
作者下面还给出了figure6这样一个sharpness随着loss变化的曲线,从中我们可以看出,当一开始loss比较大的时候,LB和SB方法的sharpness的差不多的,然而随着loss的减少(优化过程),LB的sharpness逐渐增加,SB的sharpness逐渐减少,最终到一个flat的minimum。
4:对大Batch方法尝试改进
这部分作者尝试对大batch方法泛化性能差的现象进行改进,和之前的实验设置一样,仍然选用10%的数据集大小作为LB方法,256的batchsize作为SB方法,优化器选用ADAM优化器。
4.1 数据增强
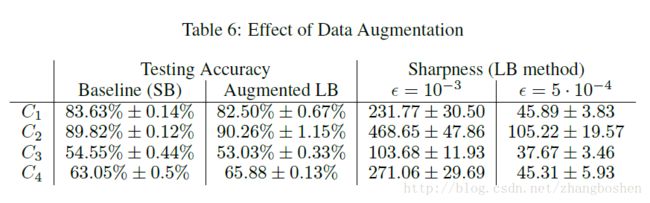
数据增强是一个针对数据库domain specific的过程,这部分实验作者训练了C1到C4四个image-based的CNN来说明问题。对于数据增强,作者使用的手段是水平映射(horizontal reflection)、随机旋转至10°、随机平移到图像尺寸的0.2倍。
table6所示是数据增强后的结果,可以看到数据增强的LB方法可以达到和SB方法(也在训练时候做过数据增强)差不多的预测精度,但是sharpness仍然较高,表明数据增强并没有改变LB方法存在的sharp minima的现象。
4.2 CONSERVATIVE TRAINING
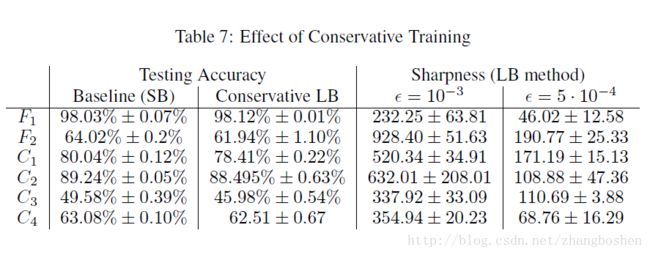
2014年文章【Mu Li, Tong Zhang, Yuqiang Chen, and Alexander J Smola. Efficient mini-batch training for stochastic optimization. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining】中作者曾今证明过优化下面一个式子可以使得SGD算法的LB方法的收敛率得到改善:
这个策略的动机是:为了更加充分地利用大batch方法中的每一个batch,每一个batch需要“不精确地”计算3-5次梯度的迭代,这个做法不仅提高了SGD的收敛率,并且在凸优化过程中取得了很好的经验效果,作者将这个想法用到了CNN优化这个非凸的问题上来。
Table7是CONSERVATIVE TRAINING的实际效果。同上面的数据增强方法一样,这个做法使得网络的泛化性能得到一定改善,但是sharpness仍然存在。
4.3 ROBUST TRAINING
所谓的ROBUST TRAINING,其实是通过优化一个最坏情况下的cost,而不是常规的cost。从数学角度来说,是通过优化下面的式子来实现的:
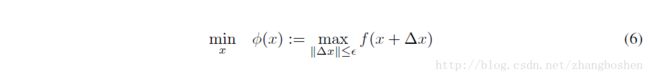
Figure8很直观的解释了ROBUST TRAINING的数学含义。
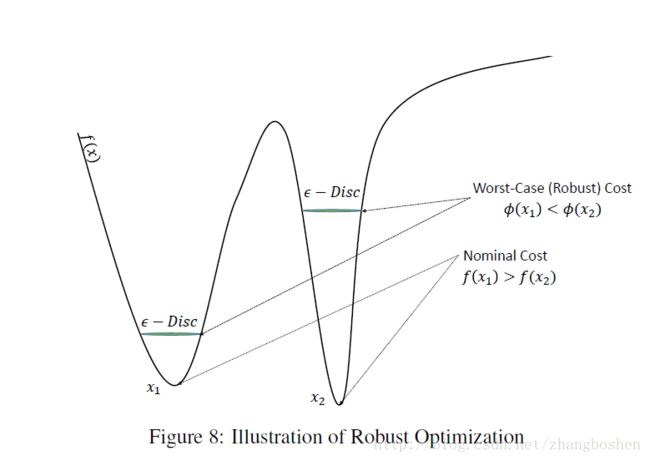
考虑到计算上面的式子在CNN的优化过程中并不现实(计算量),这涉及到一个large-scale second-order conic program(SOCP)问题(我也不知道这是个啥问题。。)。
在深度学习中,robustness的概念可以分为两个方面:即数据的robustness和优化过程的robustness。数据的robustness是吧CNN当成一个统计模型,而优化过程的robustness则是把CNN当成一个黑箱模型,而对于优化过程的robustness实际上就是对抗学习adversarial training。
对抗学习不同于数据增强对数据进行的那些常规操作,它是有目标的的增强对抗样本。但是很遗憾在本文作者的实验中,对抗学习的泛化性能以及sharpness和baseline非常接近。因此,这种方法也不能够解决sharp minima的现象。
5:结论与讨论
这篇文章中,作者给出了大batch优化过程中最优值倾向于收敛到sharp minima的数据实验支持,而sharp minima是导致网络泛化性能下降的重要原因(Generalization Gap)。作者通过提出一个锋利度sharpness的数学概念来表征sharp minima现象。同时,作者也给出了几种尝试去解决大batch方法的方案:数据增强、保守学习以及健壮学习,但是根据作者的实验,这几种方法虽然一定程度上提高了网络的泛化性能,但是sharp minima的现象依然存在。一个比较有希望的解决方案是dynamic sampling(动态采样),这个方法选取的batchsize随着迭代次数的增加会发生变化,这在文中的piggybacked LB实验中证明是可行的。
最近有很多学者也在研究一个loss surface的属性问题,他们的研究表明CNN在优化时确实存在很多个局部最优值,并且这些局部最优值的值大小非常接近。作者本文中发现sharp minimum和flat minimum的loss值其实也是非常接近的。
最后,文中也抛出了几个问题:
(a) 是否有人能够证明大batch的训练方法在神经网络的优化过程中严格收敛到sharp minima?
(b) 优化过程的sharp和flat两种minimum的密度如何?
(c) 是否有人能够设计出一种适合采用大的batch用来训练的CNN网络结构?
(d) 能够找到一种合适的初始化方法使得大batch的方法能够收敛到flat minimum上面去?
(e) 能够从一个算法的机制上面去找到一个算法,使得大batch方法远离sharp minima?