transformer原理及各领域应用分析
1.传统RNN网络的问题

(1)串行结构,并行运算程度低,难以拓展为深层网络
(2)基于词向量预测结果,无法考虑语境
(3)预测结果时,只能考虑到上文,无法考虑到下文
2.transformer整体架构

(1)self-attention
attention
动物需要在复杂环境下有效关注值得注意的点
心理学框架:人类根据随意线索和不随意线索选择注意点
一眼扫过去,你看到一个红色的杯子,这是随意线索,你想读书了,你看到一本书,这是不随意线索
卷积、全连接、池化层都只考虑不随意线索
注意力机制则显示的考虑随意线索,随意线索被称之为查询(query)。每个输入是一个值(value)和不随意线索(key)的对
而注意力分数是query和key的相似度,注意力权重是分数的softmax结果。这就好比与,我们找工作的预期薪资,我们看的是相同行业能力差不多的人的平均薪资,相当于我们给这些人一些较大的权重。
self-attention 是什么
对于每个词,我们可以考虑到上下文对每个词的影响,即我们可以算出上下文每个词对于这个词的关系。例如,下面这个例子,it到底指代什么呢?我们可以算出每个词与it之间的权重,那么,我们在考虑it指代什么的时候,就可以将“注意力”集中到这些权重较大的词上。

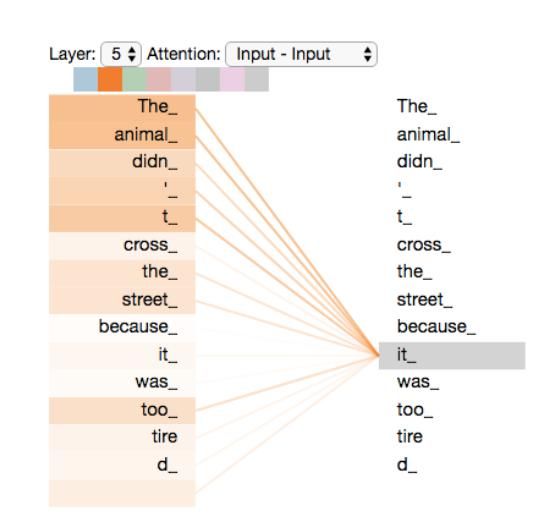
self-attention如何计算
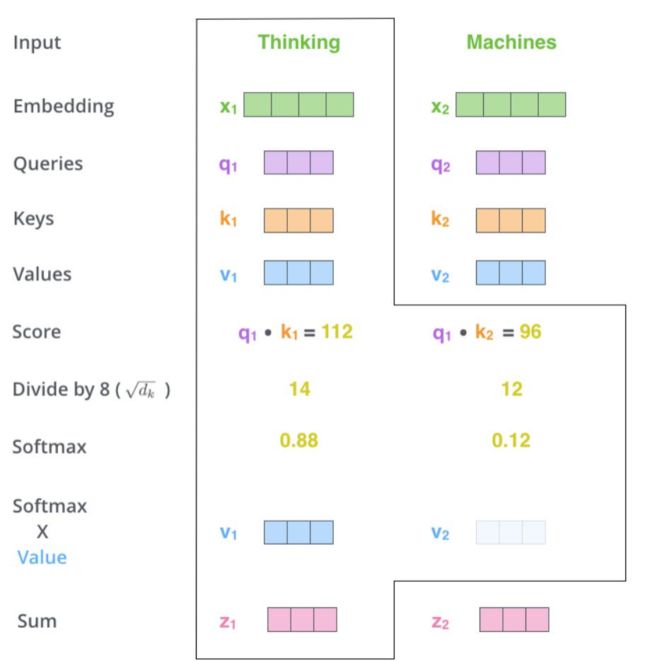
我们可以通过编码构建三个辅助向量:queries、keys、values,那么x1和x2间的关系可以用q1*k1来表示

如何得到queries、keys、values呢?
我们可以通过神经网络训练一组权重关系矩阵,通过x1,得到queries、keys、values,进而求取q和k间的关系。
类似于卷积,self-attention层相当于换了一种提取特征的方式,通过训练网络,不断地更新权重,得到queries、keys、values值,实现特征提取。
每个词的Attention计算
每个词的Q会跟整个序列中每一个K计算得分,然后基于得分再分配特征,例如:输入的q与向量k1,k2,k3,k4的相似度权重为w1,w2,w3,w4,那么,最终的特征矩阵z=w1v1+w2v2+w3v3+w4v4,其中values表示训练得到的各个词实际的特征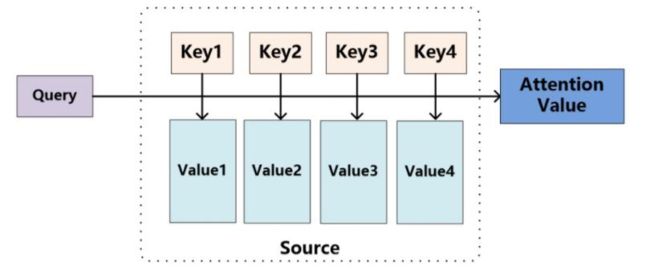
其中,考虑到一个细节,100维的q和k的点积结果肯定会大于10维的q和k的点积结果,因此,我们需要除以 消除量纲的影响
消除量纲的影响

(2)每个词的Attention计算
每个词的Q会跟每一个K计算得分 ,Softmax(对q1*k1,q2*k2分别做softmax)后就得到整个加权结果 ,此时每个词看的不只是它前面的序列,而是整个输入序列。

(3)multi-headed机制
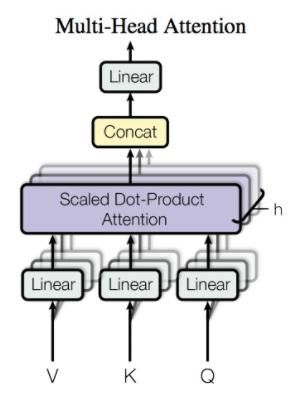
为了提取到更多的特征,采用多头注意力机制,类似于卷积,用多个不同的卷积核提取特征,多头注意力机制基于初始化不同的权重参数得到不同的q,k,v值实现


通过不同的head得到多个特征表达,将所有特征拼接在一起,再通过再一层全连接来降维,让输入输出维度相同

multi-headed机制

multi-headed结果
不同的注意力结果 ,得到的特征向量表达也不相同

(4)堆叠多层
类似于卷积,我们可以将self attention堆叠多层,以更好的提取特征
(5)位置信息表达
在self-attention中每个词都会考虑整个序列的加权,所以其出现位置 并不会对结果产生什么影响,但是这跟实际就有些不符合了,我们希望模型能对位置有额外的认识。因此我们引入了位置编码。位置编码开始是人为指定的,位置编码也是可以训练的,尤其是图像领域,图像领域不像自然语言处理有主谓宾,目标可以出现在图像的任何地方

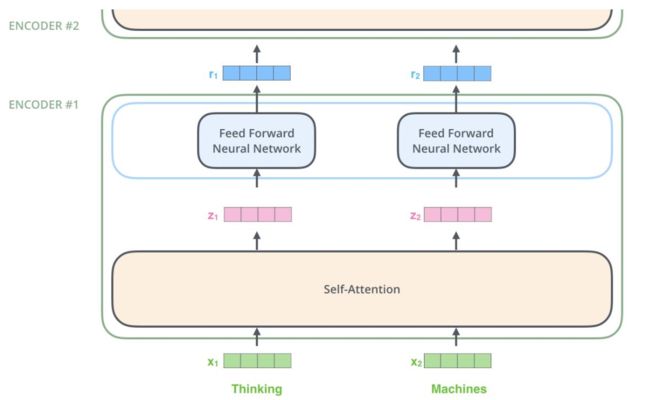
(6)encoder整体架构
对于输入序列x,首先经过self-Attention层提取特征,然后将结果堆叠起来,经过全连接后,继续输入下一个模块进行特征提取

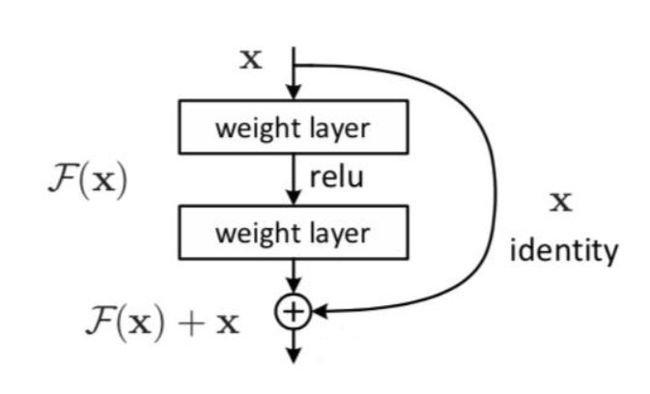
Add与Normalize
其中,也采用残差连接,并进行层归一化处理


Decoder
以机器翻译为例,对于第一个词,decoder以输入的词为q,encoder的结果为k,v,对于第二个词,既要考虑到encoder结果,又要考虑到上一个词的输出结果,即既要计算以encoder为k,v的Attention,又要计算self-attention。同时,对后面的序列采用mask机制,即屏蔽掉后面的序列。mask机制加与否,看具体的任务

最终输出结果
最后加上一层全连接,使用softmax激活函数,即可得到输出结果,损失函数 为cross-entropy

整体梳理
encoder部分对于输入序列x,经过self-attention提取特征,得到每个词,关于其他词的特征向量,将结果输入到解码器中,decoder部分,对输入序列的翻译序列,加入mask位置编码,除第一个词以外,一方面做以encoder的输出为k,v的attention,同时也做以自身序列为k,v的self-attention,最后输出最终结果

Transformer在视觉中的应用
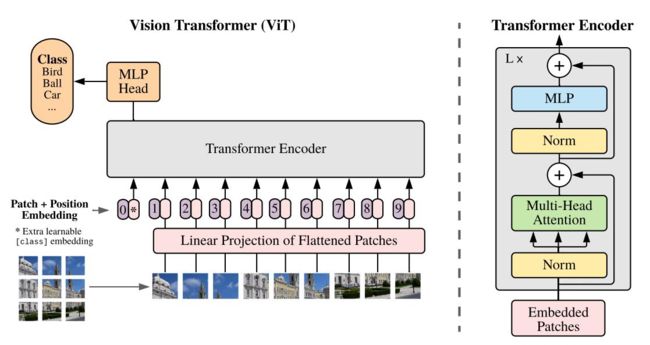
VIT整体架构分析
对于输入的图片,求取一张图片与所有图片的相似程度,最终以这些相似程度为权重,得到这张图片的向量化表达,即为提取的特征,最后将这些向量做分类,即得到图像分类的结果。
transformer与cnn的对比
CNN每一层获得的是局部信息,要想获得更大的感受野,则需要堆叠多层。而transformer根本不需要堆叠,直接就可以获得全局信息。
但是transformer的缺点是,transformer参数量大,训练配置要求高,同时,transformer需要获得各个类别对比其他类别的特征,比如说分类猫、狗、和熊猫,分类猫和狗,可能他的关注点在鼻子上,分类熊猫的关注点可能在尾巴上。