链路追踪jaeger
1. 什么是链路追踪
分布式链路追踪(Distributed Tracing),也叫 分布式链路跟踪,分布式跟踪,分布式追踪 等等。
本文使用分布式Trace来简称分布式链路追踪。
本篇文章只是从大致的角度来阐述什么是分布式Trace,以及一个分布式Trace系统具备哪些要点和特征。
场景
先从几个场景来看为什么需要分布式Trace
场景1
开发A编写了一段代码,代码依赖了很多的接口。一个调用下去没出结果,或者超时了,Debug之后发现是接口M挂了,然后找到这个接口M的负责人B,告知B接口挂了。B拉起自己的调用和Debug环境,按照之前传过来的调用方式重新Debug了一遍自己的接口,发现NND是自己依赖的接口N挂了,然后找到接口N负责人C。C同样Debug了自己的接口(此处省略一万个‘怎么可能呢,你调用参数不对吧’),最终发现是某个空判断错误,修复bug,转告给B说我们bug修复了,B再转告给A说,是C那个傻x弄挂了,现在Ok了,你试一下。
场景2
哪一天系统完成了开发,需要进行性能测试,发现哪些地方调用比较慢,影响了全局。A工程师拉起自己的系统,调用一遍,就汇报给老板,时间没啥问题。B工程师拉起自己的系统,调用了一遍,也没啥问题,同时将结果汇报了给老板。C工程师这时候发现自己的系统比较慢,debug发现原来是自己依赖的接口慢了,于是找到接口负责人。。balabala,和场景1一样,弄好了。老板一一把这些都记录下来,满满的一本子。哪天改了个需求,又重新来一遍,劳民伤财。
解决方案
这两种场景只是缩影,假设这时候有这样一种系统,
它记录了所有系统的调用和依赖,以及这些依赖之间的关系和性能。打个比方,一个网页访问了应用M,应用M又分别访问了A,B,C,D四个应用,如下面这样的结构
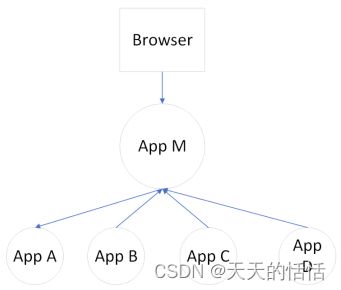
那么在这个系统中就能够看到,一个网页Request了一个应用M,花费了多少时间,请求的IP是多少,请求的网络开销是多少。应用M执行时间是多久,是否执行成功,访问A,B,C,D分别花了多少时间,是否成功,返回了什么内容,测试是否通过。 然后到下一步,A,B,C,D四个应用本次执行的时间是多久,有没有超时,调用了多少次DB,每次调用花费了多少时间。
作为示例,给出一个阿里鹰眼的trace图:
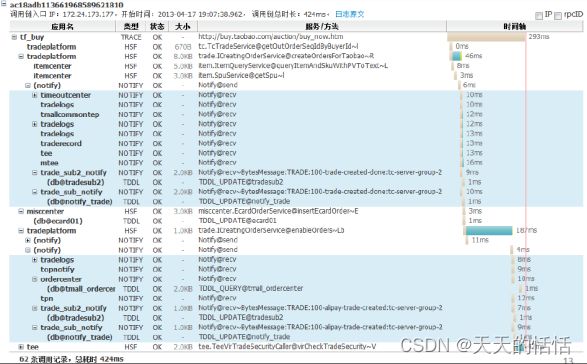
trace就犹如一张大的json表,同一层级的数据代表同一层级的应用,越往下代表是对下层某个应用的依赖。从图中可以很方便的看到每一个应用调用的名称,调用花费的时间,以及是否成功。
下面这张图是我们使用微软的application inlinght图
2. 链路追踪技术选型
GitHub - jaegertracing/jaeger: CNCF Jaeger, a Distributed Tracing Platform
| zipkin |
jaeger |
skywalking |
|
| OpenTracing兼容 |
是 |
是 |
是 |
| 客户端支持语言 |
java,c#,go,php,python等 |
java,c#,go,php,python等 |
Java, .NET Core, NodeJS ,PHP,python |
| 存储 |
ES,mysql,Cassandra,内存 |
ES,kafka,Cassandra,内存 |
ES,H2,mysql,TIDB,sharding sphere |
| 传输协议支持 |
http,MQ |
udp/http |
gRPC |
| ui丰富程度 |
低 |
中 |
中 |
| 实现方式-代码侵入性 |
拦截请求,侵入 |
拦截请求,侵入 |
字节码注入,无侵入 |
| 扩展性 |
高 |
高 |
中 |
| trace查询 |
支持 |
支持 |
支持 |
| 性能损失 |
中 |
中 |
低 |
3. jaeger安装和架构
安装
docker run \
--rm \
--name jaeger \
-p6831:6831/udp \
-p16686:16686 \
jaegertracing/all-in-one:latest架构
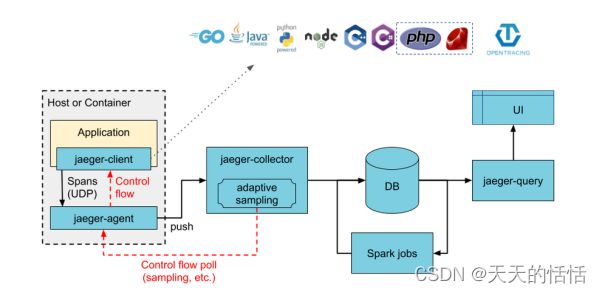
Jaeger组成
Jaeger Client - 为不同语言实现了符合 OpenTracing 标准的 SDK。应用程序通过 API 写入数据,client library 把 trace 信息按照应用程序指定的采样策略传递给 jaeger-agent。
Agent - 它是一个监听在 UDP 端口上接收 span 数据的网络守护进程,它会将数据批量发送给 collector。它被设计成一个基础组件,部署到所有的宿主机上。Agent 将 client library 和 collector 解耦,为 client library 屏蔽了路由和发现 collector 的细节。
Collector - 接收 jaeger-agent 发送来的数据,然后将数据写入后端存储。Collector 被设计成无状态的组件,因此您可以同时运行任意数量的 jaeger-collector。Data Store - 后端存储被设计成一个可插拔的组件,支持将数据写入 cassandra、elastic search。
Query - 接收查询请求,然后从后端存储系统中检索 trace 并通过 UI 进行展示。Query 是无状态的,您可以启动多个实例,把它们部署在 nginx 这样的负载均衡器后面。
分布式追踪系统发展很快,种类繁多,但核心步骤一般有三个:代码埋点,数据存储、查询展示
4. opentracing解析
OpenTracing语义标准
综述
这是正式的OpenTracing语义标准。OpenTracing是一个跨编程语言的标准,此文档会避免具有语言特性的概念。比如,我们在文档中使用"interface",因为所有的语言都包含"interface"这种概念。
版本命名策略
OpenTracing标准使用Major.Minor版本命名策略(即:大版本.小版本),但不包含.Patch版本(即:补丁版本)。如果标准做出不向前兼容的改变,则使用“主版本”号提升。如果是向前兼容的改进,则进行小版本号提升,例如加入新的标准tag, log和SpanContext引用类型。(如果你想知道更多关于制定此版本政策的原因,可参考specification#2)
OpenTracing数据模型
OpenTracing中的Trace(调用链)通过归属于此调用链的Span来隐性的定义。 特别说明,一条Trace(调用链)可以被认为是一个由多个Span组成的有向无环图(DAG图), Span与Span的关系被命名为References。
译者注: Span,可以被翻译为跨度,可以被理解为一次方法调用, 一个程序块的调用, 或者一次RPC/数据库访问.只要是一个具有完整时间周期的程序访问,都可以被认为是一个span.在此译本中,为了便于理解,Span和其他标准内声明的词汇,全部不做名词翻译。
例如:下面的示例Trace就是由8个Span组成:
单个Trace中,span间的因果关系
2.
3.
4. [Span A] ←←←(the root span)
5. |
6. +------+------+
7. | |
8. [Span B] [Span C] ←←←(Span C 是 Span A 的孩子节点, ChildOf)
9. | |
10. [Span D] +---+-------+
11. | |
12. [Span E] [Span F] >>> [Span G] >>> [Span H]
13. ↑
14. ↑
15. ↑
16. (Span G 在 Span F 后被调用, FollowsFrom)有些时候,使用下面这种,基于时间轴的时序图可以更好的展现Trace(调用链):
1.单个Trace中,span间的时间关系
2.
3.
4. ––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
5.
6. [Span A···················································]
7. [Span B··············································]
8. [Span D··········································]
9. [Span C········································]
10. [Span E·······] [Span F··] [Span G··] [Span H··]每个Span包含以下的状态:(译者注:由于这些状态会反映在OpenTracing API中,所以会保留部分英文说明)
- An operation name,操作名称
- A start timestamp,起始时间
- A finish timestamp,结束时间
- Span Tag,一组键值对构成的Span标签集合。键值对中,键必须为string,值可以是字符串,布尔,或者数字类型。
- Span Log,一组span的日志集合。 每次log操作包含一个键值对,以及一个时间戳。 键值对中,键必须为string,值可以是任意类型。 但是需要注意,不是所有的支持OpenTracing的Tracer,都需要支持所有的值类型。
- SpanContext,Span上下文对象 (下面会详细说明)
- References(Span间关系),相关的零个或者多个Span(Span间通过SpanContext建立这种关系)
每一个SpanContext包含以下状态:
- 任何一个OpenTracing的实现,都需要将当前调用链的状态(例如:trace和span的id),依赖一个独特的Span去跨进程边界传输
- Baggage Items,Trace的随行数据,是一个键值对集合,它存在于trace中,也需要跨进程边界传输
Span间关系
一个Span可以与一个或者多个SpanContexts存在因果关系。OpenTracing目前定义了两种关系:ChildOf(父子) 和 FollowsFrom(跟随)。这两种关系明确的给出了两个父子关系的Span的因果模型。 将来,OpenTracing可能提供非因果关系的span间关系。(例如:span被批量处理,span被阻塞在同一个队列中,等等)。
ChildOf 引用: 一个span可能是一个父级span的孩子,即"ChildOf"关系。在"ChildOf"引用关系下,父级span某种程度上取决于子span。下面这些情况会构成"ChildOf"关系:
- 一个RPC调用的服务端的span,和RPC服务客户端的span构成ChildOf关系
- 一个sql insert操作的span,和ORM的save方法的span构成ChildOf关系
- 很多span可以并行工作(或者分布式工作)都可能是一个父级的span的子项,他会合并所有子span的执行结果,并在指定期限内返回
下面都是合理的表述一个"ChildOf"关系的父子节点关系的时序图。
FollowsFrom 引用: 一些父级节点不以任何方式依赖他们子节点的执行结果,这种情况下,我们说这些子span和父span之间是"FollowsFrom"的因果关系。"FollowsFrom"关系可以被分为很多不同的子类型,未来版本的OpenTracing中将正式的区分这些类型
下面都是合理的表述一个"FollowFrom"关系的父子节点关系的时序图。
OpenTracing API
OpenTracing标准中有三个重要的相互关联的类型,分别是Tracer, Span 和 SpanContext。下面,我们分别描述每种类型的行为,一般来说,每个行为都会在各语言实现层面上,会演变成一个方法,而实际上由于方法重载,很可能演变成一系列相似的方法。
当我们讨论“可选”参数时,需要强调的是,不同的语言针对可选参数有不同理解,概念和实现方式 。例如,在Go中,我们习惯使用"functional Options",而在Java中,我们可能使用builder模式。
Tracer
Tracer接口用来创建Span,以及处理如何处理Inject(serialize) 和 Extract (deserialize),用于跨进程边界传递。它具有如下官方能力:
创建一个新Span
必填参数
- operation name, 操作名, 一个具有可读性的字符串,代表这个span所做的工作(例如:RPC方法名,方法名,或者一个大型计算中的某个阶段或子任务)。操作名应该是一个抽象、通用,明确、具有统计意义的名称。因此,"get_user" 作为操作名,比 "get_user/314159"更好。
例如,假设一个获取账户信息的span会有如下可能的名称:
| 操作名 |
指导意见 |
| get |
太抽象 |
| get_account/792 |
太明确 |
| get_account |
正确的操作名,关于 account_id=792 的信息应该使用 Tag 操作 |
可选参数
- 零个或者多个关联(references)的SpanContext,如果可能,同时快速指定关系类型,ChildOf 还是 FollowsFrom。
- 一个可选的显性传递的开始时间;如果忽略,当前时间被用作开始时间。
- 零个或者多个tag。
返回值,返回一个已经启动Span实例(已启动,但未结束。译者注:英语上started和finished理解容易混淆)
将SpanContext上下文Inject(注入)到carrier
必填参数
- **SpanContext**实例
- format(格式化)描述,一般会是一个字符串常量,但不做强制要求。通过此描述,通知Tracer实现,如何对SpanContext进行编码放入到carrier中。
- carrier,根据format确定。Tracer实现根据format声明的格式,将SpanContext序列化到carrier对象中。
将SpanContext上下文从carrier中Extract(提取)
必填参数
- format(格式化)描述,一般会是一个字符串常量,但不做强制要求。通过此描述,通知Tracer实现,如何从carrier中解码SpanContext。
- carrier,根据format确定。Tracer实现根据format声明的格式,从carrier中解码SpanContext。
返回值,返回一个SpanContext实例,可以使用这个SpanContext实例,通过Tracer创建新的Span。
注意,对于Inject(注入)和Extract(提取),format是必须的。
Inject(注入)和Extract(提取)依赖于可扩展的format参数。format参数规定了另一个参数"carrier"的类型,同时约束了"carrier"中SpanContext是如何编码的。所有的Tracer实现,都必须支持下面的format。
- Text Map: 基于字符串:字符串的map,对于key和value不约束字符集。
- HTTP Headers: 适合作为HTTP头信息的,基于字符串:字符串的map。(RFC 7230.在工程实践中,如何处理HTTP头具有多样性,强烈建议tracer的使用者谨慎使用HTTP头的键值空间和转义符)
- Binary: 一个简单的二进制大对象,记录SpanContext的信息。
Span
当Span结束后(span.finish()),除了通过Span获取SpanContext外,下列其他所有方法都不允许被调用。
除了通过Span获取SpanContext
不需要任何参数。
返回值,Span构建时传入的SpanContext。这个返回值在Span结束后(span.finish()),依然可以使用。
复写操作名(operation name)
必填参数
- 新的操作名operation name,覆盖构建Span时,传入的操作名。
结束Span
可选参数
- 一个明确的完成时间;如果省略此参数,使用当前时间作为完成时间。
为Span设置tag
必填参数
- tag key,必须是string类型
- tag value,类型为字符串,布尔或者数字
注意,OpenTracing标准包含**"standard tags,标准Tag"**,此文档中定义了Tag的标准含义。
Log结构化数据
必填参数
- 一个或者多个键值对,其中键必须是字符串类型,值可以是任意类型。某些OpenTracing实现,可能支持更多的log值类型。
可选参数
- 一个明确的时间戳。如果指定时间戳,那么它必须在span的开始和结束时间之内。
注意,OpenTracing标准包含**"standard log keys,标准log的键"**,此文档中定义了这些键的标准含义。
设置一个baggage(随行数据)元素
Baggage元素是一个键值对集合,将这些值设置给给定的Span,Span的SpanContext,以及所有和此Span有直接或者间接关系的本地Span。 也就是说,baggage元素随trace一起保持在带内传递。(译者注:带内传递,在这里指,随应用程序调用过程一起传递)
Baggage元素为OpenTracing的实现全栈集成,提供了强大的功能 (例如:任意的应用程序数据,可以在移动端创建它,显然的,它会一直传递了系统最底层的存储系统。由于它如此强大的功能,他也会产生巨大的开销,请小心使用此特性。
再次强调,请谨慎使用此特性。每一个键值都会被拷贝到每一个本地和远程的下级相关的span中,因此,总体上,他会有明显的网络和CPU开销。
必填参数
- baggage key, 字符串类型
- baggage value, 字符串类型
获取一个baggage元素
必填参数
- baggage key, 字符串类型
返回值,相应的baggage value,或者可以标识元素值不存在的返回值(译者注:如Null)。
SpanContext
相对于OpenTracing中其他的功能,SpanContext更多的是一个“概念”。也就是说,OpenTracing实现中,需要重点考虑,并提供一套自己的API。 OpenTracing的使用者仅仅需要,在创建span、向传输协议Inject(注入)和从传输协议中Extract(提取)时,使用SpanContext和references,
OpenTracing要求,SpanContext是不可变的,目的是防止由于Span的结束和相互关系,造成的复杂生命周期问题。
遍历所有的baggage元素
遍历模型依赖于语言,实现方式可能不一致。在语义上,要求调用者可以通过给定的SpanContext实例,高效的遍历所有的baggage元素
NoopTracer
所有的OpenTracing API实现,必须提供某种方式的NoopTracer实现。NoopTracer可以被用作控制或者测试时,进行无害的inject注入(等等)。例如,在 OpenTracing-Java实现中,NoopTracer在他自己的模块中。
可选 API 元素
有些语言的OpenTracing实现,为了在串行处理中,传递活跃的Span或SpanContext,提供了一些工具类。例如,opentracing-go中,通过context.Context机制,可以设置和获取活跃的Span。
5. grpc下添加jaeger
python
GitHub - grpc-ecosystem/grpc-opentracing: OpenTracing is a set of consistent, expressive, vendor-neutral APIs for distributed tracing and context propagation
测试
import requests
import logging
import time
from random import randint
from jaeger_client import Config
def download():
rsp = requests.get("https://www.xxx.com")
return rsp
def parser():
time.sleep(randint(1, 9) * 0.1)
def insert_to_mysql(parent_span):
#1. 生成sql的时间
with tracer.start_span('prepare', child_of=parent_span) as prepare_span:
time.sleep(randint(1, 9) * 0.1)
#2. 插入数据库的时间
with tracer.start_span('execute', child_of=parent_span) as execute_span:
time.sleep(randint(1, 9) * 0.1)
if __name__ == "__main__":
log_level = logging.DEBUG
logging.getLogger('').handlers = []
logging.basicConfig(format='%(asctime)s %(message)s', level=log_level)
config = Config(
config={ # usually read from some yaml config
'sampler': {
'type': 'const', #全部
'param': 1, #1 开启全部采样 0 表示关闭全部采样
},
'local_agent': {
'reporting_host':'192.168.0.104',
'reporting_port': '6831',
},
'logging': True,
},
service_name='mxshop',
validate=True,
)
# this call also sets opentracing.tracer
tracer = config.initialize_tracer()
with tracer.start_span("spider") as spider_span:
#下载
with tracer.start_span('get', child_of=spider_span) as get_span:
download()
#解析
with tracer.start_span('parser', child_of=spider_span) as parser_span:
parser()
# 入库
with tracer.start_span('insert', child_of=spider_span) as insert_span:
insert_to_mysql(insert_span)
time.sleep(2) # yield to IOLoop to flush the spans - https://github.com/jaegertracing/jaeger-client-python/issues/50
tracer.close() # flush any buffered spans服务中使用
client端
import grpc
import logging
import time
from random import randint
from jaeger_client import Config
from grpc_opentracing import open_tracing_client_interceptor
from grpc_opentracing.grpcext import intercept_channel
from grpc_hello.proto import helloworld_pb2, helloworld_pb2_grpc
#1. 这个问题能改吗?
#2. 其他语言有没有这个问题 其他语言 go语言 python 不服气
if __name__ == "__main__":
log_level = logging.DEBUG
logging.getLogger('').handlers = []
logging.basicConfig(format='%(asctime)s %(message)s', level=log_level)
config = Config(
config={ # usually read from some yaml config
'sampler': {
'type': 'const', # 全部
'param': 1, # 1 开启全部采样 0 表示关闭全部采样
},
'local_agent': {
'reporting_host': '192.168.0.104',
'reporting_port': '6831',
},
'logging': True,
},
service_name='mxshop-grpc',
validate=True,
)
tracer = config.initialize_tracer()
tracing_interceptor = open_tracing_client_interceptor(tracer)
with grpc.insecure_channel("localhost:50051") as channel:
tracing_channel = intercept_channel(channel, tracing_interceptor)
stub = helloworld_pb2_grpc.GreeterStub(tracing_channel)
hello_request = helloworld_pb2.HelloRequest()
hello_request.name = "bobby"
rsp: helloworld_pb2.HelloReply = stub.SayHello(hello_request)
print(rsp.message)
time.sleep(2) # yield to IOLoop to flush the spans - https://github.com/jaegertracing/jaeger-client-python/issues/50
tracer.close()server端
from concurrent import futures
import logging
import time
from random import randint
import grpc
from grpc_opentracing import open_tracing_server_interceptor
from jaeger_client import Config
from grpc_opentracing.grpcext import intercept_server
from grpc_hello.proto import helloworld_pb2
from grpc_hello.proto import helloworld_pb2_grpc
log_level = logging.DEBUG
logging.getLogger('').handlers = []
logging.basicConfig(format='%(asctime)s %(message)s', level=log_level)
config = Config(
config={ # usually read from some yaml config
'sampler': {
'type': 'const', # 全部
'param': 1, # 1 开启全部采样 0 表示关闭全部采样
},
'local_agent': {
'reporting_host': '192.168.0.104',
'reporting_port': '6831',
},
'logging': True,
},
service_name='helloworld-srv',
validate=True,
)
tracer = config.initialize_tracer()
class Greeter(helloworld_pb2_grpc.GreeterServicer):
def SayHello(self, request, context):
#如何在这里找到父的span
with tracer.start_span('execute', child_of=context.get_active_span()) as execute_span:
time.sleep(randint(1, 9) * 0.1)
return helloworld_pb2.HelloReply(message='Hello, %s!' % request.name)
def serve():
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))
tracing_interceptor = open_tracing_server_interceptor(tracer)
server = intercept_server(server, tracing_interceptor)
helloworld_pb2_grpc.add_GreeterServicer_to_server(Greeter(), server)
server.add_insecure_port('[::]:50051')
server.start()
server.wait_for_termination()
tracer.close()
if __name__ == '__main__':
logging.basicConfig()
serve()go
https://github.com/grpc-ecosystem/grpc-opentracing/tree/master/go interpreter拦截器
GitHub - jaegertracing/jaeger-client-go: This library is DEPRECATED! client驱动
gin中使用
package middlewares
import (
"fmt"
"mxshop-api/goods-web/global"
"github.com/gin-gonic/gin"
"github.com/opentracing/opentracing-go"
"github.com/uber/jaeger-client-go"
jaegercfg "github.com/uber/jaeger-client-go/config"
)
func Trace() gin.HandlerFunc{
return func(ctx *gin.Context){
cfg := jaegercfg.Configuration{
Sampler: &jaegercfg.SamplerConfig{
Type: jaeger.SamplerTypeConst,
Param: 1,
},
Reporter: &jaegercfg.ReporterConfig{
LogSpans: true,
LocalAgentHostPort: fmt.Sprintf("%s:%d", global.ServerConfig.JaegerInfo.Host, global.ServerConfig.JaegerInfo.Port),
},
ServiceName: global.ServerConfig.JaegerInfo.Name,
}
tracer, closer, err := cfg.NewTracer(jaegercfg.Logger(jaeger.StdLogger))
if err != nil {
panic(err)
}
opentracing.SetGlobalTracer(tracer)
defer closer.Close()
startSpan := tracer.StartSpan(ctx.Request.URL.Path)
defer startSpan.Finish()
ctx.Set("tracer", tracer)
ctx.Set("parentSpan", startSpan)
ctx.Next()
}
}