利用DBNet解决MTWI 2018 挑战赛二:网络图像的文本检测
一、下载DBNet.pytorch代码
1、直接到Github下载https://github.com/WenmuZhou/DBNet.pytorch
2、利用git环境下载
cd /path # 进入自己想要下载到本地的目标路径
git clone https://github.com/WenmuZhou/DBNet.pytorch.git # 进行下载
二、下载数据集
在官网下载训练集以及测试集,网址:https://tianchi.aliyun.com/competition/entrance/231685/information
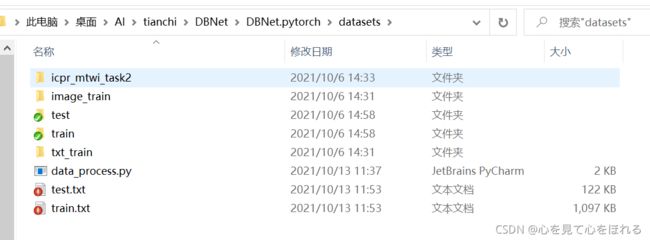
下载解压后将训练集和测试集文件拷贝至DBNet.pytorch/datasets文件夹中,得到下列文件
三、数据预处理
在本文中我们将利用基于ichar2015.yaml的icdar2015_resnet18_FPN_DBhead_polyLR.yaml模型,所以需要将数据处理成ICDAR2015格式,DBNet.pytorch/README.md文件中有说明数据格式。当然也可以使用open_dataset.yaml的模型,此时需要把数据处理成josn格式。
我们将原始训练集分为训练集和验证集,使用留出法划分为验证集:训练集 = 1:9。
处理脚本data_process.py:
import os
#import random
# 获取文件夹所有子文件
def get_file(path):
all_files = []
for home, dirs, files in os.walk(path):
for filename in files:
name = os.path.join(home, filename)
name = name.replace('\\', '/')
all_files.append(name)
return all_files
if __name__ == "__main__":
data_floder = 'image_train'
data_list = get_file(data_floder)
val_list = [data_list[i] for i in range(0, len(data_list), 10)]
train_list = [i for i in data_list if i not in val_list]
with open('train.txt', 'w') as f:
for train_file in train_list:
train_file = './datasets/' + train_file
f.write('%s\t%s\n'%(train_file, train_file[:-3].replace('image_train', 'txt_train')+'txt'))
f.close()
with open('test.txt', 'w') as f:
for val_file in val_list:
val_file = './datasets/' + val_file
f.write('%s\t%s\n'%(val_file, val_file[:-3].replace('image_train', 'txt_train')+'txt'))
f.close()
四、环境配置
pytorch>=1.4,现在大多应该都在用1.7及以上版本。
安装依赖库requirement.txt:
anyconfig
future
imgaug
matplotlib
numpy
opencv-python
Polygon3
pyclipper
PyYAML
scikit-image
Shapely
#tensorboard==2.1.0
tqdm
#torch==1.4
#torchvision==0.5
使用命令python -m pip install -r requirement.txt即可安装。
此时还需要额外安装部分其他库:addict、natsort等,具体看运行代码时的提示。
五、模型训练
修改config/icdar2015_resnet18_FPN_DBhead_polyLR.yaml配置文件
使用预训练模型pretrained: true,训练收敛会快一点,不使用的话对最终结果可能没有影响(在ICDAR2019票据文本数据上没影响,天池MTWI数据集还未验证过)
arch:
type: Model
backbone:
type: resnet18
pretrained: true
学习率设置。
optimizer:
type: Adam
args:
lr: 0.001 # batch size(所有GPU上的batch size总和)大的话调大点,小的话则调小点
weight_decay: 0 # L2正则化权重衰减参数,可以使用1e-4
amsgrad: true
lr_scheduler:
type: WarmupPolyLR # 权重衰减
args:
warmup_epoch: 3
训练迭代次数epoch改小点,源代码1200次太多了,训练时间太长。
trainer:
seed: 2
epochs: 120
log_iter: 10
show_images_iter: 50
resume_checkpoint: '' # 重新中断之前的训练,这里写上重新训练的文件名
finetune_checkpoint: '' # 微调已经训练好的模型
output_dir: output
tensorboard: false # tensorboard可视化,这个用不用无所谓,如果要检测损失值变化可以使用
加载数据集参数,按照需要修改。验证集最短边炸显存的话可以引入最长边,或者最短边调小点。
dataset:
train:
dataset:
args:
data_path:
- ./datasets/train.txt # 自己train.txt文件存放的位置
img_mode: RGB
loader:
batch_size: 8 # batch size大小,根据GPU显存以及GPU数量来设置,网络中使用的BN归一化,所以batch size不要过大或者过小
shuffle: true # 打乱数据集加载顺序,建议使用
pin_memory: true # 内存较大时使用,建议加上,DBNet进行了太多的数据增强变换操作,这样训练会快一点
num_workers: 8 # 加载数据的线程数,配置好的话调大点,可以加快训练速度
collate_fn: ''
validate:
dataset:
args:
data_path:
- ./datasets/test.txt
pre_processes:
- type: ResizeShortSize
args:
short_size: 736 # 最短边根据显存大小来缩放,这个配置的话16G显存的P100显卡都带不动,显存占用最大可以达到17G
resize_text_polys: false
img_mode: RGB
loader:
batch_size: 1 # 必须为1,否则显存带不动
shuffle: false
pin_memory: true
num_workers: 6
collate_fn: ICDARCollectFN
其他参数和论文中保持一致,建议不要调整。
模型训练,以ResNet18+FPN+DBNetHead为例
终端输入
单核训练时
CUDA_VISIBLE_DEVICES=0 python3 tools/train.py --config_file "config/icdar2015_resnet18_FPN_DBhead_polyLR.yaml" # 单GPU训练
多核训练时
export NGPUS=4 # 依据自己电脑配置修改GPU数量,下行中的CUDA_VISIBLE_DEVICES也要同步修改
CUDA_VISIBLE_DEVICES=0,1,2,3 python3 -m torch.distributed.launch --nproc_per_node=$NGPUS tools/train.py --config_file "config/icdar2015_resnet18_FPN_DBhead_polyLR.yaml" # 多GPU训练
注:不得将单核多核混合训练
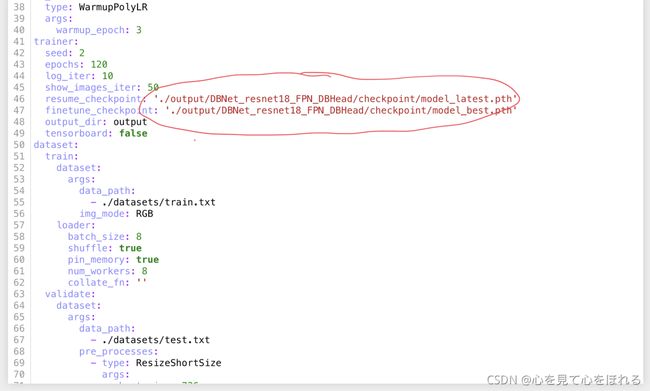
在已经训练好的模型基础上我们可以在config/icdar2015_resnet18_FPN_DBhead_polyLR.yaml中将finetune_checkpoint的值赋为已训练好的最优模型model_best.pth。
当出现因网络等各种原因导致模型训练终端的情况,我们可以将resume_checkpoint的值赋为最后训练出来的模型model_latest.pth,此时发生中断,再次训练时,将从该断点重新开始。
六、模型测试
利用eval.py对训练出来的模型进行测试看看效果
CUDA_VISIBLE_DEVICES=0 python3 tools/eval.py --model_path '(训练出来的模型的位置)'
七、结果输出
修改tools/predict.py文件,注释下面两行,不注释的话会输出具有标注框的图像
# 保存结果到路径
os.makedirs(args.output_folder, exist_ok=True)
img_path = pathlib.Path(img_path)
output_path = os.path.join(args.output_folder, img_path.stem + '_result.jpg')
pred_path = os.path.join(args.output_folder, img_path.stem + '_pred.jpg')
#cv2.imwrite(output_path, img[:, :, ::-1])
#cv2.imwrite(pred_path, preds * 255)
save_result(output_path.replace('_result.jpg', '.txt'), boxes_list, score_list, args.polygon)
注:源码tools/predict.py文件中的save_result拼写错误
修改util/util.py文件,只保存四个顶点坐标即可,不需要置信度
def save_result(result_path, box_list, score_list, is_output_polygon):
if is_output_polygon:
with open(result_path, 'wt') as res:
for i, box in enumerate(box_list):
box = box.reshape(-1).tolist()
result = ",".join([str(int(x)) for x in box])
score = score_list[i]
res.write(result + ',' + str(score) + "\n")
else:
with open(result_path, 'wt') as res:
for i, box in enumerate(box_list):
score = score_list[i]
box = box.reshape(-1).tolist()
result = ",".join([str(int(x)) for x in box])
#res.write(result + ',' + str(score) + "\n")
res.write(result + "\n") # 加上这一句
最后得到提交所需要的文件,如下图,一万个txt文件,压缩成zip文件即可提交。

选取合适的阈值
置信度阈值影响精确率和召回率,可以多次测试选取最优的置信度,个人测试得到置信度在0.5-0.7之间会有较好的效果。
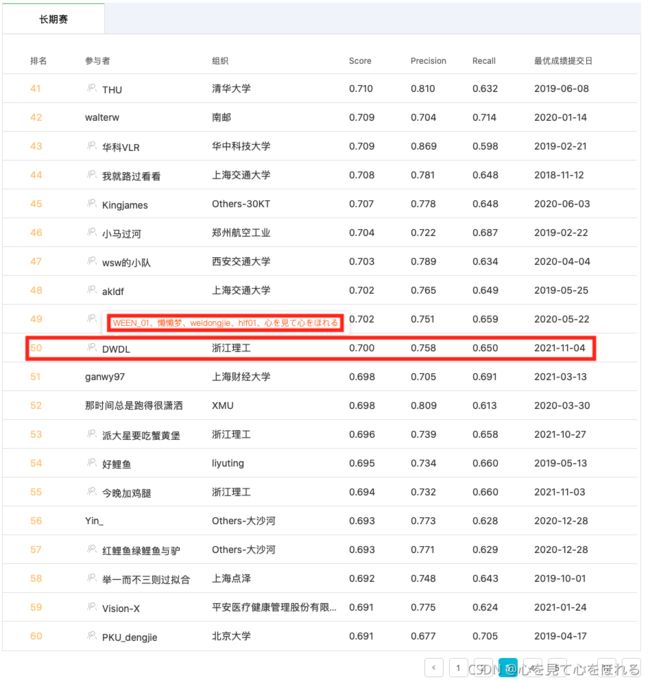
最优提交结果如下图所示