手写算法-python代码实现逻辑回归(带L1、L2正则项)
手写算法-python代码实现逻辑回归
- 逻辑回归原理解析
- 损失函数定义以及数学公式推导过程
-
- 解释1:通俗易懂的手推损失函数:
- 解释2:最大似然估计求解参数
- 对损失函数推导梯度
- python代码实现逻辑回归
- 实例展示
- sklearn对比
- L1、L2正则化作比较
- 总结
逻辑回归原理解析
前面我们系统性的介绍了线性回归,初学者建议把我前面的文章看完,再来看逻辑回归。写得应该算是容易看懂的了,且都有实例辅证,大家看的时候要自己跑一边代码,多动手、多思考。
今天,我们来讲逻辑回归。
逻辑回归是LogisticRegression的直译,它不是用来解决回归问题的,而是用来解决分类问题的,它其实是在线性回归的基础上实现的。
我们知道,线性回归针对的是标签为连续值的机器学习任务,那怎样才可以用线性模型做分类任务呢?
例如二分类任务,标签值只有0和1两种。
思考:我们可以建立某种映射关系,将原先的连续值,转为0/1值,
现在请出sigmoid函数:

其函数图像如下:
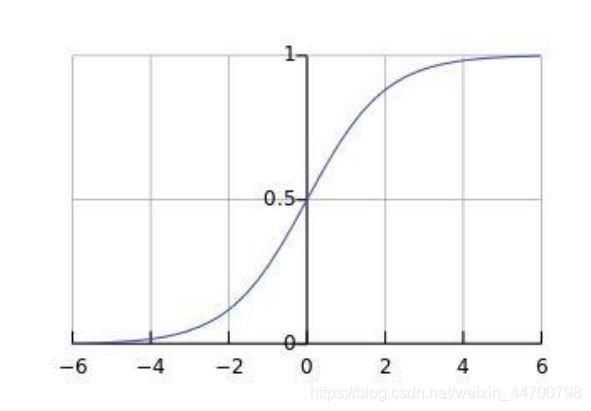
长的很优雅!在自变量实数范围内,它的取值都在0-1之间,完美的映射了线性回归的连续值;
把线性回归的假设函数 z=X 作为x传入其中:
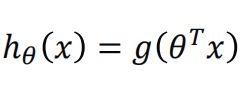
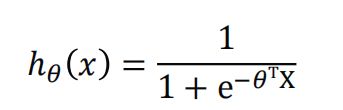
这就是逻辑回归的假设函数,预测函数。
实际上就是在线性回归线的结果上,加上sigmoid函数。
0.5作为分类的边界:
当z >= 0的时候 g(z) >= 0.5,其中z为线性回归函数 z=X
最终类别为1;
当z <= 0的时候g(z) <= 0.5,其中z为线性回归函数 z=X
最终类别为0;
z = 0是临界点!!!
例如下图:
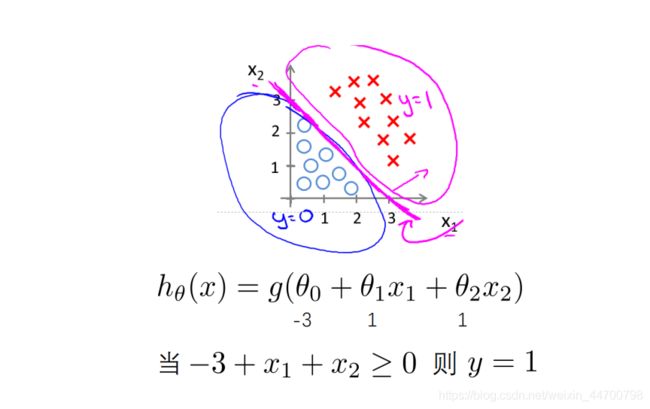
-3 + x1 + x2 = 0这条线,就是临界线。
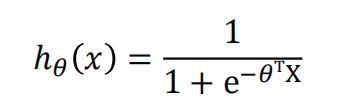
其中 h(x) 的值,是样本属于1类别的概率值,
z = 0时,概率值为0.5;
z > 0时,概率值大于0.5;
z < 0时,概率值小于0.5;
问题:逻辑回归和回归有没有关系?
回答:有关系,对于二分类任务来说,我们对逻辑回归做一个变形,就会发现它本质上是对数几率回归,
金融评分卡就是根据这个公式映射的,所以说逻辑回归是一种广义线性回归。
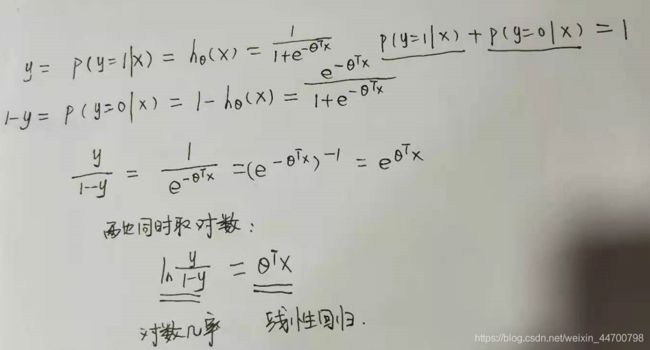
损失函数定义以及数学公式推导过程
有了假设函数,我们开始定义逻辑回归的损失函数,这里继续提出一个问题,用我们常用的最小二乘法作为损失函数,可不可以?
从理论上讲,可以。但是这个时候
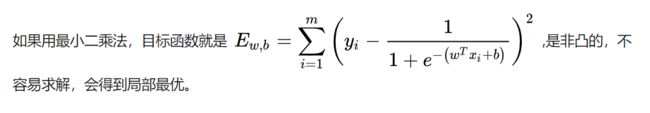
,就没有办法用凸优化算法求解。
我们选用对数损失函数作为损失函数,凸函数,好优化。
解释1:通俗易懂的手推损失函数:

解释2:最大似然估计求解参数

对损失函数推导梯度

python代码实现逻辑回归
class LogisticRegression:
#默认没有正则化,正则项参数默认为1,学习率默认为0.001,迭代次数为10001次
def __init__(self,penalty = None,Lambda = 1,a = 0.001,epochs = 10001):
self.W = None
self.penalty = penalty
self.Lambda = Lambda
self.a = a
self.epochs =epochs
self.sigmoid = lambda x:1/(1 + np.exp(-x))
def loss(self,x,y):
m=x.shape[0]
y_pred = self.sigmoid(x * self.W)
return (-1/m) * np.sum((np.multiply(y, np.log(y_pred)) + np.multiply((1-y),np.log(1-y_pred))))
def fit(self,x,y):
lossList = []
#计算总数据量
m = x.shape[0]
#给x添加偏置项
X = np.concatenate((np.ones((m,1)),x),axis = 1)
#计算总特征数
n = X.shape[1]
#初始化W的值,要变成矩阵形式
self.W = np.mat(np.ones((n,1)))
#X转为矩阵形式
xMat = np.mat(X)
#y转为矩阵形式,这步非常重要,且要是m x 1的维度格式
yMat = np.mat(y.reshape(-1,1))
#循环epochs次
for i in range(self.epochs):
#预测值
h = self.sigmoid(xMat * self.W)
gradient = xMat.T * (h - yMat)/m
#加入l1和l2正则项,和之前的线性回归正则化一样
if self.penalty == 'l2':
gradient = gradient + self.Lambda * self.W
elif self.penalty == 'l1':
gradient = gradient + self.Lambda * np.sign(self.W)
self.W = self.W-self.a * gradient
if i % 50 == 0:
lossList.append(self.loss(xMat,yMat))
#返回系数,和损失列表
return self.W,lossList
实例展示
下面我们继续用sklearn生成数据集,来看看效果
from sklearn.datasets import make_classification
from matplotlib import pyplot as plt
#生成2特征分类数据集
x,y =make_classification(n_features=2,n_redundant=0,n_informative=1,n_clusters_per_class=1,random_state=2043)
#第一个特征作为x轴,第二个特征作为y轴
plt.scatter(x[:,0],x[:,1],c=y)
plt.show()
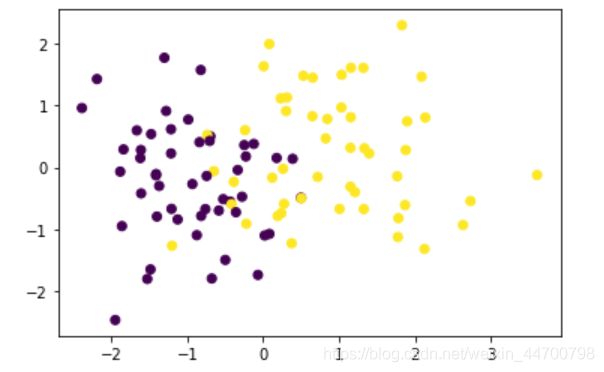
数据分布如上,现在用我们写好的逻辑回归来做分类:
#默认参数
lr = LogisticRegression()
w,lossList = lr.fit(x,y)
#前面讲过,z=0是线性分类临界线
# w[0]+ x*w[1] + y* w[2]=0,求解y (x,y其实就是x1,x2)
x_test = [[-1],[0.7]]
y_test = (-w[0]-x_test*w[1])/w[2]
plt.scatter(x[:,0],x[:,1],c=y)
plt.plot(x_test,y_test)
plt.show()
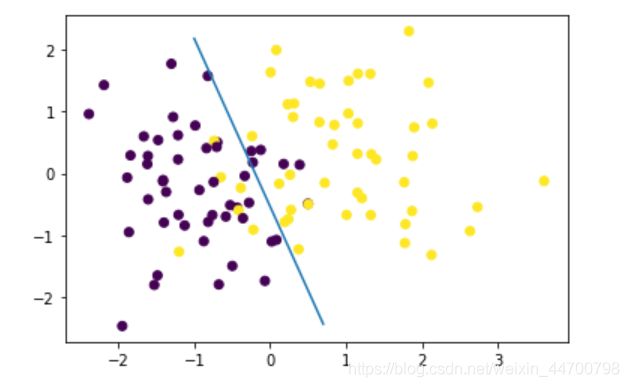
损失图像:
#画图 loss值的变化
n = np.linspace(0,10000,201)
plt.plot(n,lossList,c='r')
plt.title('Train')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.show()
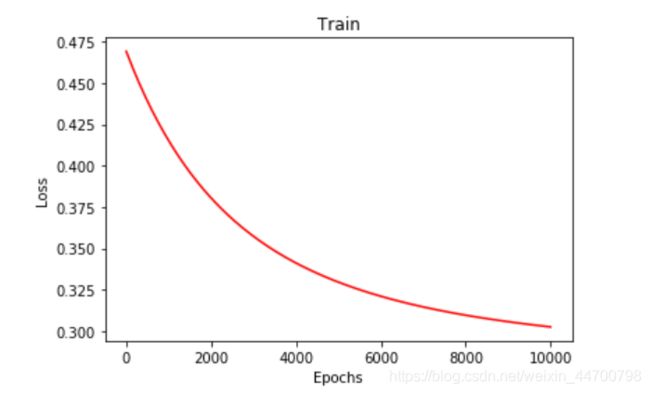
损失随着迭代次数的增加,一直在减小,但是,很明显,当前迭代次数,并没有使得模型参数收敛。
迭代50000次,来看效果:
lr = LogisticRegression(epochs=50000)
w,lossList = lr.fit(x,y)
#前面讲过,z=0是线性分类临界线
# w[0]+ x*w[1] + y* w[2]=0,求解y (x,y其实就是x1,x2)
x_test = [[-1],[0.7]]
y_test = (-w[0]-x_test*w[1])/w[2]
plt.scatter(x[:,0],x[:,1],c=y)
plt.plot(x_test,y_test)
plt.show()
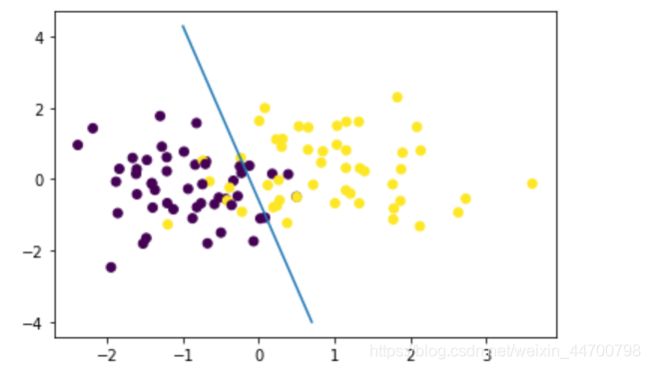
#画图 loss值的变化
n=np.linspace(0,50000,1000)
plt.plot(n,lossList,c='r')
plt.title('Train')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.show()
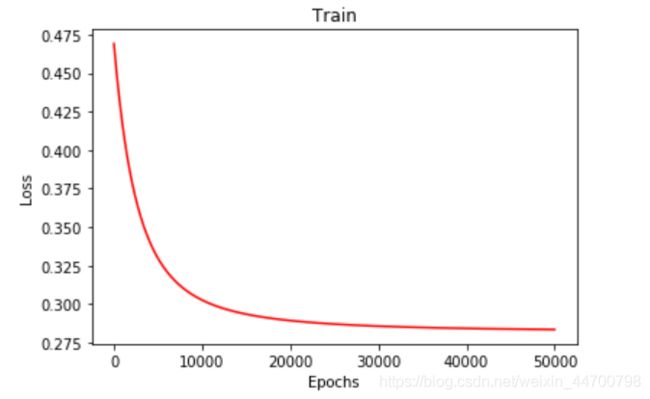
此时模型基本上已经收敛,输出模型参数,计算模型分类效果:
print('模型参数是:\n',w,'\n')
#这里感觉其实处理x,y不应该放在封装好的类里面处理,应该拿出来,作为全局变量使用,优化点
m = x.shape[0]
X = np.concatenate((np.ones((m,1)),x),axis = 1)
xMat = np.mat(X)
y_pred = [1 if x >= 0.5 else 0 for x in lr.sigmoid(xMat*w)]
from sklearn.metrics import classification_report
print(classification_report(y,y_pred))
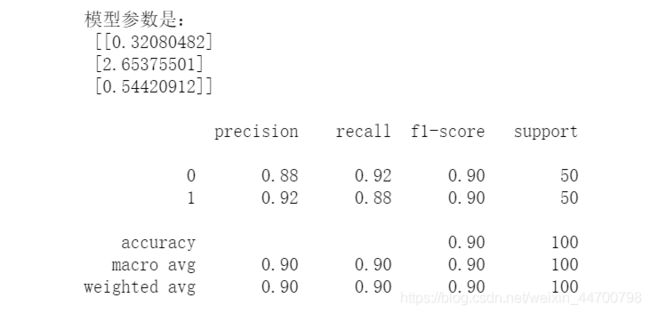
准确率、召回率、F1的值如图所示,整体分类效果还行。
sklearn对比
接下来,我们调用sklearn的逻辑回归库,来分类数据集:
from sklearn.linear_model import LogisticRegression as LR
clf = LR(penalty='none') #查看系数可知,默认带L2正则化,且正则项参数C=1,这里的C是正则项倒数,越小惩罚越大,这里也不用正则化
clf.fit(x,y)
print('sklearn拟合的参数是:\n','系数:',clf.coef_,'\n','截距:',clf.intercept_)
y_pred_1 = clf.predict(x)
print('\n')
print(classification_report(y,y_pred_1))
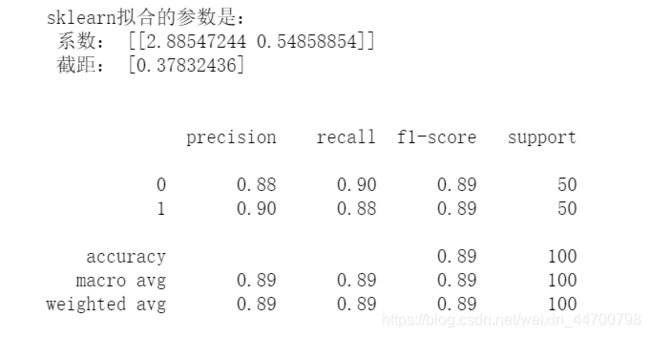
系数比较接近,分类效果也差不多。
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
y_test_1 = (-clf.intercept_ - clf.coef_[0][0] * np.array(x_test))/clf.coef_[0][1]
fig =plt.figure()
ax1= fig.add_subplot()
ax1.scatter(x[:,0],x[:,1],c=y,label='样本分布')
ax1.plot(x_test,y_test,c='r',label='python代码拟合')
ax1.plot(x_test,y_test_1,c='k',label='sklearn拟合')
ax1.legend(prop = {'size':10}) #此参数改变标签字号的大小
plt.show()
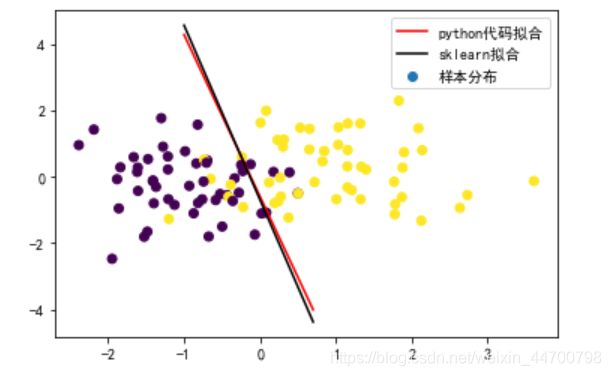
两条分类线基本上重合了。
L1、L2正则化作比较
上面的sklearn逻辑回归中,当clf = LR()即默认L2正则化,C=1时,两个类别F1的值都是0.9。
正则化的比较这里就不展示了,大家可以自行去测试一下,原理和线性回归的正则化原理一样,效果也差不多。
只不过我们自己写的python代码里面Lambda越大,惩罚越强;
而sklearn里面,C越小,惩罚越强。
总结
逻辑回归作为线性回归的变种,它的用途很广,因此掌握它的原理是很有必要的,打好线性回归(逻辑回归也是广义线性回归)的基础,以后对我们学习其他算法大有裨益。
问题:
1、逻辑回归怎么处理多分类问题;
2、应用逻辑回归算法,怎么做样本不均衡的二分类模型;
3、怎么使用正则化;
这里给上刘建平博士的博客链接,写的很精炼:
链接: scikit-learn 逻辑回归类库使用小结
以上问题我们这里就暂不展开讨论了,手写算法系列,我们专注算法的底层原理和数学推导、python代码实现,来帮助大家更好的理解这些算法;
应用层面的问题,我会在随笔栏目中,慢慢补上。