我们将初步了解一下在Kaggle上举办的Home Credit Default Risk机器学习竞赛。这项比赛的目的是利用历史贷款申请数据来预测申请人是否有能力偿还贷款。这是一个标准的二分类任务。
数据介绍
这些数据由Home Credit提供,这是一项专门为无银行账户人群提供信贷额度(贷款)的服务。预测客户是否会偿还贷款或遇到困难是一项关键的业务需求,Home Credit在Kaggle上举办了这场比赛,看看机器学习社区可以开发什么样的模型来帮助他们完成这项任务。
有7种不同的数据来源:
- application_train/application_test:train数据和test数据,包含关于每个家庭信贷贷款申请的信息。每个贷款都有自己的行,并由特性SK_ID_CURR标识。application_train中的TARGET列:0:贷款已偿还;1:贷款未偿还。
- bureau:客户以前从其他金融机构取得的信用数据。每个先前的贷款在bureau中都有自己的行,但是申请数据中的一个贷款可以有多个先前的贷款。
- bureau_balance:关于之前在bureau的信用记录的每月数据。每一行是前一个信用记录的一个月,一个前一个信用记录可以有多个行,每个月的信用记录长度对应一个行。
- bureau_balance:关于之前在bureau的信用记录的每月数据。每一行是前一个信用记录的一个月,一个前一个信用记录可以有多个行,每个月的信用记录长度对应一个行。
- POS_CASH_BALANCE:关于客户以前的销售点或家庭信贷的现金贷款的每月数据。每一行是前一个销售点或现金贷款的一个月,而前一个贷款可以有许多行。
- credit_card_balance:关于以前的信用卡客户使用家庭信用卡的每月数据。每一行是信用卡余额的一个月,一张信用卡可以有很多行。
- installments_payment: 以前在国内贷款的付款历史。每一次付款都有一行,每一次未付款也有一行。
这张图显示了所有的数据是如何关联的:

库
导入我们接下来需要用到的库
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import MinMaxScaler, Imputer
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
读入数据
app_train = pd.read_csv('application_train.csv')
app_test = pd.read_csv('application_test.csv')
print(app_train.shape)
print(app_test.shape)
# print(app_train.head(10)) # 查看前10行数据
输出:
(307511, 122)
(48744, 121)
可以看出训练集有307511个观察值(每个单独的贷款)和122个特征(变量)。
测试集要小得多,并且缺少TARGET列。
检查TARGET列的分布
TARGET是我们要预测的:0表示贷款按时偿还,1表示贷款未按时偿还。我们先检查每一类贷款的数量。
print(app_train['TARGET'].value_counts())
0 282686
1 24825
Name: TARGET, dtype: int64
app_train['TARGET'].astype(int).plot.hist()
plt.show()
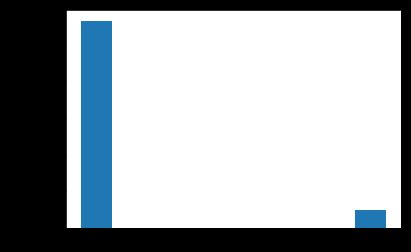
这是一个类别不平衡的问题,我们可以很明显的看出按时偿还贷款的远远比未按时偿还贷款的多。
解决方法
检查缺失值
接下来,我们可以查看每一列中缺失值的数量和百分比。
# 按列计算缺失值
def missing_values_table(df):
# 总缺失值
mis_val = df.isnull().sum()
# 缺失值百分比
mis_val_parent = 100*df.isnull().sum()/len(df)
# 用结果做一个表格
mis_val_table = pd.concat([mis_val, mis_val_parent], axis=1)
# 重命名列
mis_val_table_ren_columns = mis_val_table.rename(
columns={0: 'Missing Values', 1: '% of Total Values'}
)
# 按丢失降序排列的百分比对表进行排序
mis_val_table_ren_columns = mis_val_table_ren_columns[mis_val_table_ren_columns.iloc[:, 1] != 0].sort_values(
'% of Total Values', ascending=False).round(1)
print('Your selected dataframe has ' + str(df.shape[1]) + ' columns.\n'
'There are ' + str(mis_val_table_ren_columns.shape[0]) + ' columns that have missing values.')
return mis_val_table_ren_columns
# 缺失值统计
miss_values = missing_values_table(app_train)
print(miss_values.head(11))
Your selected dataframe has 122 columns.
There are 67 columns that have missing values.
Missing Values % of Total Values
COMMONAREA_MEDI 214865 69.9
COMMONAREA_AVG 214865 69.9
COMMONAREA_MODE 214865 69.9
NONLIVINGAPARTMENTS_MEDI 213514 69.4
NONLIVINGAPARTMENTS_MODE 213514 69.4
NONLIVINGAPARTMENTS_AVG 213514 69.4
FONDKAPREMONT_MODE 210295 68.4
LIVINGAPARTMENTS_MODE 210199 68.4
LIVINGAPARTMENTS_MEDI 210199 68.4
LIVINGAPARTMENTS_AVG 210199 68.4
FLOORSMIN_MODE 208642 67.8
当构建机器学习模型时,我们必须填充这些缺失的值。又或者我们使用XGBoost之类的模型,这些模型可以处理缺失的值。另一种选择是删除具有高丢失值百分比的列。我们现在保留所有的列。
列类型
查看每种数据类型的列数
# 每种类型列的数目
print(app_train.dtypes.value_counts())
float64 65
int64 41
object 16
dtype: int64
我们可以看出有16列是object类型的,我们要把这些转为机器学习可以处理的数值型。
# 每个object列中,不重复值的数目
print(app_train.select_dtypes('object').apply(pd.Series.nunique, axis=0))
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
OCCUPATION_TYPE 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
EMERGENCYSTATE_MODE 2
dtype: int64
标签编码(Label Encoding)和独热编码(One-Hot Encoding)
标签编码:它给类别一个任意的顺序。分配给每个类别的值是随机的,不反映类别的任何固有方面。所以我们在只有两个类别的时候使用标签编码。例如上面的‘NAME_CONTRACT_TYPE’等,我们就可以使用标签编码。
独热编码:为分类变量中的每个类别创建一个新列。当类别>2的时候,我们将使用独热编码。例如上面的‘CODE_GENDER’等。当然独热编码的缺点也很明显,就是特征可能会暴增,但我们可以使用PCA或其他降维方法来减少维数。
# 创建一个LabelEncoder对象
le = LabelEncoder()
le_count = 0
# 标签编码
for col in app_train:
if app_train[col].dtype == 'object':
if len(app_train[col].unique()) <= 2:
le.fit(app_train[col])
app_train[col] = le.transform(app_train[col])
app_test[col] = le.transform(app_test[col])
le_count += 1
print('%d columns were label encoded.' % le_count)
3 columns were label encoded.
train = pd.get_dummies(app_train)
test = pd.get_dummies(app_test)
print('Training Features shape: ', train.shape)
print('Testing Features shape: ', test.shape)
Training Features shape: (307511, 243)
Testing Features shape: (48744, 239)
调整训练集和测试集
在训练集和测试集中需要有相同的特征(列)。独热编码在训练集中创建了更多的列,因为训练集中有TARGET列,而测试集中没有。
train_labels = train['TARGET']
app_train, app_test = train.align(test, join = 'inner', axis = 1)
app_train['TARGET'] = train_labels
print('Training Features shape: ', app_train.shape)
print('Testing Features shape: ', app_test.shape)
Training Features shape: (307511, 240)
Testing Features shape: (48744, 239)
EDA
检查异常值
print((train['DAYS_BIRTH'] / -365).describe())
count 307511.000000
mean 43.936973
std 11.956133
min 20.517808
25% 34.008219
50% 43.150685
75% 53.923288
max 69.120548
Name: DAYS_BIRTH, dtype: float64
看上去很正常没有异常值
print(train['DAYS_EMPLOYED'].describe())
count 307511.000000
mean 63815.045904
std 141275.766519
min -17912.000000
25% -2760.000000
50% -1213.000000
75% -289.000000
max 365243.000000
Name: DAYS_EMPLOYED, dtype: float64
最大值为365243天,也就是1000年,这明显不对,是异常值。
出于好奇,让我们对异常客户进行分析,看看他们的违约率比其他客户高还是低。
anom = train[train['DAYS_EMPLOYED'] == 365243]
non_anom = train[train['DAYS_EMPLOYED'] != 365243]
print('The non-anomalies default on %0.2f%% of loans' % (100 * non_anom['TARGET'].mean()))
print('The anomalies default on %0.2f%% of loans' % (100 * anom['TARGET'].mean()))
print('There are %d anomalous days of employment' % len(anom))
The non-anomalies default on 8.66% of loans
The anomalies default on 5.40% of loans
There are 55374 anomalous days of employment
事实证明,这些异常现象的违约率较低。
处理异常取决于具体情况,没有固定的规则。最安全的方法之一就是将异常设置为一个缺失的值,然后在使用算法之前填充它们。在这种情况下,由于所有的异常值都是相同的,所以我们希望用相同的值来填充它们,以防所有这些贷款都有一个共同点。异常值似乎有一定的重要性。作为一种解决方案,我们将用非数字(np.nan)填充异常值,然后创建一个新的布尔列,指示该值是否异常。
# 创建一个异常标志列
train['DAYS_EMPLOYED_ANOM'] = train['DAYS_EMPLOYED'] == 365243
# 用nan代替异常值
train['DAYS_EMPLOYED'].replace({365243: np.nan}, inplace=True)
test['DAYS_EMPLOYED_ANOM'] = test['DAYS_EMPLOYED'] == 365243
test['DAYS_EMPLOYED'].replace({365243: np.nan}, inplace=True)
print('There are %d anomalies in the test data out of %d entries' % (test["DAYS_EMPLOYED_ANOM"].sum(), len(test)))
There are 9274 anomalies in the test data out of 48744 entries
相关性
现在我们已经处理了分类变量和异常值,让我们继续EDA。一种尝试和理解数据的方法是寻找特征和目标之间的关联。我们可以使用.corr方法计算每个变量与目标之间的Pearson相关系数。
相关系数并不是表示特征“相关性”的最佳方法,但它确实让我们了解了数据中可能存在的关系。对相关系数绝对值的一般解释是:
- .00-.19 “very weak”
- .20-.39 “weak”
- .40-.59 “moderate”
- .60-.79 “strong”
- .80-1.0 “very strong”
# 查看与TARGET的相关系数并排序
correlations = train.corr()['TARGET'].sort_values()
# 显示相关系数
print('Most Positive Correlations:\n', correlations.tail(15))
print('\nMost Negative Correlations:\n', correlations.head(15))
Most Positive Correlations:
OCCUPATION_TYPE_Laborers 0.043019
FLAG_DOCUMENT_3 0.044346
REG_CITY_NOT_LIVE_CITY 0.044395
FLAG_EMP_PHONE 0.045982
NAME_EDUCATION_TYPE_Secondary / secondary special 0.049824
REG_CITY_NOT_WORK_CITY 0.050994
DAYS_ID_PUBLISH 0.051457
CODE_GENDER_M 0.054713
DAYS_LAST_PHONE_CHANGE 0.055218
NAME_INCOME_TYPE_Working 0.057481
REGION_RATING_CLIENT 0.058899
REGION_RATING_CLIENT_W_CITY 0.060893
DAYS_EMPLOYED 0.074958
DAYS_BIRTH 0.078239
TARGET 1.000000
Name: TARGET, dtype: float64
Most Negative Correlations:
EXT_SOURCE_3 -0.178919
EXT_SOURCE_2 -0.160472
EXT_SOURCE_1 -0.155317
NAME_EDUCATION_TYPE_Higher education -0.056593
CODE_GENDER_F -0.054704
NAME_INCOME_TYPE_Pensioner -0.046209
DAYS_EMPLOYED_ANOM -0.045987
ORGANIZATION_TYPE_XNA -0.045987
FLOORSMAX_AVG -0.044003
FLOORSMAX_MEDI -0.043768
FLOORSMAX_MODE -0.043226
EMERGENCYSTATE_MODE_No -0.042201
HOUSETYPE_MODE_block of flats -0.040594
AMT_GOODS_PRICE -0.039645
REGION_POPULATION_RELATIVE -0.037227
Name: TARGET, dtype: float64
年龄对还款的影响
# 找出DAYS_BIRTH和TARGET之间的相关系数
app_train['DAYS_BIRTH'] = abs(app_train['DAYS_BIRTH'])
print(app_train['DAYS_BIRTH'].corr(app_train['TARGET']))
-0.07823930830982694
随着客户年龄的增长,与目标存在负线性关系,这意味着随着客户年龄的增长,他们往往会更经常地按时偿还贷款。
plt.figure(figsize=(10, 8))
# KDE图中按时偿还的贷款
sns.kdeplot(app_train.loc[app_train['TARGET'] == 0, 'DAYS_BIRTH'] / -365, label = 'target == 0')
# KDE图中未按时偿还的贷款
sns.kdeplot(app_train.loc[app_train['TARGET'] == 1, 'DAYS_BIRTH'] / -365, label = 'target == 1')
plt.xlabel('Age (years)')
plt.ylabel('Density')
plt.title('Distribution of Ages')
plt.show()
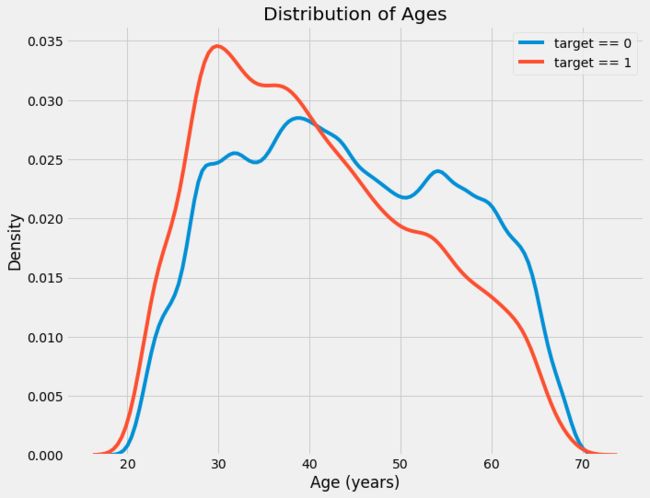
target == 1曲线向范围的较年轻端倾斜。虽然这不是一个显著的相关性(-0.07相关系数),但这个变量很可能在机器学习模型中有用,因为它确实会影响目标。
外部来源
与目标负相关性最强的三个变量是EXT_SOURCE_1、EXT_SOURCE_2和EXT_SOURCE_3。根据文档,这些特征表示“来自外部数据源的标准化得分”。
首先,我们可以显示EXT_SOURCE特性与目标以及彼此之间的关联。
# 提取EXT_SOURCE变量并显示相关性
ext_data = app_train[['TARGET', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
ext_data_corrs = ext_data.corr()
print(ext_data_corrs)
TARGET EXT_SOURCE_1 EXT_SOURCE_2 EXT_SOURCE_3 DAYS_BIRTH
TARGET 1.000000 -0.155317 -0.160472 -0.178919 0.078239
EXT_SOURCE_1 -0.155317 1.000000 0.213982 0.186846 -0.600610
EXT_SOURCE_2 -0.160472 0.213982 1.000000 0.109167 -0.091996
EXT_SOURCE_3 -0.178919 0.186846 0.109167 1.000000 -0.205478
DAYS_BIRTH 0.078239 -0.600610 -0.091996 -0.205478 1.000000
这三个EXT_SOURCE特性都与目标负相关,这表明随着EXT_SOURCE值的增加,客户端更有可能偿还贷款。我们还可以看到DAYS_BIRTH与EXT_SOURCE_1呈正相关,这表明这个评分中的一个因素可能是客户端年龄。
特征工程
多项式特征
关于多项式特征可以看这篇文章
# 为多项式特征创建一个新的dataframe
poly_features = app_train[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH', 'TARGET']]
poly_features_test = app_test[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH']]
imputer = Imputer(strategy='median')
poly_target = poly_features['TARGET']
poly_features = poly_features.drop(columns=['TARGET'])
poly_features = imputer.fit_transform(poly_features)
poly_features_test = imputer.transform(poly_features_test)
poly_transformer = PolynomialFeatures(degree=3)
poly_transformer.fit(poly_features)
poly_features = poly_transformer.transform(poly_features)
poly_features_test = poly_transformer.transform(poly_features_test)
print('Polynomial Features shape: ', poly_features.shape)
print(poly_transformer.get_feature_names(input_features=['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'DAYS_BIRTH'])
[:15])
Polynomial Features shape: (307511, 35)
['1',
'EXT_SOURCE_1',
'EXT_SOURCE_2',
'EXT_SOURCE_3',
'DAYS_BIRTH',
'EXT_SOURCE_1^2',
'EXT_SOURCE_1 EXT_SOURCE_2',
'EXT_SOURCE_1 EXT_SOURCE_3',
'EXT_SOURCE_1 DAYS_BIRTH',
'EXT_SOURCE_2^2',
'EXT_SOURCE_2 EXT_SOURCE_3',
'EXT_SOURCE_2 DAYS_BIRTH',
'EXT_SOURCE_3^2',
'EXT_SOURCE_3 DAYS_BIRTH',
'DAYS_BIRTH^2']
共有35个特征,每个特征的幂次可达3次,并有交互项。现在,我们可以看到这些新特征与目标的相关系数。
poly_features = pd.DataFrame(poly_features,
columns = poly_transformer.get_feature_names(['EXT_SOURCE_1', 'EXT_SOURCE_2',
'EXT_SOURCE_3', 'DAYS_BIRTH']))
poly_features['TARGET'] = poly_target
# 找出与target的相关性
poly_corrs = poly_features.corr()['TARGET'].sort_values()
# 显示最消极和最积极的一面
print(poly_corrs.head(10))
print(poly_corrs.tail(5))
EXT_SOURCE_2 EXT_SOURCE_3 -0.193939
EXT_SOURCE_1 EXT_SOURCE_2 EXT_SOURCE_3 -0.189605
EXT_SOURCE_2^2 EXT_SOURCE_3 -0.176428
EXT_SOURCE_2 EXT_SOURCE_3^2 -0.172282
EXT_SOURCE_1 EXT_SOURCE_2 -0.166625
EXT_SOURCE_1 EXT_SOURCE_3 -0.164065
EXT_SOURCE_2 -0.160295
EXT_SOURCE_1 EXT_SOURCE_2^2 -0.156867
EXT_SOURCE_3 -0.155892
EXT_SOURCE_1 EXT_SOURCE_3^2 -0.150822
Name: TARGET, dtype: float64
EXT_SOURCE_1 EXT_SOURCE_2 DAYS_BIRTH 0.155891
EXT_SOURCE_2 DAYS_BIRTH 0.156873
EXT_SOURCE_2 EXT_SOURCE_3 DAYS_BIRTH 0.181283
TARGET 1.000000
1 NaN
几个新变量与目标的相关性(就绝对值而言)比原来的特征更大。当我们构建机器学习模型时,我们可以尝试使用或不使用这些特性来确定它们是否真的有助于模型的学习。
我们将把这些特性添加到训练集和测试集中,然后评估具有和不具有这些特性的模型。在机器学习中,很多时候,知道一种方法是否有效的唯一方法就是尝试它!
poly_features_test = pd.DataFrame(poly_features_test,
columns = poly_transformer.get_feature_names(['EXT_SOURCE_1', 'EXT_SOURCE_2',
'EXT_SOURCE_3', 'DAYS_BIRTH']))
poly_features['SK_ID_CURR'] = app_train['SK_ID_CURR']
app_train_poly = app_train.merge(poly_features, on = 'SK_ID_CURR', how = 'left')
poly_features_test['SK_ID_CURR'] = app_test['SK_ID_CURR']
app_test_poly = app_test.merge(poly_features_test, on = 'SK_ID_CURR', how = 'left')
app_train_poly, app_test_poly = app_train_poly.align(app_test_poly, join = 'inner', axis = 1)
print('Training data with polynomial features shape: ', app_train_poly.shape)
print('Testing data with polynomial features shape: ', app_test_poly.shape)
Training data with polynomial features shape: (307511, 274)
Testing data with polynomial features shape: (48744, 274)
领域知识特征
我们可以创建几个特性,试图捕捉我们认为对于判断客户是否会拖欠贷款可能很重要的信息。
- CREDIT_INCOME_PERCENT: 信贷金额占客户收入的百分比
- ANNUITY_INCOME_PERCENT: 贷款年金占客户收入的百分比
- CREDIT_TERM: 以月为单位支付的期限(因为年金是每月到期的金额)
- DAYS_EMPLOYED_PERCENT: 就职天数占客户年龄的百分比
app_train_domain = app_train.copy()
app_test_domain = app_test.copy()
app_train_domain['CREDIT_INCOME_PERCENT'] = app_train_domain['AMT_CREDIT'] / app_train_domain['AMT_INCOME_TOTAL']
app_train_domain['ANNUITY_INCOME_PERCENT'] = app_train_domain['AMT_ANNUITY'] / app_train_domain['AMT_INCOME_TOTAL']
app_train_domain['CREDIT_TERM'] = app_train_domain['AMT_ANNUITY'] / app_train_domain['AMT_CREDIT']
app_train_domain['DAYS_EMPLOYED_PERCENT'] = app_train_domain['DAYS_EMPLOYED'] / app_train_domain['DAYS_BIRTH']
app_test_domain['CREDIT_INCOME_PERCENT'] = app_test_domain['AMT_CREDIT'] / app_test_domain['AMT_INCOME_TOTAL']
app_test_domain['ANNUITY_INCOME_PERCENT'] = app_test_domain['AMT_ANNUITY'] / app_test_domain['AMT_INCOME_TOTAL']
app_test_domain['CREDIT_TERM'] = app_test_domain['AMT_ANNUITY'] / app_test_domain['AMT_CREDIT']
app_test_domain['DAYS_EMPLOYED_PERCENT'] = app_test_domain['DAYS_EMPLOYED'] / app_test_domain['DAYS_BIRTH']
模型
Logistic Regression
# 逻辑回归
# 从训练集中删除TARGET列
if 'TARGET' in app_train:
train = app_train.drop(columns = ['TARGET'])
else:
train = app_train.copy()
features = list(train.columns)
test = app_test.copy()
# 缺失值的中值估计
imputer = Imputer(strategy='median')
# 将每个特性缩放到0-1
scaler = MinMaxScaler(feature_range=(0, 1))
imputer.fit(train)
train = imputer.transform(train)
test = imputer.transform(app_test)
scaler.fit(train)
train = scaler.transform(train)
test = scaler.transform(test)
print('Training data shape: ', train.shape)
print('Testing data shape: ', test.shape)
Training data shape: (307511, 278)
Testing data shape: (48744, 278)
现在这个模型已经经过训练,我们可以用它来做预测。我们想预测不偿还贷款的概率,所以我们使用predict.proba()
log_reg = LogisticRegression(C = 0.0001)
log_reg.fit(train, train_labels)
log_reg_pred = log_reg.predict_proba(test)[:, 1]
submit = app_test[['SK_ID_CURR']]
submit['TARGET'] = log_reg_pred
# 将提交文件保存到csv文件中
submit.to_csv('log_reg_baseline.csv', index=False)
提交后,分数为0.671
Random Forest
# 随机森林
random_forest = RandomForestClassifier(n_estimators = 100, random_state = 50, verbose = 1, n_jobs = -1)
random_forest.fit(train, train_labels)
predictions = random_forest.predict_proba(test)[:, 1]
submit = app_test[['SK_ID_CURR']]
submit['TARGET'] = predictions
submit.to_csv('random_forest_baseline.csv', index = False)
提交后,分数为0.678
总结
我们首先了解数据。然后,我们执行了一个相当简单的EDA,试图识别可能有助于建模的关系、趋势或异常。在此过程中,我们执行了必要的预处理步骤,比如对分类变量进行编码、输入缺失的值以及将特性缩放到一个范围。然后,我们从现有的数据构建新特性。最后,我们跑了两个模型。
参考文章