强化学习笔记4:强化学习分类
1 model-free & model-based
model-based(有模型)RL agent,它通过学习环境的状态转移来采取动作。model-free(免模型)RL agent,它没有去直接估计环境状态的转移,也没有得到环境的具体转移变量。它通过学习价值函数和策略函数进行决策。Model-free 的模型里面没有一个环境转移的模型。
1.1 有模型强化学习
我们可以用马尔可夫决策过程来定义强化学习任务,并表示为四元组
如果这四元组中所有元素均已知,且状态集合和动作集合在有限步数内是有限集,则机器可以对真实环境进行建模,通过学习状态转移函数来构建一个虚拟环境,以模拟真实环境的状态和交互反应。

1.2 无模型强化学习
然而在实际应用中,智能体并不是那么容易就能知晓马尔可夫决策过程中的所有元素的。
通常情况下,状态转移函数和奖励函数很难估计,甚至连环境中的状态都可能是未知的,这时就需要采用免模型学习。
免模型学习没有对真实环境进行建模,智能体只能在真实环境中通过一定的策略来执行动作,等待奖励和状态迁移,然后根据这些反馈信息来更新行为策略,这样反复迭代直到学习到最优策略。【让 agent 跟环境进行交互,采集到很多的轨迹数据】
1.3 有模型强化学习和无模型强化学习的区别
总的来说,有模型强化学习相比于无模型强化学习仅仅多出一个步骤,即对真实环境进行建模。(计算 状态转换概率等environment的状态)
因此,一些有模型的强化学习方法,也可以在免模型的强化学习方法中使用。
在实际应用中,如果不清楚该用有模型强化学习还是无模型强化学习,可以先思考一下,在智能体执行动作前,是否能对下一步的状态和奖励进行预测,如果可以,就能够对环境进行建模,从而采用有模型学习。
无模型强化学习通常属于数据驱动型方法,需要大量的采样来估计状态、动作及奖励函数,从而优化动作策略。例如,在 Atari 平台上的 Space Invader 游戏中,无模型的深度强化学习需要大约 2 亿帧游戏画面才能学到比较理想的效果。
相比之下,有模型强化学习可以在一定程度上缓解训练数据匮乏的问题,因为智能体可以在虚拟环境中进行训练。(虚拟环境中知道状态转移函数)
无模型学习的泛化性要优于有模型学习,原因是有模型学习算需要对真实环境进行建模,并且虚拟世界与真实环境之间可能还有差异,这限制了有模型学习算法的泛化性。
有模型的强化学习方法可以对环境建模,使得该类方法具有独特魅力,即“想象能力”。
在无模型学习中,智能体只能根据数据一步一步地采取策略,等待真实环境的反馈;而有模型学习可以在虚拟世界中预测出所有将要发生的事,并采取对自己最有利的策略。(因为有模型学习知道状态转移函数,就知道之后的状态)
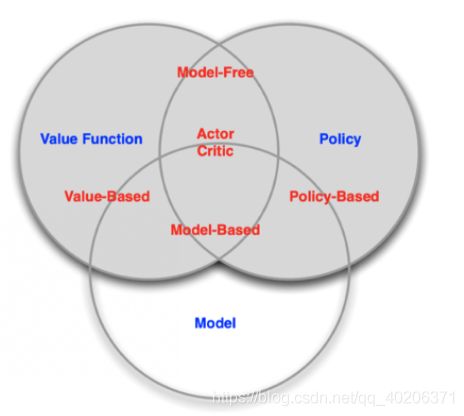
2 基于概率(策略)和基于价值
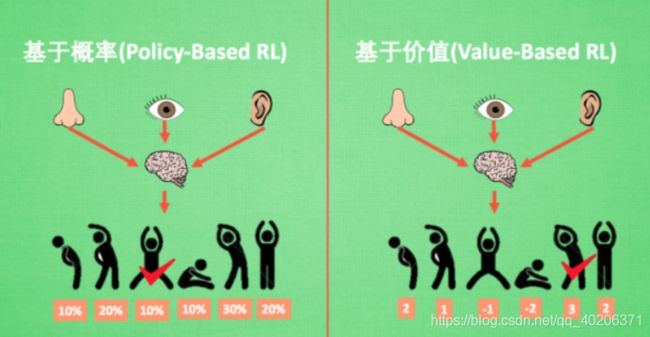
基于概率(策略)是强化学习中最直接的一种, 他能通过分析所处的环境, 直接输出下一步要采取的各种动作的概率, 然后根据概率采取行动, 所以每种动作都有可能被选中, 只是可能性不同.
- 这一类 agent 直接去学习 policy,就是说你直接给它一个状态,它就会输出这个动作的概率。
- 在基于策略的 agent 里面并没有去学习它的价值函数。
在
基于策略迭代的强化学习方法中,智能体会制定一套动作策略(确定在给定状态下需要采取何种动作),并根据这个策略进行操作。强化学习算法直接对策略进行优化,使制定的策略能够获得最大的奖励。

基于价值的方法【agent(value-based agent)】输出则是所有动作的价值, 我们会根据最高价值来选择动作。
- 这一类 agent 显式地学习的是价值函数,
- 隐式地学习了它的策略。策略是从我们学到的价值函数里面推算出来的。
在
基于价值迭代的强化学习方法中,智能体不需要制定显式的策略,它维护一个价值表格或价值函数,并通过这个价值表格或价值函数来选取价值最大的动作。基于价值迭代的方法只能应用在不连续的、离散的环境下(如围棋或某些游戏领域),对于行为集合规模庞大、动作连续的场景(如机器人控制领域),其很难学习到较好的结果(此时基于策略迭代的方法能够根据设定的策略来选择连续的动作)。
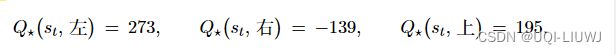
相比基于概率的方法, 基于价值的决策部分更为铁定, 毫不留情, 就选价值最高的, 而基于概率的, 即使某个动作的概率最高, 但是还是不一定会选到他.
我们现在说的动作都是一个一个不连续的动作,。而对于选取连续的动作, 基于价值的方法是无能为力的。我们可以能用一个概率分布在连续动作中选取特定动作, 这也是基于概率的方法的优点之一.
把 value-based 和 policy-based 结合起来就有了 Actor-Critic agent。这一类 agent 把它的策略函数和价值函数都学习了,然后通过两者的交互得到一个最佳的行为。(智能体会根据策略做出动作,而价值函数会对做出的动作给出价值,这样可以在原有的策略梯度算法的基础上加速学习过程,取得更好的效果。)
3 回合更新 和 单步更新

强化学习还能用另外一种方式分类, 回合更新和单步更新。
想象强化学习就是在玩游戏, 游戏回合有开始和结束.。回合更新指的是游戏开始后, 我们要等待游戏这一回合结束, 然后再总结这一回合中的所有转折点, 再更新我们的行为准则。
而单步更新则是在游戏进行中每一步都在更新, 不用等待游戏的结束, 这样我们就能边玩边学习了。
4 在线学习 和 离线学习
在线学习, 就是指我必须本人在场, 并且一定是本人边玩边学习。
离线学习是你可以选择自己玩, 也可以选择看着别人玩, 通过看别人玩来学习别人的行为准则。
离线学习同样是从过往的经验中学习, 但是这些过往的经历没必要是自己的经历, 任何人的经历都能被学习。(比如参数不同的network,类似于DQN的fixed network和回归训练的network,DQN的经验回放)
比如
强化学习笔记:PPO 【近端策略优化(Proximal Policy Optimization)】_UQI-LIUWJ的博客-CSDN博客
中,policy gradient就是on-policy,我从θ中采样τ,然后 梯度上升更新θ;PPO博客中3.4是off-policy,我在θ‘中采样,然后 梯度上升更新θ。
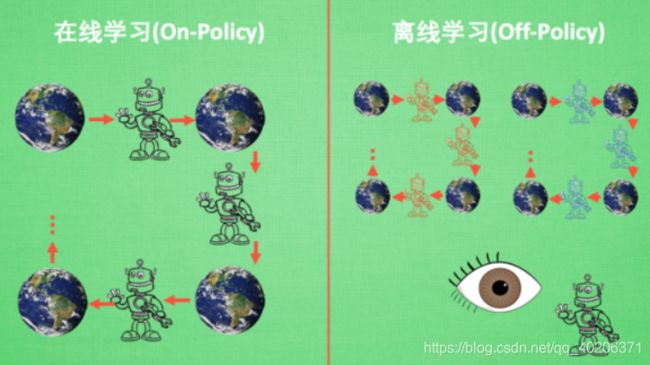
在一些地方,on-policy和off-policy也被称为同策略和异策略
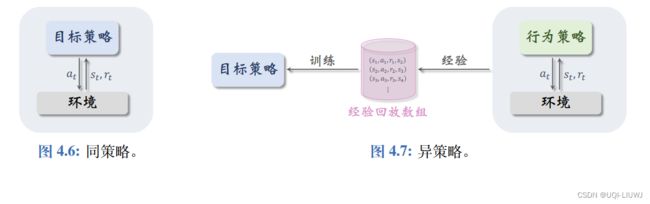
同策略和异策略的“策略”,指的是行为策略和目标策略。
- 行为策略的作用是收集经验 (Experience),即观测的环境、动作、奖励。
- 目标策略的作用是控制agent
同策略是指用相同的行为策略和目标 策略;我们暂时还没有学到同策略。异策略是指用不同的行为策略和目标策略(比如DQN)
经验回放只 适用于异策略,不适用于同策略,其原因是收集经验时用的行为策略不同于想要训练出 的目标策略
参考资料:强化学习方法汇总 - 强化学习 (Reinforcement Learning) | 莫烦Python (mofanpy.com)