(新型事件相机有关的论文解读)EV-FlowNet: Self-Supervised Optical Flow Estimation for Event-based Cameras
目录
- 事件相机有关的论文解读之
-
- EV-FlowNet: Self-Supervised Optical Flow Estimation for Event-based Cameras
-
- 写在前头
- 方法
-
- 数据输入
- 网络结构
- 损失函数
-
- 光度误差
- 光滑损失
- 结果
- 数据集
- 个人总结
事件相机有关的论文解读之
EV-FlowNet: Self-Supervised Optical Flow Estimation for Event-based Cameras
这篇论文是关于事件相机的一篇使用网络的方法进行光流估计的文章。
关于事件相机:
事件相机是一个新型的类脑相机,是一个待开发的大领域。希望通过我的分享,能够有更多人来研究并将它更好地运用在我们的生活中~
对于事件相机还不了解的朋友们可以看我这一系列的另一篇博客:事件相机(Event Camera)及相关研究简介——新一代相机?新的计算机视觉领域?
这篇论文的地址:http://www.roboticsproceedings.org/rss14/p62.pdf
作者在youtube上上传了项目的视频: https://youtu.be/eMHZBSoq0sE
作者提供了tensorflow的源码:https://github.com/daniilidis-group/EV-FlowNet
我将作者源码改编成了pytorch版本,也上传到了github上面,pytorch玩家可以看过来~:https://github.com/Cyril-Sterling/EVFlowNet-pytorch
下面我们开始叭
写在前头
作者的这篇文章只是做了光流估计,原理也较为简单,但是这篇文章却可以说是事件相机领域成功运用FlowNet类似的下采样、上采样结构进行光流估计的开山之作。
同时,作者也提出了一个新的数据输入方法,即如何将四元组格式的数据整合为图片输入到网络中。
方法
数据输入
原文部分翻译:
在这项工作中,我们选择使用图像形式表示事件。 网络的输入是一个分辨率与相机相同的4通道图像。前两个通道分别编码在每个像素处发生的正事件和负事件的数量。这种事件计数是可视化事件流的一个常用方法,已经在很多文章中被证明在一个基于学习的框架中可以提供信息,从而回归6个自由度的姿态。
但是,单独的统计事件数会丢弃时间戳中的有价值信息,而时间戳中隐藏了图像中的运动规律。 以图像形式合并时间戳是一项具有挑战性的任务。我们将最后两个通道中的像素分别编码为该像素上最近的正事件和负事件的时间戳。虽然这种表示方式本质上抛弃了所有的时间戳,但是每个像素的时间戳是最近的,我们观察到这种表示方式足以让网络估计大多数区域的正确流。这种表示法的一个不足之处是,事件非常密集和运动非常大的区域将使所有像素被具有非常相似时间戳的非常近期的事件覆盖。不过这个问题可以通过选择较小的时间窗口来避免,这样可以降低运动的幅度。
解读:
按照作者的想法,在每个时间窗口中发生的所有事件,他们的时间戳越靠近当前时间,那么这个时间戳包含的信息越多,越有用。所以作者把输入网络的图片定义为一个四通道图片,前两通道为每个像素事件数的累加和,后两通道为每个像素上发生过的最后一个事件的时间戳。这样能反映更多的运动信息。前两通道称为count image,后两通道称为time image。
下图为可视化后的time image:


可以看到时间戳图像确实保留了很明显的运动痕迹。
网络结构
网络基本类似rgb界的FlowNet,如下:

输入大小为256×256×4的随机裁剪和旋转后的上述四通道图。绿色为下采样(编码)部分,通过步长为2的卷积实现,每一层的卷积结果保留,作为跳层链接到上采样(解码)层。在四层下采样(编码)后,中间两个蓝色的为两个残差块,对特征进行进一步提取。后面黄色的为上采样(解码)部分,通过对称padding实现。每一层的结果通过一个卷积核大小为1*1的卷积,称为二通道的光流估计图(即图中向上的箭头),然后将在这个尺度计算一个loss,之后将这个光流估计图和这一层原来的图以及跳层链接的图进行cat连接,再通过上采样进入下一层。
损失函数
作者提出损失函数由两部分组成:光度误差与光滑误差。
光度误差
根据光流的定义,预测出的光流应该能够将时间窗口末的图片映射为事件窗口初的图片。这里的图片为DAVIS提供的灰度图。在做这样的映射后,逐像素计算光度误差,即为光度损失:

光滑损失
预测到的光流应该是光滑的,所以定义光滑损失:
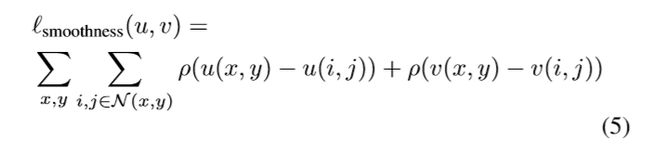
总误差为两误差和:

λ \lambda λ为一个超参数,光滑误差的权重。
在作者后来的代码中,作者还加入了weight decay loss防止过拟合。
结果
作者通过普通的单目法从灰度图中获得了光流作为ground truth,然后做了测试。

在阅读代码时可以看到,作者将每个时间窗口划分为6等分,然后每次在生成输入网络的四通道图片时,产生一个1-6的随机数,来决定累加其中的几份。
在测试时作者规定了这个数,即为上图中dt=1与dt=4。可以看到,在累加窗口变长后,准确率有所降低。
数据集
作者使用的数据集为MVSEC,是一个超大型的事件相机数据集,可用于光流估计,深度估计,姿态估计等。
该数据集链接如下:https://daniilidis-group.github.io/mvsec/
个人总结
这篇文章成功的运用了FlowNet类结构的网络从事件相机数据中预测光流,损失函数和网络结构简单实用,文章中说网络可以在GTX1050上跑到48ms(亲测在GTX1060上课跑到十几毫秒)。但如文章标题,作为一种自监督的算法,还是需要灰度图的参与作为监督。所以如何找出不需要灰度图的无监督方法是所有人都在思考的。同样这篇文章的作者在后来提出了这个网络的改进版,我们之后再分享。
同时,这样的方法需要将数据先进行处理再放入网络,这个处理过程是较为麻烦的,所以能否提出端到端的学习方法也是另一个方面。之后也有很多文章进行改进提出了端到端的方法。