Mantium 如何在 Amazon SageMaker 上使用 DeepSpeed 实现低延迟 GPT-J 推理

前言
Mantium (https://mantiumai.com/)是一家全球云平台提供商,致力于构建 AI 应用程序并对它们进行规模化管理。利用 Mantium 的端到端开发平台,与传统方式相比,各种规模的企业能更快、更轻松地构建 AI 应用程序和实现自动化。借助 Mantium,技术和非技术团队可采用低代码方式原型设计、开发、测试和部署 AI 应用程序。通过自动日志记录、监控和安全功能,Mantium 还解放了软件和 DevOps 工程师,他们不需要花时间做重复性工作了。在较高的层面上,Mantium 提供了:
最先进的 AI – 使用一系列精选的开源和私有大型语言模型以及简单的 UI 或 API 进行试验和开发。
AI 流程自动化 – 利用不断扩大的集成库和 Mantium 的图形化 AI Builder,轻松构建 AI 驱动型应用程序。
快速部署 – 利用一键式部署,将生产时间线从几个月缩短至几周甚至几天。只需单击一次,此功能就会将 AI 应用程序转换为可共享的 Web 应用程序。
安全与监管 – 确保安全并遵守治理政策,同时支持人机回圈流程。
借助 Mantium AI Builder,您可以开发先进的工作流来集成外部 API、逻辑运算和 AI 模型。以下屏幕截图显示了一个示例 Mantium AI 应用程序,该应用程序将 Twilio 输入、治理政策、AI 块(可以依赖像 GPT-J 这样的开源模型)和 Twilio 输出联系起来。

为了支持此应用程序,Mantium 不仅提供对来自 Open AI、Co:here 和 AI21 等 AI 提供商的模型 API 的全面统一的访问,还提供最先进的开源模型。在 Mantium,我们认为任何人都应能够构建他们自己的端到端现代 AI 应用程序,为此,我们提供了对性能优化的开源模型的无代码和低代码访问。
例如,Mantium 的核心开源模型之一是 GPT-J,它是由 EleutherAI 开发的最先进的自然语言处理(NLP,Natural Language Processing)模型。GPT-J 拥有 60 亿个参数,是规模最大、性能最优的开源文本生成模型之一。Mantium 用户可以通过 Mantium 的 AI Builder 将 GPT-J 集成到其 AI 应用程序中。对于 GPT-J,这需要指定一个提示(模型应执行的操作的自然语言表示形式)并配置一些可选参数。
GPT-J:
https://github.com/kingoflolz/mesh-transformer-jax/#gpt-j-6b
EleutherAI :
https://www.eleuther.ai/
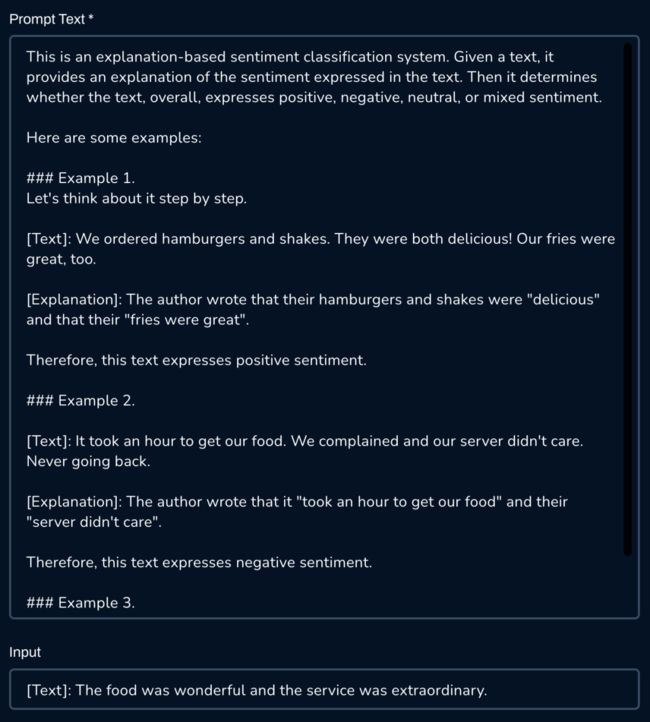
例如,以下屏幕截图显示了生成解释和情绪预测的情绪分析提示的简短演示。在此示例中,作者的原文是“食物很美味”并且“他们的服务非常出色”。因此,这段文字表达了积极的情绪。
但开源模型面临一个挑战,即它们很少为实现生产级性能而设计。对于像 GPT-J 这样的大型模型,根据使用案例的不同,这可能会使生产部署变得不切实际甚至不可行。
为了确保我们的用户能够实现一流性能,我们一直在寻找减少核心模型延迟的方法。在本博文中,我们描述了一个推理优化实验的结果,在该实验中,我们使用 DeepSpeed 的推理引擎将 GPT-J 的推理速度加快了约 116%。
我们还介绍了如何在 Amazon SageMaker(https://aws.amazon.com/cn/sagemaker/)推理端点中使用 DeepSpeed 部署 GPT-J 的 Hugging Face Transformers 实施。
GPT-J 模型概览
GPT-J 是一种生成式预训练(GPT,Generative Pretrained)语言模型,就其架构而言,它和常用的私有大型语言模型(例如 Open AI 的 GPT-3)相当。如前所述,它由大约 60 亿个参数和 28 个层构成,其中包括一个前馈块和一个自我注意块。在 GPT-J 首次发布时,它是最早使用旋转嵌入的大型语言模型之一,旋转嵌入是一种新的位置编码策略,它统一了绝对位置编码器和相对位置编码器。它还采用了一种创新性的并行化策略,将密集层和前馈层并入一个层,从而最大限度地减少通信开销。
尽管以今天的标准来看,GPT-J 可能还不够大(大型模型通常包含超过 1000 亿个参数),但它仍然具有令人印象深刻的性能,并且通过一些及时的工程设计或最小微调,您可以使用它来解决许多问题。此外,它的尺寸相对适中,与大型模型相比,您可以更快地部署它,而且成本要低得多。
也就是说,GPT-J 仍然相当大。例如,在 FP32 中使用完整权重更新和 Adam 优化器训练 GPT-J 需要超过 200 GB 的内存:模型参数占用 24 GB,渐变占用 24 GB,Adam 的平方梯度占用 24 GB,优化器状态占用 24 GB,其他内存量用于加载训练批次和存储激活项。当然,在 FP16 中训练可以将所需内存减少近一半,但超过 100 GB 的内存占用仍需要创新性的训练策略。例如,Mantium 的 NLP 团队与 SageMaker 合作,开发了一个使用 SageMaker 分布式模型并行库训练(微调)GPT-J 的工作流。
旋转嵌入:
https://blog.eleuther.ai/rotary-embeddings/
工作流:
https://github.com/aws/amazon-sagemaker-examples/tree/main/training/distributed_training/pytorch/model_parallel/gpt-j

相比之下,使用 GPT-J 进行推理所需的内存要少得多 – 在 FP16 中,模型权重占用不到 13 GB,这意味着可以在单个 16 GB GPU 上轻松执行推理。但是,使用现成的 GPT-J 实施(例如,我们使用的 Hugging Face Transformers 实施)进行推理的速度相对较慢。为了支持需要高响应性的文本生成的使用案例,我们专注于减少 GPT-J 的推理延迟。
Hugging Face Transformers 实施:
https://huggingface.co/EleutherAI/gpt-j-6B
GPT-J 的响应延迟挑战
响应延迟是生成式预训练转换器(GPT,Generative Pretrained Transformer)(例如 GPT-J)面临的主要障碍,这些转换器为现代文本生成提供支持。GPT 模型通过一系列推理步骤来生成文本。在每个推理步骤中,将为模型提供文本作为输入,并根据该输入对词汇表中的某个词进行采样以追加到文本。例如,给定令牌序列“我需要一把伞,因为”,则下一个令牌极有可能是“正在下雨”。不过,它也可能是“阳光太强”或“备用”,这可能是迈向“我需要一把伞,因为肯定要下雨了。”这样的文本序列的第一个推理步骤。
诸如此类的场景给部署 GPT 模型带来了一些有趣的挑战,因为实际的使用案例可能涉及数十、数百甚至数千个推理步骤。例如,生成 1000 个令牌的响应需要 1000 个推理步骤!因此,尽管一个模型提供的推理速度在孤立情况下可能看起来足够快,但在生成长文本时,延迟易于达到难以维持的水平。我们发现,在 V100 GPU 上,每个推理步骤的平均延迟为 280 毫秒。对于一个包含 67 亿个参数的模型来说,这似乎很快,但在这样的延迟下,生成 500 个令牌的响应大约需要 30 秒,从用户体验的角度来看,这并不理想。
使用 DeepSpeed Inference
加快推理速度
DeepSpeed (https://www.deepspeed.ai/)是由 Microsoft 开发的开源深度学习优化库。尽管 DeepSpeed 主要侧重于优化大型模型的训练,但它也提供了一个推理优化框架,该框架支持一组精选模型,包括 BERT、Megatron、GPT-Neo、GPT2 和 GPT-J。DeepSpeed Inference 通过将模型并行性、推理优化的 CUDA 内核和量化相结合,为基于转换器的大型架构提供高性能推理。
为了使用 GPT-J 加快推理速度,我们使用 DeepSpeed 的推理引擎将优化后的 CUDA 内核注入 Hugging Face Transformers GPT-J 实施中。
为了评估 DeepSpeed 的推理引擎的速度优势,我们进行了一系列的延迟测试,其中,我们在各种配置下对 GPT-J 进行了计时。具体而言,我们在是否使用 DeepSpeed、硬件、输出序列长度和输入序列长度上做出了变化。我们专注于输出序列长度和输入序列长度,因为它们都影响推理速度。要生成包含 50 个令牌的输出序列,模型必须执行 50 个推理步骤。此外,执行推理步骤所需的时间取决于输入序列的大小,即输入越大,所需的处理时间越多。虽然输出序列大小产生的影响远大于输入序列大小,但仍需考虑这两个因素。
在我们的实验中,我们使用了以下设计:
DeepSpeed 推理引擎 – 打开、关闭
硬件 – T4(ml.g4dn.2xlarge)、V100(ml.p3.2xlarge)
输入序列长度 – 50、200、500、1000
输出序列长度 – 50、100、150、200
总的来说,该设计包含这四个因素的 64 种组合,对于每种组合,我们进行了 20 次延迟测试。每次测试都在预先初始化的 SageMaker 推理端点上运行,确保我们的延迟测试反映生产时间,包括 API 交换和预处理。
我们的测试表明,DeepSpeed 的 GPT-J 推理引擎比基准 Hugging Face Transformers PyTorch 实现要快得多。下图说明了 ml.g4dn.2xlarge 和 ml.p3.2xlarge SageMaker 推理端点上使用和不使用 DeepSpeed 加速的 GPT-J 的平均文本生成延迟。
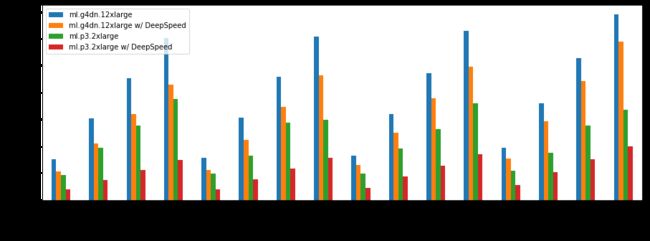
在配备了 16 GB NVIDIA T4 GPU 的 ml.g4dn.2xlarge 实例上,我们发现平均延迟减少了约 24% [标准差 (SD) = 0.05]。这相当于从平均每秒 12.5(SD = 0.91)个令牌增加到平均每秒 16.5(SD = 2.13)个令牌。
值得注意的是,在配备了 NVIDIA V100 GPU 的 ml.p3.2xlarge 实例上,DeepSpeed 的加速效果甚至更好。在该硬件上,我们发现平均延迟减少了 53%(SD = 0.07)。就每秒令牌数而言,这相当于从平均每秒 21.9(SD = 1.97)个令牌增加到平均每秒 47.5(SD = 5.8)个令牌。
我们还发现,随着输入序列的增大,DeepSpeed 提供的加速在两种硬件配置上都略有减弱。但在所有条件下,使用 DeepSpeed 的 GPT-J 优化进行推断的速度仍比基准快得多。例如,在 g4dn 实例上,最大和最小延迟减少分别为 31%(输入序列大小 = 50)和 15%(输入序列大小 = 1000)。在 p3 实例上,最大和最小延迟减少分别为 62%(输入序列大小 = 50)和 40%(输入序列大小 = 1000)。
在 SageMaker 推理端点上
使用 DeepSpeed 部署 GPT-J
除了显著提高 GPT-J 的文本生成速度之外,DeepSpeed 的推理引擎还可以轻松集成到 SageMaker 推理端点中。在将 DeepSpeed 添加到我们的推理堆栈之前,我们的端点是在基于官方 PyTorch 映像的自定义 Docker 映像上运行的。利用 SageMaker,可以非常轻松地部署自定义推理端点,并且集成 DeepSpeed 就像包含依赖项和编写几行代码那样简单。GitHub 上提供了使用 DeepSpeed 部署 GPT-J 的部署工作流程的开源指南(https://github.com/mantiumai/aws-sagemaker-gptj-deepspeed-blog)。
结论
Mantium 致力于引领创新,让每个人都能使用 AI 快速构建。从 AI 驱动型流程自动化到严格的安全和合规性设置,我们技术娴熟的的平台提供了大规模开发和管理强大、可靠的 AI 应用程序所需的所有工具,并降低了进入门槛。SageMaker 帮助像 Mantium 这样的公司快速进入市场。
要了解 Mantium 如何帮助您为企业构建综合性 AI 驱动型工作流,请访问 www.mantiumai.com。
本篇作者

Joe Hoover
Mantium 的 AI 研发团队的高级应用科学家。他热衷于开发模型、方法和基础设施,帮助人们利用尖端的 NLP 系统解决实际问题。

Dhawal Patel
亚马逊云科技的首席机器学习架构师,致力于解决与分布式计算和人工智能有关的问题。专注于深度学习,包括 NLP 和计算机视觉领域,帮助客户在 SageMaker 上实现了高性能模型推理。

Sunil Padmanabhan
亚马逊云科技初创公司解决方案架构师。他对机器学习充满热情,专注于帮助初创公司利用 AI/ML 实现业务成果,并大规模设计和部署 ML/AI 解决方案。
听说,点完下面4个按钮
就不会碰到bug了!