文章运行环境:go version go1.16.6 darwin/amd64
并发不安全
看下面的代码,大家觉得会输出什么?大多数人应该都会觉得输出""、abc、neoj 这三种情况,但真实的情况并不是这样,真实情况是只输出 “” 空字符串。
结合日常的工作,类似这种并发操作同一个变量的情况也比较常见,为什么业务没有发生异常问题?
var name string = ""
func main() {
go func() {
for {
name = "abc"
}
}()
go func() {
for {
name = "neoj"
}
}()
for {
fmt.Println(name)
}
}
1.14 之后引入了 G 抢占式调度,那为什么代码中的两个协程没有执行呢?其实是编译器做了优化,这两个协程被省略掉了。
我们对代码做一点调整,在协程中加一行空的输出,输出结果中出现了一些特例,比如:neo、abca。其中,neo 字符串长度等于 abc 的长度,而 abca 的长度等于 neoj 的长度。
var name string = ""
func main() {
go func() {
for {
name = "abc"
fmt.Printf("")
}
}()
go func() {
for {
name = "neoj"
fmt.Printf("")
}
}()
for {
if name != "abc" && name != "neoj" {
fmt.Println(name)
}
}
}
例子说明,string 的赋值并不是原子的。
Go 语言中 string 的内存结果如下,它包含两部分:Data 表示实际的数据部分,而 Len 表示字符串的长度。
所以,通过方法 len 来计算字符串的长度并不会有性能开销,len 方法会直接返回结构体的 Len 属性;而传递字符串类型的参数,使用指针类型和值类型,性能上也不会有太大差别。
type StringHeader struct {
Data uintptr
Len int
}
字符串的并发不安全,主要就是给这两个字段的赋值,没有办法保证原子性。参考 runtime/string.go 中的源码,我们可以了解字符串生成过程。
并发赋值的情况下,Data 指向的地址和 Len 无法保证一一对应。所以,通过 Data 获取到内存的首地址,通过 Len 去读取指定长度的内存时,就会出现内存读取异常的情况。
func rawstring(size int) (s string, b []byte) {
p := mallocgc(uintptr(size), nil, false)
stringStructOf(&s).str = p
stringStructOf(&s).len = size
*(*slice)(unsafe.Pointer(&b)) = slice{p, size, size}
return
}
rawstring 函数在字符串拼接的时候被调用,我们代码中创建一个字符串类型,每次都生成一份新的内存空间。特别强调,创建和字符串赋值需要区分开来。赋值的过程其实是值拷贝,拷贝的便是 StringHeader 结构体。
var name string = ""
func main() {
blog := name
fmt.Println(blog)
}
上面的变量 blog 是 name 的值拷贝,底层指向的字符串是同一块内存空间。这个赋值过程中,发生拷贝的只是外层的 StringHeader 对象。
Go 中通过 unsafe 包可以强制对内存数据做类型转换,我们将 blog 和 name 的内存地址打印出来比较一下。最终打印输出两个变量的地址和Data地址。可以看出,赋值前后,Data指向的地址并没有发生变化。
type StringHeader struct {
Data uintptr
Len int
}
var name string = "g"
func main() {
blog := name
n := (*StringHeader)(unsafe.Pointer(&name))
b := (*StringHeader)(unsafe.Pointer(&blog))
fmt.Println(&n, n.Data) // 0xc00018a020 17594869
fmt.Println(&b, b.Data) // 0xc00018a028 17594869
}
string 并发不安全读写,会导致线上服务偶发 panic。比如使用 json 对内存异常的 string 做序列化的时候。下面的例子中,其中一个协程用来赋值为空,非常容易复现 panic。
type People struct {
Name string
}
var p *People = new(People)
func main() {
go func() {
for {
p.Name = ""
}
}()
go func() {
for {
p.Name = "neoj"
}
}()
for {
_, _ = json.Marshal(p)
}
}
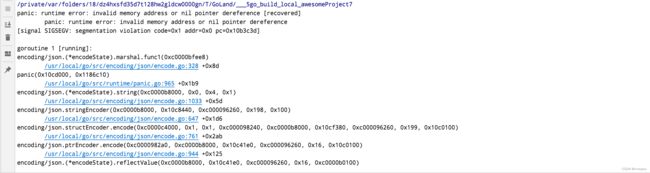
下面是 panic 的堆栈信息,空字符串的 Data 指向的是 nil 的地址,而并发导致 Len 字段有值,最终导致发生 panic。
竞态竞争
对同一个变量并发读写,如果没有使用辅助的同步操作,就会出现不符合预期的情况。直白的讲,我们开发完一个程序之后,针对同样的输入,会输出什么结果,我们是不确定的。
可以参考 The Go Memory Model 的介绍,强调一下数据竞争的概念:
A data race is defined as a write to a memory location happening concurrently with another read or write to that same location, unless all the accesses involved are atomic data accesses as provided by the sync/atomic package
幸运的是,Go 已经集成了现成的工具来诊断数据竞争:-race。在 go build、或者直接执行的时候,指定 -race 属性,系统会做数据竞争检测,并打印输出。
以最近的代码为例,如果你使用的也是 goland 编译器,只需要在 Run Configurations / Go tool arguments 中指定 -race 属性,运行程序,就会出现下面的检测结果:

面对生产环境,-race 有比较严重的性能开销,我们最好是开发环境做竞态检测。
-race 是通过编译器注入代码来执行检测的,在函数执行前、执行后都会做内存统计。也就是说:只有被执行到的代码才能被检测到。所以,如果开发阶段做竞态检测的话,一定要保证代码被执行到了。
再加上埋点的内存统计也是有策略的,也不可能保证存在数据竞争的代码就一定会被检测出来,最好可以多执行几次来避免这种情况。
字符串优化
因字符串并发读写导致的 panic,很容易被 Go 的字符串优化带偏。
我在第一次遇到这种情况的时候,想到的居然是:会不会是底层优化导致的。因为发生 panic 的代码用到了 map 的数据结构。这种想法很快被我用测试用例排除了。
[]byte 到 string 类型转换是比较常规的操作,正常情况下,转换都会申请了一份新的内存空间。但 Go 为了提高性能,在某些场景下 string 和 []byte 会共用一份内存空间,这种场景下也能写乱内存。
// slicebytetostringtmp returns a "string" referring to the actual []byte bytes.
//
func slicebytetostringtmp(ptr *byte, n int) (str string) {
if raceenabled && n > 0 {
racereadrangepc(unsafe.Pointer(ptr),
uintptr(n),
getcallerpc(),
funcPC(slicebytetostringtmp))
}
if msanenabled && n > 0 {
msanread(unsafe.Pointer(ptr), uintptr(n))
}
stringStructOf(&str).str = unsafe.Pointer(ptr)
stringStructOf(&str).len = n
return
}
程序中出现问题,还是要先充分审查自己开发的代码
到此这篇关于GoLang string类型深入分析的文章就介绍到这了,更多相关Go string内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!