MySQL刷题笔记 Leetcode&牛客
MySQL刷题记录
文章目录
- MySQL刷题记录
-
- Leetcode
-
- 176 第二高的薪水 坑多
- 175. 组合两个表 区分JOIN和WHERE
- 1693. 每天的领导和合伙人 DISTINCT去重
- 1890. 2020年最后一次登录 MAX()用于DATE数据
-
- 1501. 可以放心投资的国家 综合应用
- 牛客网
Leetcode
176 第二高的薪水 坑多
题目描述:

本题坑很多,很多地方需要注意:
1、 [首要问题]如何输出第二高的薪水,语法上怎么解决
2、没有第二高的薪水时不能空着,必须填入NULL
3、注意"第二高"的定义,不论有几行的取值相同,数值第二高就输出(属于DENSE_RANK())
4、 报错"Every derived table must have its own alias
"是说派生出的表必须要有别名(alias),在外层FROM(…)后面加上别名即可,因为内层的表是在外层(用别名)引用,所以别名加在外层查询的FROM后面
5、注意限制返回的行数,因为第二高的值本身只有一个,所以只应返回一行
改良3遍后的代码:
SELECT (
SELECT DISTINCT salary AS SecondHighestSalary
FROM (SELECT id,salary ,(DENSE_RANK() OVER (ORDER BY salary DESC) ) AS ranking
FROM Employee
)AS P2
WHERE ranking='2'
)AS SecondHighestSalary;
- 输出第二高的薪水,我的直观想法是加RANK(),官方解答用LIMIT+OFFSET解决的
- 之所以多加一层SELECT,是为了把有时输出的空白值切实地规范化成
NULL
175. 组合两个表 区分JOIN和WHERE
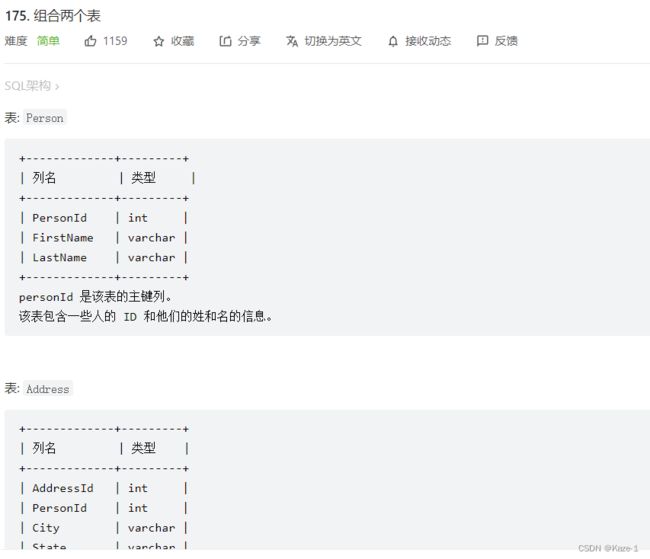

直接用外连接就完事(只对一个表施加限定条件,用外连接,空缺的部分会自动填成NULL)
SELECT firstName,lastName,city,state
FROM Person AS P1
LEFT JOIN Address AS P2 ON P1.PersonId=P2.PersonId;
这里不可以使用WHERE,否则没有地址信息的人信息会被筛掉,只有内连接时WHERE和ON等价,一般JOIN用ON即可
1693. 每天的领导和合伙人 DISTINCT去重
写一条 SQL 语句,使得对于每一个 date_id 和 make_name,返回不同的 lead_id 以及不同的 partner_id 的数量。 按 任意顺序 返回结果表。
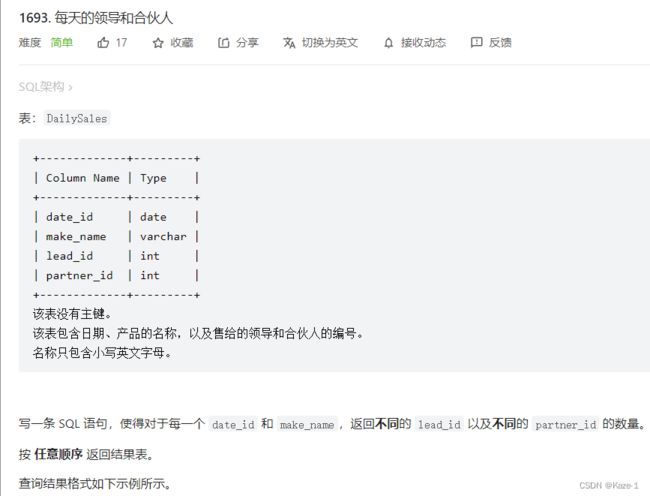
题目重点:不同的xx ID,所以必须要去重再求和,不能累加重复的数值(没注意到这一点的我一直在改,心很累)
SELECT date_id, make_name,COUNT(DISTINCT lead_id) AS unique_leads,
COUNT(DISTINCT partner_id) AS unique_partners
FROM DailySales
GROUP BY date_id,make_name
1890. 2020年最后一次登录 MAX()用于DATE数据
题目:
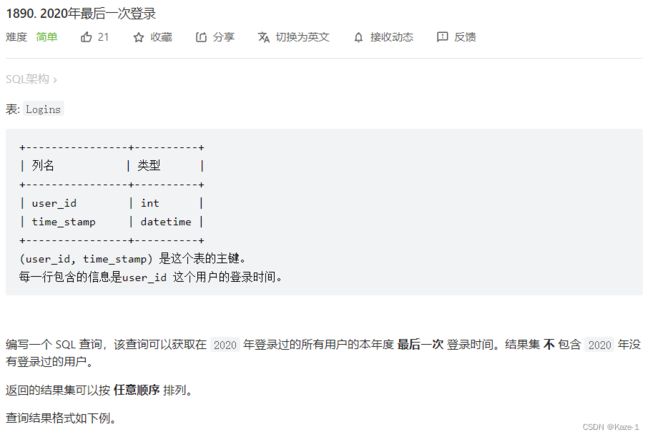
这一题的关键是想到使用MAX()函数,否则很不好解决,必须记住时间信息也可以正常比较大小
代码:
SELECT user_id,MAX(time_stamp) AS last_stamp
FROM Logins
WHERE time_stamp BETWEEN '2020-01-01 00:00:00' AND '2020-12-31 23:59:59'
GROUP BY user_id
或者用YEAR()函数,截取对应的年份字段,从而确保这是2020年内的数据
SELECT user_id,MAX(time_stamp) AS last_stamp
FROM Logins
WHERE YEAR(time_stamp)=2020
GROUP BY user_id
1501. 可以放心投资的国家 综合应用
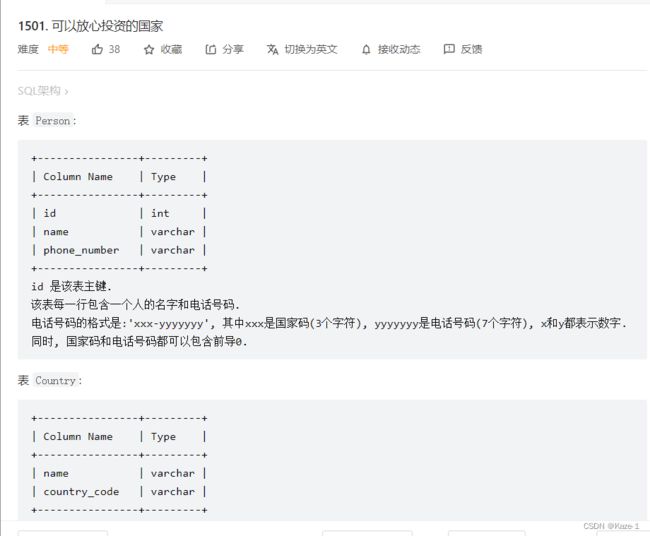
对于涉及多个不同结构的表的操作,思路最清晰明确的做法就是类似Pandas数据分析的思路,用WITH viewName AS (建立(多个)辅助表格,然后再用SELECT语句筛选
WITH
# 国家维度的通话时长
call_log AS (
-- caller所属国家的通话时长
SELECT a.caller_id AS id, a.duration, LEFT(b.phone_number,3) AS country_code
FROM calls a
LEFT JOIN person b ON a.caller_id=b.id
UNION ALL
-- callee所属国家的通话时长
SELECT a.callee_id AS id,a.duration, LEFT(b.phone_number,3) AS country_code
FROM calls a
LEFT JOIN person b ON a.callee_id=b.id
),
# 每个国家的平均通话时长
duration_avg_country AS (
SELECT country_code, SUM(duration)/COUNT(id) AS duration_avg
FROM call_log
group by country_code
)
# 选出平均通话时长大于全球平均通话时长的国家
SELECT b.name AS country
FROM duration_avg_country AS a
LEFT JOIN country AS b ON a.country_code=b.country_code
WHERE a.duration_avg>( SELECT sum(duration)/count(id) AS duration_all # 全球通话时长
FROM call_log )
这里按先后顺序使用了两个辅助表,一个是id-通话时间-所属国家的call_log, 另一个是在call_log基础上构建的每个国家的平均通话时长duration_avg_country, 在duration_avg_country基础上筛选即可得到答案(平均通话时长多于全球平均时长的国家)