《Visual C++ 2010入门教程》系列四:VC2010中初学者常见错误、警告和问题
这一章将帮助大家解释一些常见的错误、警告和问题,帮助大家去理解和解决一些常见问题,并了解它的根本原因。
iostream.h与<iostream>
下面的代码为什么在VC2010下面编译不过去?
#include <iostream.h>
int main()
{
cout<<"Hello World."<<endl;
return 0;
}
错误信息:fatal error C1083: 无法打开包括文件:“iostream.h”: No such file or directory
造成这个错误的原因在于历史原因,在过去C++98标准尚未订立的时候,C++的标准输入输出流确实是定义在这个文件里面的,这是C风格的定义方法,随着C++98标准的确定,iostream.h已经被取消,至少在VC2010下面是这样的,取而代之的是我们要用<iostream>头文件来代替,你甚至可以认为<iostream>是这样定义的:
namespace std
{
#include "iostream.h"
}
因此我们可以简单的修改我们的Hello World。
#include <iostream>
using namespace std;
int main()
{
cout<<"Hello World."<<endl;
return 0;
}
iostream.h是属于C++的头文件,而非C的,因此标准订立的时候被改成了<iostream>。而C的头文件stdio.h等依然可以继续使用,这是为了兼容C代码。但是它们依然有对应的C++版本,如<cstdio> <cstdlib>等。记住,在VC2010上面采用C++风格的头文件而不是C风格的头文件,除非你是在用C。
warning C4996
#include <iostream>
using namespace std;
int main()
{
char sz[128] = {0};
strcpy( sz, "Hello World!" );
cout<< sz << endl;
return 0;
}
上面的strcpy会产生这个警告:
warning C4996: 'strcpy': This function or variable may be unsafe. Consider using strcpy_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
这是因为VC从2005版本开始,微软引入了一系列的安全加强的函数来增强CRT(C运行时),这里对应的是strcpy_s。_s意为safe的意思,同样的道理,strcat也是同样。因此要解决这个问题,我们可以用strcpy_s来替换strcpy,但是注意strcpy_s并非所有编译器都提供,因此如果要跨编译器,请采用错误信息中所提示的方式,定义_CRT_SECURE_NO_WARNINGS宏来掩耳盗铃吧。另外注意并非所有的加强函数都是在屁股后面加_s,比如stricmp这个字符串比较函数的增强版名字是_stricmp。下面,用strcpy_s来更改程序:
int main()
{
char sz[128] = {0};
strcpy_s( sz, "Hello World!" );
cout<< sz << endl;
char* pSz2 = new char[128];
strcpy_s( pSz2, 128, "hello");
cout<< pSz2 << endl;
delete pSz2;
return 0;
}
注意,strcpy_s有两个版本,一个可以帮助我们自动推断缓冲区的大小,而另外一个不能帮助我们推断,因此在编译器不能推断缓冲区大小的时候,我们需要自己指定缓冲区的大小,如上面的程序所演示的那样,关于增强版的函数请参考我写的《深入学习C++ String2.1版》。
TCHAR、wchar_t、char
请大家看下面这个程序:
#include <iostream>
#include <Windows.h>
#include <tchar.h>
using namespace std;
int main()
{
MessageBox( NULL, "你好HelloWorld!", "Information", 0 );
return 0;
}
貌似没什么问题吧?错了,如果你是按照我教你的方法创建的控制台空工程的话,那么会有编译错误:
error C2664: “MessageBoxW”: 不能将参数 2 从“const char [17]”转换为“LPCWSTR”
这个问题太普遍了,几乎所有的初学者都会遇到而且感到难以应付,因为按照提示使用(LPCWSTR)强制转型貌似并不能帮助我们解决问题,而且这个程序在VC6下面应该是没有任何问题的,那问题出现在哪里呢?问题在这里,请右键单击解决方案浏览器下面的项目,属性,

问题的根本就是字符集问题,在VC6中,我们默认使用的是多字节字符集,而现在我们默认需要的是UNICODE字符集,简单的,我们把这个字符集改成多字节字符集这个问题就解决了:
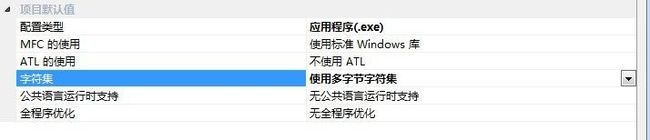
再试试应该就可以了吧?但是我并不推荐大家这么做,因为让自己的程序适应各种字符集是我们写代码的人义不容辞的义务。
我们把程序改成下面这样:
#include <iostream>
#include <Windows.h>
#include <tchar.h>
using namespace std;
int main()
{
MessageBox( NULL, TEXT("你好HelloWorld!"), TEXT("Information"), 0 );
MessageBox( NULL, _T("你好HelloWorld!"), _T("Information"), 0 );
return 0;
}
用两个宏TEXT或者_T都可以解决这个问题,它们两个并没有太大区别,也许区别在于前者是通过windows.h头文件引入的,而_T是通过tchar.h引入的,我推荐大家使用_T和tchar.h,因为tchar.h还帮助我们引入了其它一些很有用的宏,比如_tcscpy_s,这个宏在使用UNICODE字符集的时候被替换成wcscpy_s,在使用多字节字符集的使用被替换成strcpy_s。关于这部分的内容,请大家不要错过《Windows核心编程》的第二章(第四版或第五版都可以),以及《深入学习C++ String2.1版》。 它们都有提到。
有人听说_T可以把多字节字符串转换成UNICODE,因此他写了如下的代码:
const char* pStr = "haha哈哈";
MessageBox( NULL, _T(pStr), _T("Information"), 0 );
当然,除非你运气好的抓狂,否则你是编译不过去的,为什么呢?我们现在应该知道对于"Hello"这样的字符串,VC2010会默认的将它视为const char*,即多字节字符串,而L"Hello"前面有个L前缀的被视为UNICODE字符串,这和C#是有区别的,因为C#的字符串总是被视为UNICODE,C++/CLI下面编译器也会帮助我们做到这件事情,所以它们不需要L(C++/CLI兼容L这种写法)。
让我们看看_T的定义吧:
#define wxCONCAT_HELPER(text, line) text ## line
/* could already be defined by tchar.h (it's quasi standard) */
#ifndef _T
#if !wxUSE_UNICODE
#define _T(x) x
#else /* Unicode */
/* use wxCONCAT_HELPER so that x could be expanded if it's a macro */
#define _T(x) wxCONCAT_HELPER(L, x)
#endif /* ASCII/Unicode */
#endif /* !defined(_T) */
_T在UNICODE下面最终会被替换成L ## x。 ##是一个编译预处理指令,意味着让L和x贴在一起,比如L ## "Hello"最终就是L"Hello",因此它可以把"Hello"转换成UNICODE字符串。那为什么上面的程序不行呢?让我们看看_T("pStr")会被替换成什么:L ## pStr -> LpStr,哦,LpStr是一个新的标识符,如果你没有定义过它,你当然不能通过编译啦。
因此我们可以了解到_T这样的宏只能处理直接的常量字符串,不能处理其它的情况。而我们上面演示的那种情况需要我们动态的去转换编码,Windows有API可以帮助我们做到,C库也有函数可以帮助我们。恰好我曾经写过这样的代码,欢迎大家参考:ASCII/UNICODE/UTF8字符串互相转换的C++代码
对于_T宏,再说一点东西,或许你会感到奇怪为什么_T不直接定义成#define _T(x) L ## x,而要绕个圈子去调用wxCONCAT_HELPER呢?这实际上涉及到宏展开顺序和截断的问题。在这里,我们需要说一个宏参数的概念,这很函数的参数是类似的,这里_T(x)的x就是宏参数,好,记住下面一句话:
如果你定义的宏中使用了#或者是##的话,宏参数将不会被展开,也就是说_T(x)如果直接定义成L##x那么在下面这种情况就会出错( PS: #是给参数加引号的意思):
_T(__FUNCTION__),__FUNCTION__是一个预定义的宏,它代表了当前函数的名字,这个展开会是什么呢?L__FUNCTION__。为什么间接调用wxCONCAT_HELPER就能得到正确的结果呢?因为当我们调用wxCONCAT_HELPER的时候,__FUNCTION__已经被_T展开成了函数名。
说多了说多了,如果你觉得复杂可以暂时跳过这些东西,我只是顺便说说。
重定义的编译错误和链接错误
让我们在项目里面再添加一个Test.h头文件,方法是右击解决方案中的项目,添加,新建项,C++头文件,名称输入test.h。然后我们在test.h中输入:
/*#pragma once*/
void print()
{
}
回到main.cpp中:
#include <iostream>
using namespace std;
#include "Test.h"
#include "Test.h"
int main()
{
return 0;
}
编译一下我们会得到重定义的编译错误:
error C2084: 函数“void print(void)”已有主体
或许你会说,你引用(#include)了两次,我没你那么傻,我只引用一次不就好了么?是的。你聪明,但是是小聪明哈,因为你不能保证每个人都不去引用它。
这个问题演示的是#pragma once的用处,让我们解开它的注释。编译成功!#pragma once的作用就在于防止头文件被多次引用。你或许见过
#ifndef __TEST_H__
#define__TEST_H__
代码
#endif
这样的代码,它们的作用是一样的,如果你跟我一样懒,那么就用#pragma once,如果你打算去没有这个指令的编译器上编译代码,那么还是用后面一种方式吧。
现在让我们来见识一个对初学者稍微复杂一点的链接错误,用创建main.cpp的方法再添加一个test.h头文件,输入#include "Test.h"即可。

让我们再编译一次。
1>test.obj : error LNK2005: "void __cdecl print(void)" (?print@@YAXXZ) 已经在 Main.obj 中定义
1>e:\documents\visual studio 2010\Projects\HelloWorld\Debug\HelloWorld.exe : fatal error LNK1169: 找到一个或多个多重定义的符号
如果说编译错误好找的话,链接错误对于初学者来说就有点麻烦了,聪明的初学者会去Google、百度寻找答案,笨的初学者就会找所谓的高手、前辈问,而这些高手Or前辈未必有心情为你解释。要解决这个错误有无数种方法。
1.内联,把print声明为内联函数。
inline void print()
{
}
这个方法的好处是简单,坏处是局限性太强,意味着你总是需要公开print的实现,因为内联函数必须在编译时就知道实现才行。
2.static,把print声明为static函数:
static void print()。
这便告诉编译器,哥是唯一的,而且哥只能被本编译单元的代码调用,这和extern是对应的。简单来说,想要哥帮你做事,请先include哥声明的头文件,也就是#include "test.h"。
3..h头文件中只放声明,实现放到.cpp中去。
现在test.h中只有void print();,而实现在test.cpp中:
#include "Test.h"
void print()
{
int a = 1;
cout<< a++ << endl;
}
这个时候有意思的是我们在main.cpp无需包含test.h头文件也可以引用print函数,因为print并非static的函数:
void print();
int main()
{
print();
print();
return 0;
}
但是声明一下是必须的。
由于百度空间的帖子的篇幅是有限制的,因此今天只好就说这么几点了。新的内容请大家等候下一章。