Unsupervised Pixel–Level Domain Adaptation with Generative Adversarial Networks(小白学GAN 十二)
原文链接:https://arxiv.org/pdf/1612.05424.pdf
简介
背景:目前很多基于监督的学习方法成功的关键都是大量的数据,然而实际中去收集足够样本是困难的。于是,生成数据样本是一种可取的方案,本文就是使用GAN来将一个域中的数据转化到另一个域中。
核心思路:将已有的源数据以随机噪声为条件的情况下一同输入生成器生成新的数据,并将此数据通过判别器来分辨真伪,并通过T 网络进行训练。
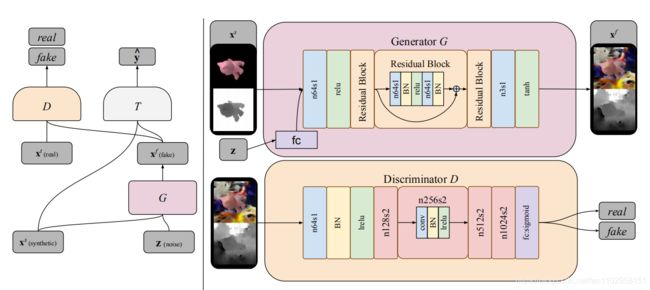
基础结构
优化目标LOSS

由上述所示,优化函数由两部分组成,一部分是传统的GAN的Discriminator Loss,后一部分是数据与任务网络的Loss(即常规的深度学习任务的loss),其具体可以表示未为下:
![]()
![]()
作者在文中使用的是背景生成的实验,在上面的基础上又加上内容相似损失,来规范生成图片的内容。
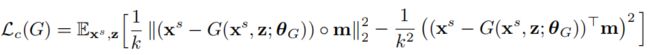
这种损失使模型能够学习重现要建模的对象的整体形状,而不会在输入的绝对颜色或强度上浪费建模能力,同时又使我们的对抗训练得以以一致的方式更改对象。 请注意,损失并不会阻止前景改变,而是会鼓励前景以一致的方式发生变化。 在这项工作中,由于数据的性质,文中对单个前景对象应用了蒙版的PMSE损失,但是可以将其微不足道地扩展到多个前景对象。
最终,优化目标函数表示为:
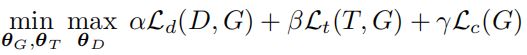
网络结构
生成网络:引入了resblock的结构,在输入端时首先将噪声z通过fc层扩张为CxHxW的维度,并reshape成图片形状,再与原图在通道维度上拼接起来,再过卷积层。
判别模型:与常见的判别网络结构类似,没有什么不同。
任务模型:文中没有给出具体的模型结构,模型的具体选用也是根据具体的任务所定的。
代码与实践结果
参考链接:
from __future__ import print_function
import errno
import os
import torch
import torch.utils.data as data
from PIL import Image
class MNISTM(data.Dataset):
"""`MNIST-M Dataset."""
url = "https://github.com/VanushVaswani/keras_mnistm/releases/download/1.0/keras_mnistm.pkl.gz"
raw_folder = 'raw'
processed_folder = 'processed'
training_file = 'mnist_m_train.pt'
test_file = 'mnist_m_test.pt'
def __init__(self,
root, mnist_root="data",
train=True,
transform=None, target_transform=None,
download=False):
"""Init MNIST-M dataset."""
super(MNISTM, self).__init__()
self.root = os.path.expanduser(root)
self.mnist_root = os.path.expanduser(mnist_root)
self.transform = transform
self.target_transform = target_transform
self.train = train # training set or test set
if download:
self.download()
if not self._check_exists():
raise RuntimeError('Dataset not found.' +
' You can use download=True to download it')
if self.train:
self.train_data, self.train_labels = \
torch.load(os.path.join(self.root,
self.processed_folder,
self.training_file))
else:
self.test_data, self.test_labels = \
torch.load(os.path.join(self.root,
self.processed_folder,
self.test_file))
def __getitem__(self, index):
"""Get images and target for data loader.
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
if self.train:
img, target = self.train_data[index], self.train_labels[index]
else:
img, target = self.test_data[index], self.test_labels[index]
# doing this so that it is consistent with all other datasets
# to return a PIL Image
img = Image.fromarray(img.squeeze().numpy(), mode='RGB')
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
def __len__(self):
"""Return size of dataset."""
if self.train:
return len(self.train_data)
else:
return len(self.test_data)
def _check_exists(self):
return os.path.exists(os.path.join(self.root,
self.processed_folder,
self.training_file)) and \
os.path.exists(os.path.join(self.root,
self.processed_folder,
self.test_file))
def download(self):
"""Download the MNIST data."""
# import essential packages
from six.moves import urllib
import gzip
import pickle
from torchvision import datasets
# check if dataset already exists
if self._check_exists():
return
# make data dirs
try:
os.makedirs(os.path.join(self.root, self.raw_folder))
os.makedirs(os.path.join(self.root, self.processed_folder))
except OSError as e:
if e.errno == errno.EEXIST:
pass
else:
raise
# download pkl files
print('Downloading ' + self.url)
filename = self.url.rpartition('/')[2]
file_path = os.path.join(self.root, self.raw_folder, filename)
if not os.path.exists(file_path.replace('.gz', '')):
data = urllib.request.urlopen(self.url)
with open(file_path, 'wb') as f:
f.write(data.read())
with open(file_path.replace('.gz', ''), 'wb') as out_f, \
gzip.GzipFile(file_path) as zip_f:
out_f.write(zip_f.read())
os.unlink(file_path)
# process and save as torch files
print('Processing...')
# load MNIST-M images from pkl file
with open(file_path.replace('.gz', ''), "rb") as f:
mnist_m_data = pickle.load(f, encoding='bytes')
mnist_m_train_data = torch.ByteTensor(mnist_m_data[b'train'])
mnist_m_test_data = torch.ByteTensor(mnist_m_data[b'test'])
# get MNIST labels
mnist_train_labels = datasets.MNIST(root=self.mnist_root,
train=True,
download=True).train_labels
mnist_test_labels = datasets.MNIST(root=self.mnist_root,
train=False,
download=True).test_labels
# save MNIST-M dataset
training_set = (mnist_m_train_data, mnist_train_labels)
test_set = (mnist_m_test_data, mnist_test_labels)
with open(os.path.join(self.root,
self.processed_folder,
self.training_file), 'wb') as f:
torch.save(training_set, f)
with open(os.path.join(self.root,
self.processed_folder,
self.test_file), 'wb') as f:
torch.save(test_set, f)
print('Done!')
import argparse
import os
import numpy as np
import math
import itertools
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from mnistm import MNISTM
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--n_residual_blocks", type=int, default=6, help="number of residual blocks in generator")
parser.add_argument("--latent_dim", type=int, default=10, help="dimensionality of the noise input")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=3, help="number of image channels")
parser.add_argument("--n_classes", type=int, default=10, help="number of classes in the dataset")
parser.add_argument("--sample_interval", type=int, default=300, help="interval betwen image samples")
opt = parser.parse_args()
print(opt)
# Calculate output of image discriminator (PatchGAN)
patch = int(opt.img_size / 2 ** 4)
patch = (1, patch, patch)
cuda = True if torch.cuda.is_available() else False
def weights_init_normal(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
torch.nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find("BatchNorm") != -1:
torch.nn.init.normal_(m.weight.data, 1.0, 0.02)
torch.nn.init.constant_(m.bias.data, 0.0)
class ResidualBlock(nn.Module):
def __init__(self, in_features=64, out_features=64):
super(ResidualBlock, self).__init__()
self.block = nn.Sequential(
nn.Conv2d(in_features, in_features, 3, 1, 1),
nn.BatchNorm2d(in_features),
nn.ReLU(inplace=True),
nn.Conv2d(in_features, in_features, 3, 1, 1),
nn.BatchNorm2d(in_features),
)
def forward(self, x):
return x + self.block(x)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# Fully-connected layer which constructs image channel shaped output from noise
self.fc = nn.Linear(opt.latent_dim, opt.channels * opt.img_size ** 2)
self.l1 = nn.Sequential(nn.Conv2d(opt.channels * 2, 64, 3, 1, 1), nn.ReLU(inplace=True))
resblocks = []
for _ in range(opt.n_residual_blocks):
resblocks.append(ResidualBlock())
self.resblocks = nn.Sequential(*resblocks)
self.l2 = nn.Sequential(nn.Conv2d(64, opt.channels, 3, 1, 1), nn.Tanh())
def forward(self, img, z):
gen_input = torch.cat((img, self.fc(z).view(*img.shape)), 1)
out = self.l1(gen_input)
out = self.resblocks(out)
img_ = self.l2(out)
return img_
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
def block(in_features, out_features, normalization=True):
"""Discriminator block"""
layers = [nn.Conv2d(in_features, out_features, 3, stride=2, padding=1), nn.LeakyReLU(0.2, inplace=True)]
if normalization:
layers.append(nn.InstanceNorm2d(out_features))
return layers
self.model = nn.Sequential(
*block(opt.channels, 64, normalization=False),
*block(64, 128),
*block(128, 256),
*block(256, 512),
nn.Conv2d(512, 1, 3, 1, 1)
)
def forward(self, img):
validity = self.model(img)
return validity
class Classifier(nn.Module):
def __init__(self):
super(Classifier, self).__init__()
def block(in_features, out_features, normalization=True):
"""Classifier block"""
layers = [nn.Conv2d(in_features, out_features, 3, stride=2, padding=1), nn.LeakyReLU(0.2, inplace=True)]
if normalization:
layers.append(nn.InstanceNorm2d(out_features))
return layers
self.model = nn.Sequential(
*block(opt.channels, 64, normalization=False), *block(64, 128), *block(128, 256), *block(256, 512)
)
input_size = opt.img_size // 2 ** 4
self.output_layer = nn.Sequential(nn.Linear(512 * input_size ** 2, opt.n_classes), nn.Softmax())
def forward(self, img):
feature_repr = self.model(img)
feature_repr = feature_repr.view(feature_repr.size(0), -1)
label = self.output_layer(feature_repr)
return label
# Loss function
adversarial_loss = torch.nn.MSELoss()
task_loss = torch.nn.CrossEntropyLoss()
# Loss weights
lambda_adv = 1
lambda_task = 0.1
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
classifier = Classifier()
if cuda:
generator.cuda()
discriminator.cuda()
classifier.cuda()
adversarial_loss.cuda()
task_loss.cuda()
# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)
classifier.apply(weights_init_normal)
# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader_A = torch.utils.data.DataLoader(
datasets.MNIST(
"../../data/mnist",
train=True,
download=True,
transform=transforms.Compose(
[transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
os.makedirs("../../data/mnistm", exist_ok=True)
dataloader_B = torch.utils.data.DataLoader(
MNISTM(
"../../data/mnistm",
train=True,
download=True,
transform=transforms.Compose(
[
transforms.Resize(opt.img_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
),
),
batch_size=opt.batch_size,
shuffle=True,
)
# Optimizers
optimizer_G = torch.optim.Adam(
itertools.chain(generator.parameters(), classifier.parameters()), lr=opt.lr, betas=(opt.b1, opt.b2)
)
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensor
# ----------
# Training
# ----------
# Keeps 100 accuracy measurements
task_performance = []
target_performance = []
for epoch in range(opt.n_epochs):
for i, ((imgs_A, labels_A), (imgs_B, labels_B)) in enumerate(zip(dataloader_A, dataloader_B)):
batch_size = imgs_A.size(0)
# Adversarial ground truths
valid = Variable(FloatTensor(batch_size, *patch).fill_(1.0), requires_grad=False)
fake = Variable(FloatTensor(batch_size, *patch).fill_(0.0), requires_grad=False)
# Configure input
imgs_A = Variable(imgs_A.type(FloatTensor).expand(batch_size, 3, opt.img_size, opt.img_size))
labels_A = Variable(labels_A.type(LongTensor))
imgs_B = Variable(imgs_B.type(FloatTensor))
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Sample noise
z = Variable(FloatTensor(np.random.uniform(-1, 1, (batch_size, opt.latent_dim))))
# Generate a batch of images
fake_B = generator(imgs_A, z)
# Perform task on translated source image
label_pred = classifier(fake_B)
# Calculate the task loss
task_loss_ = (task_loss(label_pred, labels_A) + task_loss(classifier(imgs_A), labels_A)) / 2
# Loss measures generator's ability to fool the discriminator
g_loss = lambda_adv * adversarial_loss(discriminator(fake_B), valid) + lambda_task * task_loss_
g_loss.backward()
optimizer_G.step()
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Measure discriminator's ability to classify real from generated samples
real_loss = adversarial_loss(discriminator(imgs_B), valid)
fake_loss = adversarial_loss(discriminator(fake_B.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# ---------------------------------------
# Evaluate Performance on target domain
# ---------------------------------------
# Evaluate performance on translated Domain A
acc = np.mean(np.argmax(label_pred.data.cpu().numpy(), axis=1) == labels_A.data.cpu().numpy())
task_performance.append(acc)
if len(task_performance) > 100:
task_performance.pop(0)
# Evaluate performance on Domain B
pred_B = classifier(imgs_B)
target_acc = np.mean(np.argmax(pred_B.data.cpu().numpy(), axis=1) == labels_B.numpy())
target_performance.append(target_acc)
if len(target_performance) > 100:
target_performance.pop(0)
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f] [CLF acc: %3d%% (%3d%%), target_acc: %3d%% (%3d%%)]"
% (
epoch,
opt.n_epochs,
i,
len(dataloader_A),
d_loss.item(),
g_loss.item(),
100 * acc,
100 * np.mean(task_performance),
100 * target_acc,
100 * np.mean(target_performance),
)
)
batches_done = len(dataloader_A) * epoch + i
if batches_done % opt.sample_interval == 0:
sample = torch.cat((imgs_A.data[:5], fake_B.data[:5], imgs_B.data[:5]), -2)
save_image(sample, "images/%d.png" % batches_done, nrow=int(math.sqrt(batch_size)), normalize=True)
minst to minstm实验结果
可以看到的几次迭代之后,生成图片的背景明显多样花了,且前景的模式没有受到干扰。