cross_domain_adaptation
Feature Transformation Ensemble Model with Batch Spectral Regularization for Cross-Domain Few-Shot Classification

setup: source with data and label; target with data and no label
3 works:
Construct an ensemble prediction model by performing diverse feature transformations after a feature extraction network
1. a batch spectral regularization (BSR) mechanism: suppress all the singular values of the feature matrix in pre-training so that the pre-trained model can avoid overfitting to the source domain and generalize well to the target domain
2. feature transformation ensemble model: build multiple predictors in projected diverse feature spaces to facilitate cross-domain adaptation and increase prediction robustness
3. to mitigate the shortage of labeled data in the target domain:
- exploit the unlabeled query set in fine-tuning through entropy minimization
- label propagation (LP) step to refine the original classification results
Y ∗ = ( I − α L ) − 1 × Y ^ 0 Y^{*}=(I-\alpha L)^{-1} \times \hat{Y}^{0} Y∗=(I−αL)−1×Y^0 - data augmentation techniques to augment both the few-shot and test instances from different angles to improve prediction performance
others:
penalizing smaller singular values of a feature matrix can help mitigate negative transfer in fine-tuning
?
为什么要让feature*不同的正交矩阵得到multiple diverse feature representation spaces
(1)算法的效果很好,但是使用了太多的方法(这些方法之间又没有什么联系),又没做ablation study,说不清楚到底是哪种方法起到了效果。
(2)与第一篇文章一样,这篇文章也是对输入进行了特征变换。这篇文章则采用了新的变换方式。那么,找到一个好的变换方式是很有必要的。好的变换方式包括
Cross-domain Self-supervised Learning for Domain Adaptation with Few Source Labels


setup: source with data and little label; target with data and no label
related
Some semi-supervised learning techniques such as entropy minimization [9], pseudo-labeling [16], and Virtual Adversarial Training (VAT) [21] have been often used in domain adaptation (e.g., [17,31,44]).
domain adaptation methods such as [7,18,31] with few source labels.
Prior work accomplished this by using an adversarial domain classifier [7]
or Mean Maximum Discrepancy [19] to align two domain feature distributions. Optimal transport [38] is often used to find a matching pair of two distributions, but this scales poorly [4] and is limited to find a matching in a batch [1]
main idea
learns features that are not only domain-invariant but also class-discriminative
work
captures apparent visual similarity with in-domain self- supervision in a domain adaptive manner and performs cross-domain feature matching with across-domain self-supervision.
Our CDS consists of two objectives: (1) learning visual similarity with in-domain supervision and (2) cross-domain matching with across-domain supervision.
in-domain self-supervision encourages a model to learn discriminative features by separating every instance within a domain
- Instance Discrimination [39] (ID) : treating all the other images as negative pairs
- measure the similarity of features in-domain, and then perform in-domain instance discrimination to learn visual similarity in each domain
across-domain self-supervision enables better knowledge transfer from the source do- main to the target domain by performing instance-to-instance matching across domains.
- measure similarity between a feature and cross-domain features from the cross-domain memory bank and then minimize the entropy for cross-domain matching
the source and target memory banks
other
和某一篇DG文章好像,同时两个network,一个拉远一个拉近。不过加了self-supervised和不一样的setting
Cross-Domain Few-Shot Learning with Meta Fine-Tuning
在解决corss domain few-shot learning问题时,模型要在新domain的task上做微调,作者希望找到一组适合进行微调的初始化权重。
为此,作者使用元学习的方法进行训练,得到了meta fine-tuning模型。
explore the integration of transfer-learning (fine-tuning) with meta- learning algorithms, to train a network that has specific lay- ers that are designed to be adapted at a later fine-tuning stage
main idea
modify the episodic training process to include a first-order MAML-based meta-learning algorithm, and use a Graph Neural Network model as the subse- quent meta-learning module to compare the feature vectors.
work
meta fine-tuning的框架采用MAML,共分为两步
(1)微调
使用support set的数据对模型进行微调(只微调最后k层,这是迁移学习的习惯)(step1)
(2)根据微调做预测
对于微调后的模型,使用query set的数据进行预测,计算损失函数,反向传播,更新原模型的参数。(step2)
重复这两步,模型将学会一组初始化参数。这组参数在新任务上进行微调后,会取得比较好的效果。
relevant
Graph-based convolutions can create more flexible representations of data beyond a simple Eu- clidean space [1].
other
不是很有价值
Cross-domain few-shot classification via learned feature-wise transformation
main idea
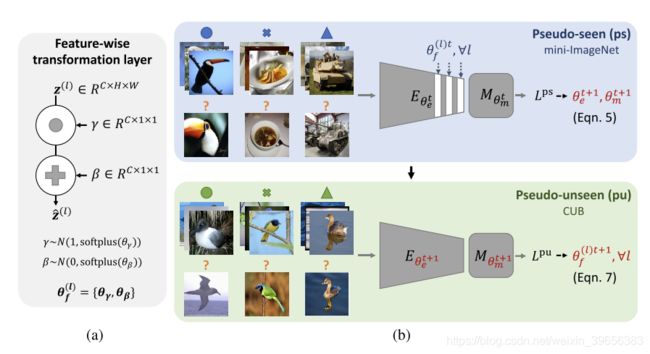
use feature-wise transformation layers for augmenting the image features using affine transforms to simulate various feature distributions under different domains in the training stage.
tackle the domain generalization problem for recognizing novel category in the few-shot classification setting
work
- feature-wise transformation layers
- learning-to learn method to optimize the hyper-parameters of FT layers
(1)先取若干个domain(即若干个数据集,论文选了五个)
(2)从中选择一个作为unseen domain,其余作为seen domain
(3)针对传统的protonet进行微小改进,在所有层的batch normalization操作后面加入FT操作(如下图)
(4)在seen domain上计算损失,反向传播,更新除FT操作外的所有参数(下图中的θe和θm)
(5)去掉FT操作
(6)在unseen domain上计算损失,反向传播,专门更新FT操作的参数(下图中的θf)
?
问题
(1)为什么训练的时候要在unseen task上去掉FT操作?
我认为:如果去掉FT操作,就是让源域向目标域靠近;如果不去掉FT操作,就是既让源域向目标域靠近,又让目标域向源域靠近。
但是作者的出发点并不是让源域和目标域相互靠近(虽然实际上就是达到了这个效果),他的目标是让源域的图片特征更加多种多样,从而避免过拟合。因而当目标域的数据送入模型,是没有必要让它的特征也多种多样的。
思考:如果不去掉FT操作,也许我们可以让源域和目标域互相靠近,也许效果会更好。
(2)为什么不在源域就更新FT操作的参数?
因为FT操作是为目标域服务的,只有在目标域上才能判断FT有没有解决过拟合能力。
(3)作者提出的更新FT参数的方法是否合理?
作者在unseen task上去掉了FT操作,却又通过unseen task上的损失更新FT的参数,并且更新函数简单粗暴。
所以这个方法并不是特别有道理,应该找个更reasonable的方法。
收获
(1)对于任何需要超参数的方法,都可以试着使用元学习的方法学出来一组合适的超参数
(2)作者不是让模型从一个域迁移到另一个域,而是采用了元学习方法,从很多个域迁移到另一个域,从而实现了学会迁移。
related
metric-based meta-learning meth- ods (Garcia & Bruna, 2018; Sung et al., 2018; Vinyals et al., 2016; Snell et al., 2017; Oreshkin et al., 2018) have received considerable attention due to their simplicity and effectiveness.
few-shot, DA, DG, data augmentation, conditional normalization, regularization
Large Margin Mechanism and Pseudo Query Set on Cross-Domain Few-Shot Learning
work
-
First, we propose the pseudo query set and analyze its importance.
生成伪query set以微调模型
在meta-test阶段,对每个support set中的图像进行data augmentation,生成多个伪query set图像(这些图像是有标签的,标签就是数据增强前的图片标签)。使用伪query set集,few-shot模型可以在微调阶段更新参数,就像它们在meta-training阶段对普通查询集所做的那样。 -
用triplet loss改进原来的prototypical net
原来的protonet的目标是让相同的类靠近它们的原型(prototype/中心点)。
作者使用triplet loss,将同一类的数据拉到更接近其原型的地方,并拉大这些数据与其它类的原型之间的距离,损失函数变为下式
P T P T PT Loss = ∑ i = 1 N × K ∑ j = 1 N ( c s i ≠ j ) =\sum_{i=1}^{N \times K} \sum_{j=1}^{N}\left(c_{s_{i}} \neq j\right) =∑i=1N×K∑j=1N(csi=j) triplet ( s i , p c s i , p j ) \left(s_{i}, p_{c_{s_{i}}}, p_{j}\right) (si,pcsi,pj) -
Large margin mechanism
作者进一步使用了large margin mechanism,增大了分类器的判别能力。
(这一方法多用于人脸识别,作者认为人脸识别与meta learning的任务设定有相似性)
根据前面的分析, 如果 ∣ w 1 ∣ ∣ x ∣ cos ( θ 1 ) > ∣ w 2 ∣ ∣ x ∣ cos ( θ 2 ) , \left|w_{1}\right||x| \cos \left(\theta_{1}\right)>\left|w_{2}\right||x| \cos \left(\theta_{2}\right), ∣w1∣∣x∣cos(θ1)>∣w2∣∣x∣cos(θ2), softmax 就将特征 x x x 判为类别1。因此, 在训练过程中,我们可以根据样本标签, 通过减小 cos ( θ ) \cos (\theta) cos(θ) 人为增加判别难度, 判别 条件变成 (若 x x x 属于类别1):
∣ w 1 ∣ ∣ x ∣ cos ( m θ 1 ) > ∣ w 2 ∣ ∣ x ∣ cos ( θ 2 ) \left|w_{1}\right||x| \cos \left(m \theta_{1}\right)>\left|w_{2}\right||x| \cos \left(\theta_{2}\right) ∣w1∣∣x∣cos(mθ1)>∣w2∣∣x∣cos(θ2)
夹角变大增加了训练难度,迫使样本远离最初的决策边界,同时类内更加聚拢。类别之间新的决策边界如下
other
(1)作者显示用数据增强生成伪标签,又辅助两种增加分类器判别能力的方法,取得了良好的效果。但是不知道到底是那种机制起作用.
(2)除了生成伪标签,对于5-way 5-shot任务,也许我们可以把4shot作为support set,把1way作为query set更新参数。
related
Y. Guo, N. C. F. Codella, L. Karlinsky, J. R Smith, T. Rosing, and R. Feris. A new benchmark for evaluation of cross-domain few-shot learning. arXiv preprint arXiv:1912.07200, 2019.
Self-Supervised Prototypical Transfer Learning for Few-Shot Classification
set up
support set 没有标签
这篇文章指出:supprot set过少的数据(过小的batch size)是产生过拟合的原因
想办法增大batch size是关键
这篇文章增大batch size的方法还很一般(简单的data augmentation,别人去年已经用过了),还有待新的创新。
related
However, several works (Chen et al., 2019; Guo et al., 2019) show that common (non-episodical) transfer learning outperforms meta-learning methods on the realistic cross-domain setting, where training and novel classes come from different distributions.
unsupervised meta-learning approaches, constructing episodes via pseudo-labeling (Hsu et al., 2019; Ji et al., 2019) or image augmentations (Khodadadeh et al., 2019; Antoniou and Storkey, 2019; Qin et al., 2020), have addressed this problem.
In this, we draw inspiration from recent progress in unsupervised meta-learning (Khodadadeh et al., 2019) and self-supervised visual contrastive learning of representations (Chen et al., 2020; Ye et al., 2019).