C/C++ Primer Plus读书与VsCode实践笔记(二)
前言
昨天在阅览了相关的C++学习资料后,决定重头再学一遍C语言,由于之前已经学过了,所以可能会比较捡重点或者笔者不太明白的点。
由于前面的部分比较类似,包括C++/C在VScode中的配置也是大差不差,所以这里就不再赘述。直接在C语言中接着上一章的部分。
昨天写了一个简单的C++程序例子,并解析了函数的构成以及函数头的作用和地位以及部分用法。那么今天将从函数体开始解析。
函数体
函数体的内容里除了一些编程规范以外比较需要注意的部分是声明语句,即类似
int a=1; String b=“abc”;
以上的例子声明两件事情。第一,在函数中有一个已经定义名字的变量,第二,如果是int说明num是一个整数,也就是说这个数没有小数部分(int是C语言的一种数据类型)。
编译器使用这个信息为变量num在内存中分配一个合适的存储空间。句末的分号指明这一行是C语言的一个语句或指令,分号是语句的一部分,每个C语言都以一个分号结束。
至于昨天代码里的
cout<<"welcome to the C++ world!";
这一句是C++的输出函数的标准格式,如果在C或Java中一般以printf()或者System.out.println()为主。
在官方的输出函数示例中引入了一个概念**“\n”**,它在打印的时候意义是换行。
转义字符
换行符是转义字符(Escape Sequence)的一个例子。转义字符通常用于代表难于表达的或是无法键入的字符。其他的例子比如 \t 代表 Tab键, \b 代表退格键盘。每个转义字符都用斜线字符(\)开始。

return0则和函数的定义有关,因为本例定义了函数类型是int,所以就意味着main函数需要返回一个整数值,所以就需要返回一个整形变量作为返回的量。
在结束了函数体的部分后,那么下面将开始的是关于数据的基本知识学习。
数据类型和关键字
C语言的基本数据类型为:整型、字符型、实数型。这些类型按其在计算机中的存储方式可被分为两个系列,即整数(integer)类型和浮点数(floating-point)类型。 同时也分为signed和unsigned(有无符号数)。
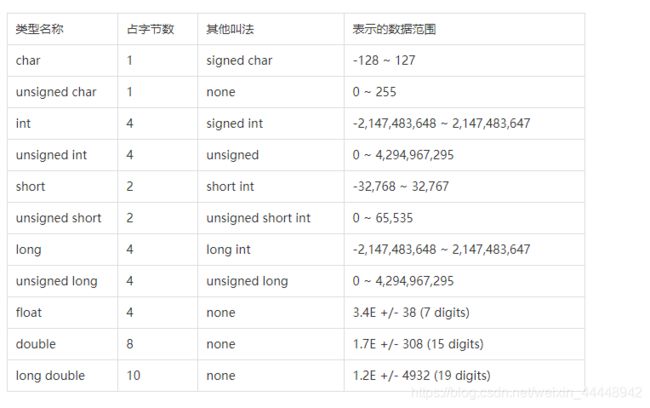
这里需要注意每个数据类型所占的字节数也是不同的,这意味着在内存中为他们分配的存储空间以及它们的表示范围也是不同的。
关键字

关键字可以理解为C语言中已经定义好且不允许再定义的函数。
格式化输出函数printf()
顾名思义 格式化输出,即功能是按照用户指定的格式,把指定的数据输出到屏幕上。

格式控制字符串有两种:格式字符串和非格式字符串。
非格式字符串在输出的时候原样打印;
格式字符串是以%*d打头的字符串,在”%”后面跟不同格式字符,用来说明输出数据的类型、形式、长度、小数位数等。
格式字符串的形式为: % [输出最小宽度] [.精度] [长度] 类型 。(示例%5.2f 格式表示输出宽度为5(包括小数点),并包含2位小数。)
printf()中的两种错误处理机制(throw execption):
一、读取参量错误
例如printf("/%d,%d,%d",a)后两个%d都没有被赋值,所以会输出内存中的随机数。
二、printf函数的返回值是返回所打印的字符的数目。如有输出错误,那么printf()会返回一个负数(printf()的一些老版本会有不同的值)。
修饰符在printf()中的用法:
假如您不想事先指定字段宽度,而是希望由程序来制定该值,那么您可以在字段宽度部分使用*代替数字来达到目的,但是您也必须使用一个参数来告诉函数宽度的值是多少。具体的说,如果转换说明符为%d,那么参数列表中应该包括一个的值和一个d的值,来控制宽度和变量的值
格式化输入函数scanf
scanf函数称为格式输入函数,即按照格式字符串的格式,从键盘上把数据输入到指定的变量之中。Scanf函数的调用的一般形式为:
scanf(“格式控制字符串”,输入项地址列表);
其中,格式控制字符串的作用与printf函数相同。
需要注意的是
(1)scanf()不能显示非格式字符串,也就是不能显示提示字符串。
(2) 格式说明符中,可以指定数据的宽度,但不能指定数据的精度。
(3) 输入long类型数据时必须使用%ld,输入double数据必须使用%lf或%le。
(4) 附加格式说明符”*”使对应的输入数据不赋给相应的变量。
scanf()中的错误(throw execption):
scanf() 函数返回成功读入的项目的个数。如果它没有读取任何项目(比如它期望接收一个数字而您却输入的一个非数字字符时就会发生这种情况),scanf()返回0。
当它检测到“文件末尾”(end of file)时,它返回EOF(EOF在是文件stdio.h中的定义好的一个特殊值,一般,#define指令将EOF的值定义为-1)。
一个编程练习
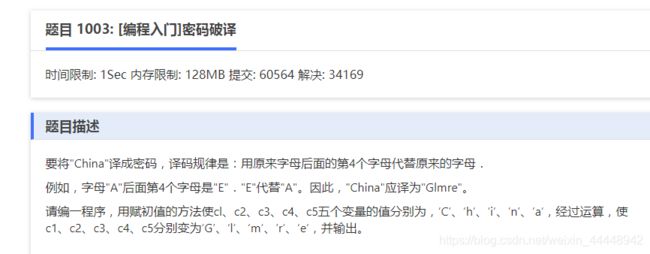
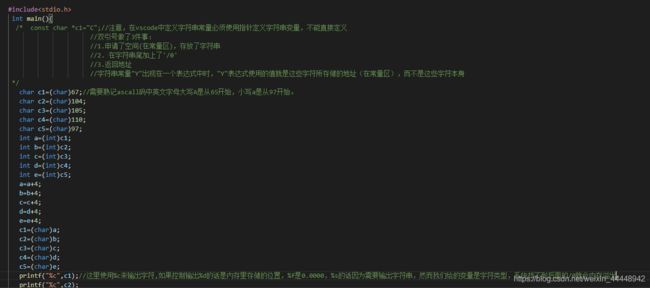
没想到作为一个编程两年的练习生,这里也踩了一些坑,例如在vscode和c语言中赋字符常量是不能直接用char x="abc "的,而是应该使用单引号或者直接数字(这也是不好的编程方式)的方式,并且用双引号赋值再用int转换类型获得数值的话获得的将是指针的地址。其他坑具体的细节在注释中也都标注了。这里其实涉及了两个知识点,字符常量和字符串,现在先简单的理解为单引号为字符常量,双引号为字符串,字符常量一般只有一个字节。
运算符和表达式
基本运算符
需要注意的是数字运算符以及%取模
自增:++ 自减: –
双目运算符:需要两个操作数
取模 ![]()
sizeof运算符
sizeof是C语言的32个关键字之一,并非“函数”(我们会后面介绍),也叫长度(求字节)运算符,sizeof是一种单目运算符,以字节为单位返回某操作数的大小,用来求某一类型变量的长度。其运算对象可以是任何数据类型或变量。
三目运算符
C语言当中唯一一个三目运算符:选择运算符
格式:表达式1?表达式2:表达式3
表达式1成立,返回表达式2,不成立,返回表达式3。
一些其他收获
断点的使用
什么是断点?就是程序停止、断开的一个位置。断点的目的是为了追溯程序的执行过程,跟踪程序的动态执行过程,从而排查错误来解决问题。
主要参考的是VC6的一个攻略,实践的话还是在VsCode里弄的,懒得再配环境了。
https://www.dotcpp.com/wp/563.html
这里特别记录一下以下几个技术以及几段话:
监视变量
一点os:这个东西以前自己的实现都靠通过函数输出变量到后台,也太蠢了。原来我自己以前千方百计设计的局部检验程序的方式,早就有更完善的手段和方法了。。。果然语言开发学习不能为了图快舍近求远忽略很多基本的技术细节,不然只会遗漏的越来越多,并且都一知半解,应当一步一个脚印,逐步学习,认真掌握。
回头说下变量监视,前面提到了断点就是为了追溯程序的执行过程,那么变量监视就可以很好的帮助我们从自己定义的变量的变化的角度来看自己所写的程序执行过程。(作为一个两年练习生真的表示实用性拉满)。话不多说,让我们来看看实例吧,用F5进入调试模式然后F10逐步执行前面那个代码可以在vscode中的变量栏里清晰的看到定义的几个变量的变化,如果仔细观察的话也可以轻易的越过刚刚那个指针定义变量传递的是内存的坑。(所以内存监视其实也是一个很好的技术学习手段)
运行前
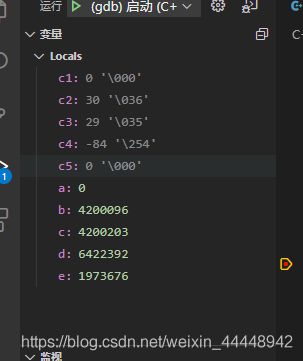
运行后

实际上操作会更有观感,因为vscode中是以一种动画的方式表示变量的变动的,实际更为清晰和明白。
条件断点
这个也比较好理解,前面说了断点即程序在调试时中断执行的点,那么条件断点就是除了在那句语句的位置停之外加上一个限定条件。例如判别式,可以是bool类型的值为真,也可以是某一个表达式或函数变量满足既定条件,VsCode中条件断点只需要右键断点就可以选择编辑断点输入表达式并且在断点语句下显示。一般条件断点是在循环或者比较多的代码中打断点使用,因为这时候一般不会使用逐步执行检查断点的方式,那样工作量过于庞大,可以使用条件断点来测试该语句与自己的预期有没有出入,如果有出入的话就停下也可以方便的检验。

内存监视
由于vscode中没有支持vs中的直接查看内存(所以这里又踩坑了,应该配个VS的不知道明天有没有心情配吧),Vscode中的监视是通过在左侧的监视栏输入自己想要监视的值,随后可以在调试控制台中看到自己这个语句在断点处的执行情况。

这里两句的意思是输出变量str1和str2的内存情况(各自两行),可以看到在strcpy函数执行后,str1在内存中存放的数据(从第一列以后)被str2覆盖了。

一个实战练习

错误代码

通过打断点的方式发现输入的f的值出现了错误,从而考虑scanf()函数的使用格式是不是有问题,进而解决。

程序的编译以及链接
编译器能够识别代码中的词汇、句子以及各种特定的格式,并将他们转换成计算机能够识别的二进制形式,这个过程称为编译(Compile)。
C语言代码经过编译以后,并没有生成最终的可执行文件(.exe 文件),而是生成了一种叫做目标文件(Object File)的中间文件(或者说临时文件)。目标文件也是二进制形式的,它和可执行文件的格式是一样的。对于 Visual C++,目标文件的后缀是.obj;对于 GCC,目标文件的后缀是.o。
链接(Link)其实就是一个“打包”的过程,它将所有二进制形式的目标文件和系统组件组合成一个可执行文件。完成链接的过程也需要一个特殊的软件,叫做链接器(Linker)。
随着我们我们编写的代码越来越多,最终需要将它们分散到多个源文件中,编译器每次只能编译一个源文件,生成一个目标文件,这个时候,链接器除了将目标文件和系统组件组合起来,还需要将编译器生成的多个目标文件组合起来。
再次强调,编译是针对一个源文件的,有多少个源文件就需要编译多少次,就会生成多少个目标文件。
markdown内容
今天顺便学了点markdown文档的编辑格式,在markdown文件中加空格需要加html标记中的 ,/br是不能用的,而且分号不可以省略(其实很好理解,漏了才显得没有程序员水平。。。)。