hadoop大数据平台的构建
目录
- hadoop概述
-
- 什么是hadoop?
- hadoop特点
- hadoop组成
- hadoop默认端口
- hadoop分布集群搭建
-
- 前置准备
-
- 关闭防火墙
- 修改各个节点的主机名
- 修改自己所用节点的IP映射
- 需要在所有节点上完成网络配置
- 时间同步(三台机器均执行)
- ssh免密(三台主机)
- zookeeper
- hadoop
-
- 安装hadoop
- 配置PATH变量
- 配置hadoop-env.sh
- 配置core-site.xml
- 配置hdfs-site.xml
- 配置yarn-env.sh
- 配置yarn-site.xml
- 配置mapred-site.xml
- slaves文件
- 远程拷贝
- 在master中格式化hadoop,并开启hadoop
hadoop概述
什么是hadoop?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。(摘自百度百科)
hadoop特点
1.高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖 。
2.高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3.高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快 。
4.高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配 。
hadoop组成
hdfs:分布式文件系统 Namenode:存放文件系统树及所有文件、目录的元数据
Namenode:存放文件系统树及所有文件、目录的元数据
Secondary Namenode :定期合并主Namenode的namespace image和edit log, 避免edit log过大,通过创建检查点checkpoint来合并。
Datanode:在本地文件系统存储文件块数据,以及块数据的校验和,读写请求可能来自namenode,也可能直接来自客户端。
ResourceManager JobTracker:负责调度DataNode上的工作。每个DataNode有一个TaskTracker,它们执行实际工作。,
NodeManager:执行任务。
DFSZKFailoverController:高可用时它负责监控NN的状态,并及时的把状态信息写入ZK。它通过一个独立线程周期性的调用NN上的一个特定接口来获取 NN的健康状态。FC也有选择谁作为Active NN的权利,因为最多只有两个节点,目前选择策略还比较简单(先到先得)
JournalNode:高可用情况下存放namenode的 editlog文件。
yarn

ResourceManager(RM)主要作用如下
(1)处理客户端请求
(2)监控NodeManager
(3)启动或监控ApplicationMaster
(4)资源的分配与调度
NodeManager(NM)主要作用如下
(1)管理单个节点上的资源
(2)处理来自ResourceManager的命令
(3)处理来自ApplicationMaster的命令
ApplicationMaster(AM)作用如下
(1)负责数据的切分
(2)为应用程序申请资源并分配给内部的任务
(3)任务的监控与容错
Container:YARN中的资源抽象,它封装了草个节点上的多维度资源,如内存、CPu、磁盘、网络等。
mapreduce
MapReduce是一个可用于大规模数据处理的分布式计算框架
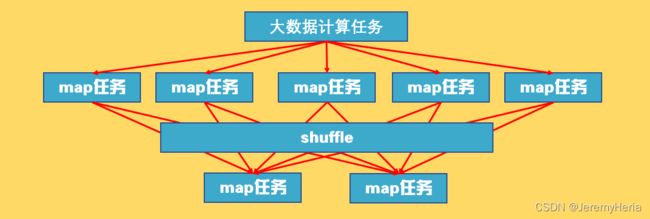
Map阶段并行处理输入数据
Reduce阶段对Map结果进行汇总
hadoop默认端口
dfs.namenode.http-address:50070
WEB界面中监控hdfs
SecondaryNameNade:50090
辅助名称节点端口号
dfs.datanode.address:50010
DataNode的数据传输端口
fs.defaultFS:9000
接收Client连接的RPC端口
yarn.resourcemanager.webapp.address:8088
WEB界面中监控任务执行状况
hadoop分布集群搭建
前置准备
这里我准备了三台centos7虚拟机,ip分别为
master 192.168.72.150
slave1 192.168.72.151
slave2 192.168.72.152
更改IP详见本篇博客
Failed to start LSB: Bring up/down解决方法
依次执行以下指令
systemctl stop NetworkManager
systemctl disable NetworkManager
#重新启动网络
systemctl start network.service
关闭防火墙
CentOS系统默认开启了防火墙,在开启 Hadoop 集群之前,需要关闭集群中每个节点的防火墙。有防火墙会导致 ping 得通但 telnet 端口不通,从而导致 DataNode 启动了,但 Live datanodes 为 0 的情况。
#查看防火墙状态
systemctl status firewalld
在 CentOS 6.x 中,可以通过如下命令关闭防火墙:
sudo service iptables stop # 关闭防火墙服务
sudo chkconfig iptables off # 禁止防火墙开机自启,就不用手动关闭了
若用是 CentOS 7,需通过如下命令关闭(防火墙服务改成了 firewall):
#关闭firewall
systemctl stop firewalld.service
#禁止firewall开机启动
systemctl disable firewalld.service
修改各个节点的主机名
sudo vim /etc/hostname
#192.168.72.150改为master
#192.168.72.151改为slave1
#192.168.72.152改为slave2
修改自己所用节点的IP映射
sudo vim /etc/hosts
例如本教程使用两个节点的名称与对应的 IP 关系如下:
192.168.72.150 master
192.168.72.151 slave1
192.168.72.152 slave2
修改完成后需要重启一下,重启后在终端中才会看到机器名的变化
需要在所有节点上完成网络配置
测试是否相互 ping 得通
ping Master -c 3 # 只ping 3次,否则要按 Ctrl+c 中断
ping Slave1 -c 3
时间同步(三台机器均执行)
echo "TZ='Asia/Shanghai'; export TZ" >> /etc/profile && source /etc/profile
# 下载ntp(三台机器)
yum install -y ntp
master 作为 ntp 服务器,修改 ntp 配置文件。(master 上执行)
vim /etc/ntp.conf
删除或注释默认的时钟源服务器

添加如下内容,使master做为本地的时钟源
server 127.127.1.0 #local clock
fudge 127.127.1.0 stratum 10 #stratum 设置为其它值也是可以的,其范围为 0~15
在master上面启动ntp服务
systemctl start ntpd.service
在slave1和slave2上同步
ntpdate master
查看定时任务服务状态
service crond status
在slave1和slave2上设置定时任务
注释:
crontab任务解读
格式:minute hour day month week commond
minute: 表示分钟,可以是从0到59之间的任何整数。
hour:表示小时,可以是从0到23之间的任何整数。
day:表示日期,可以是从1到31之间的任何整数。
month:表示月份,可以是从1到12之间的任何整数。
week:表示星期几,可以是从0到7之间的任何整数,这里的0或7代表星期日。
command:要执行的命令,可以是系统命令,也可以是自己编写的脚本文件。
星号():代表所有可能的值,例如month字段如果是星号,则表示在满足其它字段的制约条件后每月都执行该命令操作。**
逗号(,):可以用逗号隔开的值指定一个列表范围,例如,“1,2,5,7,8,9”
中杠(-):可以用整数之间的中杠表示一个整数范围,例如“2-6”表示“2,3,4,5,6”
正斜线(/):可以用正斜线指定时间的间隔频率,例如“0-23/2”表示每两小时执行一次。同时正斜线可以和星号一起使用,例如/10,如果用在minute字段,表示每十分钟执行一次。
crontab -e
*/10 * * * * /usr/sbin/ntpdate master#每10分钟同步一次
*/30 8-17 * * * /usr/sbin/ntpdate master#30分钟一次,早8-晚五
查看定时任务
crontab -l
ssh免密(三台主机)
dsa认证
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat /root/.ssh/id_dsa.pub >> /root/.ssh/authorized_keys
scp ~/.ssh/authorized_keys root@slave1:~/.ssh/
scp ~/.ssh/authorized_keys root@slave2:~/.ssh/
如果slave1和slave2没有.ssh文件夹,就先全部使用ssh localhost命令
rsa认证
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上
ssh-copy-id slave1
ssh-copy-id slave2
zookeeper
详见zookeeper安装博文(附脚本)
hadoop
安装以及修改配置文件的操作都只在master上做即可,之后用远程拷贝文件命令传递
安装hadoop
hadoop-2.7.3下载地址
将 Hadoop 解压到/usr/ 中。
tar -zxf hadoop-2.7.3.tar.gz -C /usr/hadoop
检查 Hadoop 是否可用
cd /usr/hadoop/hadoop-2.7.3 # 切换当前目录为 /usr/local/hadoop 目录
./bin/hadoop version # 查看 Hadoop 的版本信息
配置环境变量
打开/etc/profile文件
vi /etc/profile
在profile文件末尾添加hadoop路径:
##HADOOP_HOME
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
生成环境变量
source /etc/profile
自定义终端,执行 vim ~/.bashrc,加入一行
export PATH=$PATH:/usr/local/hadoop/bin:/usr/hadoop/sbin
重启(如果Hadoop命令不能用再重启)
sync
reboot
注释:
查看hadoop目录结构

(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
(1)默认配置文件:
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-2.7.2.jar/ core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-2.7.2.jar/ hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-2.7.2.jar/ yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-2.7.2.jar/ mapred-default.xml |
| (2)自定义配置文件: | |
| core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。 |
配置PATH变量
由于我们拥有三台机器搭建分布式系统,所以在配置文件前先对其进行分工
| Master | Slave1 | Slave2 | |
|---|---|---|---|
| HDFS | NameNode&Datanode | DataNode | SeconderyNameNode&Datanode |
| YARN | NodeManager | ResourceManager&NodeManager | NodeManager |
| 切换到Hadoop的配置文件目录 |
cd $HADOOP_HOME/etc/hadoop
配置hadoop-env.sh
vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_171
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
可参见该篇博文
配置core-site.xml
vi core-site.xml
<property>
<name>fs.default.namename>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/hadoop/hadoop-2.7.3/hdfs/tmpvalue>
<description>A base for other temporary directories.description>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>fs.checkpoint.periodname>
<value>3600value>
property>
<property>
<name>fs.checkpoint.sizename>
<value>67108864value>
property>
fs.defaultFS :文件系统主机和端口,格式为hdfs://主机名:端口/
io.file.buffer.size:流文件的缓冲区大小,默认4096
hadoop.tmp.dir:临时文件夹,默认/tmp/hadoop-${user.name }
如果在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的tmp目录即可。如果删除了NameNode机器的此目录,需要重新执行NameNode格式化的命令。
fs.checkpoint.period:设置两次相邻checkpoint之间的时间间隔,默认是1小时;
fs.checkpoint.size:设置一个edits文件大小的阈值,达到这个阈值,就强制执行一此checkpoint(即使此时没有达到period的时限),默认为64MB。
配置hdfs-site.xml
vi hdfs-site.xml
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/namevalue>
<final>truefinal>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/hadoop/hadoop-2.7.3/hdfs/datavalue>
<final>truefinal>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master:9001value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
dfs.replication:副本数
可用hadoop fsck -locations查看
dfs.namenode.name.dir:设置存放NameNode的文件路径
dfs.datanode.data.dir:设置datanode节点存储数据块文件的本地路径,通常可以设置多个,用逗号隔开
namenode.secondary.httpaddress : secondary namenode 的web地址
dfs.webhdfs.enabled:开启webHDFS服务
dfs.permissions:如果是true则在存取文件前检查权限,否则不检查
配置yarn-env.sh
vi yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_171
配置yarn-site.xml
vi yarn-site.xml
<property>
<name>yarn.resourcemanager.addressname>
<value>master:18040value>
<description>RM对客户端暴露的地址,客户端通过该地址向RM提交应用程序等description>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:18030value>
<description>RM对AM暴露的地址,AM通过地址想RM申请资源,释放资源等description>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master:18088value>
<description>RM对外暴露的web http地址,用户可通过该地址在浏览器中查看集群信息description>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:18025value>
<description>RM对NM暴露地址,NM通过该地址向RM汇报心跳,领取任务等description>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master:18141value>
<description>指定RM进程所在主机为master,端口为18141description>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
<description>NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序description>
property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
<description>需要设置Map Reduce启动shuffle服务description>
property>
yarn.resourcemanager.address:ResourceManager 对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等,默认为${yarn.resourcemanager.hostname}:8032
yarn.resourcemanager.scheduler.address:ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。默认为${yarn.resourcemanager.hostname}:8030
yarn.resourcemanager.webapp.address:RM对外暴露的web http地址,用户可通过该地址在浏览器中查看集群信息。默认为${yarn.resourcemanager.hostname}:8090
yarn.resourcemanager.resource-tracker.address:RM对NM暴露地址,NM通过该地址向RM汇报心跳,领取任务等,默认为${yarn.resourcemanager.hostname}:8031
yarn.resourcemanager.admin.address:指定RM进程所在主机为master,默认为${yarn.resourcemanager.hostname}:8033
yarn.nodemanager.aux-services:NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序
yarn.nodemanager.auxservices.mapreduce.shuffle.class:需要设置Map Reduce启动shuffle服务
配置mapred-site.xml
cp mapred-site.xml.template mapred-site.xml && vi mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
<description>向yarn申请资源description>
property>
slaves文件
vi slaves
master
slave1
slave2
远程拷贝
scp -r /usr/hadoop root@slave1:/usr/
scp -r /usr/hadoop root@slave2:/usr/
在master中格式化hadoop,并开启hadoop
cd /usr/hadoop/hadoop-2.7.3
# 格式化
hadoop namenode -format
# 启动hadoop
sbin/start-all.sh
# 验证(对照此前向三台主机分配的任务)
jps