PyTorch神经网络搭建入门
这里演示了使用Pytorch搭建神经网络的基本方法,需要说明的是,本文中作为示例的数学函数估算其实并不适合神经网络方法,建议使用 statsmodels或skleran。
技术路线
不管多复杂的神经网络,都需要以下步骤进行网络定义和参数优化:
- 定义网络:定义网络结构,通过继承
torch.nn.Module类实现,包括两部分,即各网络层的声明,和信息在网络层之间的传递关系;
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()#使用父类的构造方法
'''
这里添加神经网络的层级结构
'''
def forward(self,x):
'''
这里编写数据在各层级中的传递方法
'''
return y
-
定义优化器,选择库中的经典优化器,或者自行设计优化器,优化器参数一般为网络结构和单次训练的学习率,如
optimizer=torch.optim.SGD(net.parameters(),lr=0.5); -
定义损失函数,损失函数即计算预测结果与实际结果的差异,可以使用库中提供的方法,如
loss_f=torch.nn.MSELoss(); -
在定义完之后,开始一次一次的循环,对神经网络的参数(在PyTorch中是隐藏的)进行优化:
①先清空优化器里的梯度信息,optimizer.zero_grad();
②再将input传入,output=net(input) ,正向传播
③计算损失,loss=compute_loss(target,output) ,计算模型输出与真实值的误差;
④误差反向传播,loss.backward(),将误差传递回神经网络的各层;
⑤更新参数,optimizer.step(),更新神经网络参数。
安装
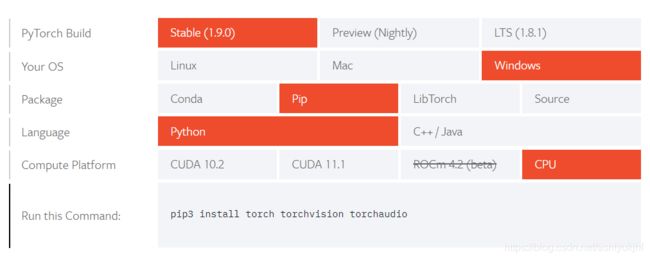
打开Pytorch官方网站,https://pytorch.org/get-started/locally/,选择版本、系统、安装方式、语言平台、CPU和GPU配置(装有英伟达显卡的电脑可以选择“CUDA”,否则选择“CPU”),然后将下方生成的代码复制到命令行。
引入模块
引入搭建神经网络的必备模块
import torch as t
from torch import nn
import torch.nn.functional as F
from torch.autograd import Variable as V
生成数据
使用Python自带功能,生成一组模拟数据
from random import random#生成范围在(0,1)随机数
x=[random() for i in range(100)]#生成100个随机自变量
y=[xx**2+0.2*random()-0.2*random() for xx in x]
#生成相应的因变量,并添加随机误差
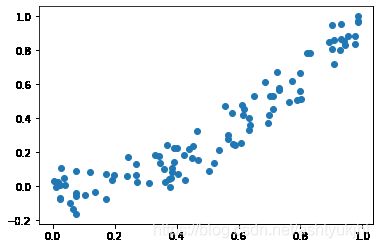
查看生成的数据图像
import matplotlib.pyplot as plt#用于显示图像
plt.scatter(x,y)
plt.show()
将列表(list)格式的数据转换为PyTorch张量(tensor),修改数据形状成为100×1的二维张量,再转换为变量(Variable )
x,y=t.tensor(x),t.tensor(y)#转换为tensor
x=x.view(-1,1)#修改张量形状,-1代表自动设定长度
y=y.view(-1,1)
x,y=V(x),V(y)
定义网络结构
网络结构对象通过继承torch.nn.Module来实现,对象中必须定义__init__()和forward()函数。
其中__init__()中定义了神经网络的结构,forward()定义了数据在神经网络中传递方式,调用模型即调用forward()。
class Net(nn.Module):
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()#使用父类的构造方法
self.hidden=nn.Linear(n_feature,n_hidden)#定义一个隐藏层
self.predict=nn.Linear(n_hidden,n_output)#定义一个输出层
def forward(self,x):
x=F.relu(self.hidden(x))
x=self.predict(x)
return x
net=Net(1,10,1)#实例化对象
print(net)#查看网络结构
'''
输出为:
Net(
(hidden): Linear(in_features=1, out_features=10, bias=True)
(predict): Linear(in_features=10, out_features=1, bias=True)
)
'''
选择优化器和损失函数
根据具体情况选择PyTorch中提供优化器和损失函数,这里仅作为示例。
opt=t.optim.SGD(net.parameters(),lr=0.5)#第一个参数为模型信息,第二个参数为学习率
loss_f=nn.MSELoss()
模型训练
通过反复训练,进行模型优化
for epoch in range(100):
pre=net(x)#使用模型进行预测
loss=loss_f(pre,y)#比较预测结果和真实值,计算损失值
opt.zero_grad()#每次计算梯度前将梯度清零
loss.backward()#损失值沿模型反向传递
opt.step()#使用优化器更新模型
print(epoch,loss)#查看损失
模型应用
使用模型进行预测
z=t.tensor([[0.5]])#定义一个张量
net(z)#预测结果
'''
输出:
tensor([[0.2511]])
'''
保存模型
将模型保存为文件,以便进行其他操作
t.save(net, 'net.pkl')#保存模型,参数为模型对象和文件名
net2 = t.load('net.pkl')#从已保存的模型文件加载
全部代码
import torch as t
from torch import nn
import torch.nn.functional as F
from torch.autograd import Variable as V
import matplotlib.pyplot as plt
from random import random
#生成数据
x=[random() for i in range(100)]
y=[xx**2+0.2*random()-0.2*random() for xx in x]
plt.scatter(x,y)
plt.show()
#数据转化为Pytorch变量
x,y=t.tensor(x),t.tensor(y)
x=x.view(-1,1)
y=y.view(-1,1)
x,y=V(x),V(y)
#定义神经网络
class Net(nn.Module):
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()
self.hidden=nn.Linear(n_feature,n_hidden)
self.predict=nn.Linear(n_hidden,n_output)
def forward(self,x):
x=F.relu(self.hidden(x))
x=self.predict(x)
return x
net=Net(1,10,1)
print(net)
#选择优化器
opt=t.optim.SGD(net.parameters(),lr=0.5)
loss_f=nn.MSELoss()
#训练模型
for epoch in range(100):
pre=net(x)
loss=loss_f(pre,y)
opt.zero_grad()
loss.backward()
opt.step()
print(epoch,loss)
#模型应用
z=t.tensor([[0.5]])
net(z)
#保存和读取模型
t.save(net, 'net.pkl')
net2 = t.load('net.pkl')