KDD2021 | 左右互搏:基于协同对比学习的自监督异质图神经网络
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
论文解读者:北邮 GAMMA Lab 硕士生 刘念

题目:Self-supervised Heterogeneous Graph Neural Network with Co-contrastive Learning
会议:KDD 2021
论文链接:https://arxiv.org/pdf/2105.09111.pdf
异质图中信息众多,语义复杂,谁来做自监督信号?谁与谁做对比?又该如何对比?孤掌难鸣,唯有两者合作、左右互搏, 方能协同优化、实现共赢。
1 介绍
最近,异质图神经网络(HGNNs)在处理异质信息网络(HIN)方面展现了优越的能力。大部分的HGNNs都遵循半监督学习的设定,然而实际应用中标签信息往往很难获得。而自监督学习由于能够自发地从数据本身挖掘监督信号,已经成为无监督设定下很好的选择。作为一种典型的自监督机制,对比学习(contrastive learning)通过从数据中抽取出正负样本,同时最大化正例间的相似度以及最小化负例间相似度,能够学到判别性的表示。尽管对比学习在CV和NLP领域得到了广泛应用,如何将它和HIN结合却尚未解决。
通过认真考虑HIN以及对比学习的特性,我们总结了三个需要解决的本质问题:
1)如何设计异质对比机制 HIN中包含复杂结构,例如元路径(meta-path),需要利用跨视图的对比学习机制来综合刻画。
2)如何在HIN中选择合适的视图 对于视图的基本要求是,能够刻画网络的局部结构和高阶结构。网络模式(network schema)反应了节点间的直接连接情况,捕捉局部结构;元路径通常被用来抽取多跳关系。
3)如何设置困难的对比任务 简单的正负关系很容易被捕获,模型学到的信息有限。增加对比任务的难度,可通过增加两个视图间的差异,或者生成更高质量的负样本来实现。
在本篇文章中,我们提出了一个新的基于协同对比学习的异质图神经网络框架,简称HeCo。HeCo采用跨视图的对比机制,选择网络模式和元路径作为两个视图,结合视图掩盖机制,分别学得两个视图下的节点表示。之后,利用跨视图对比学习,使得两个视图协同监督。此外,我们还提出两个HeCo扩展,通过生成更高质量的负例,提升最终效果。
2 模型介绍

模型整体流程如上图所示。
2.1 节点特征转换
首先,我们需要将不同类型节点的特征映射到同一空间中,如(a)所示。对于类型的节点,利用类型特别的映射矩阵进行投影:
是投影之后i的特征。
2.2 网络模式视图下的编码器
假设节点与种其他类型的节点相连,对于第类型的邻居,利用节点级别的注意力进行融合:
其中注意力的计算公式如下:
是类型的注意力向量。请注意,在构建时我们并没有聚合所有的邻居,而是随机选取个邻居。这样做可以保证每个节点从邻居中吸收同样的信息量,同时增加了节点表示的多样性,使得接下来的对比学习更具挑战性。
在得到每种类型的表示后,我们利用类型级别的注意力机制进行融合,得到网络模式下的节点表示:
2.3 元路径视图下的编码器
给定条预先定义的元路径,对于元路径,我们可以得到节点基于该条元路径的邻居。利用GCN [1] 对进行聚合:
是节点基于的表示。之后,利用语义注意力机制聚合每条元路径,得到元路径视图下的节点表示,公式如下:
2.4 视图掩盖机制

在上述生成过程中,我们隐去了目标类型节点的信息,只吸收不同类型邻居的信息;在生成的过程中,隐去了元路径上其他类型节点的信息,只吸收和目标节点类型相同的节点信息。这样,从两种视图下学到的节点表示,即相关又互补,互相监督彼此的训练,呈现协同优化的趋势。
2.5 协同对比优化
在得到和之后,将它们映射到对比损失计算的空间中:
接下来,我们需要定义HIN中的正负例。不同于CV,由于HIN中存在大量的边,节点间彼此高度相关。为了反映节点的局部结构,我们定义两个节点彼此互为正例,当它们可由许多条元路径相连。对于节点和,定义函数计数它们间的元路径数量:
对于,选择最大的个节点作为正例集合,其余节点作为负例集合。基于此,我们进行跨视图的对比学习:
表示和间的cosine相似度。不同于一般的对比loss,我们同时最大化多个正例对间的相似度;此外,上述公式表明,对于网络模式下的节点表示,我们利用在元路径模式下正负样本的表示来计算相似度,从而达到跨视图对比的目的。得到的方式相同。总的损失函数如下:
2.6 模型扩展
为了得到更高质量的负样本,我们提出了两种扩展模型:
1) HeCo_GAN 该扩展利用GAN的生成对抗思想,通过判别器和生成器间的对抗,使得生成器生成靠近正例分布的逼真的负例。
2) HeCo_MU 该扩展受启发于MixUp [2]、MoCHi [3]等方法,将和目标节点最相似的K个负例进行随机相加,生成更多高质量的负例。
3 实验
3.1 节点分类

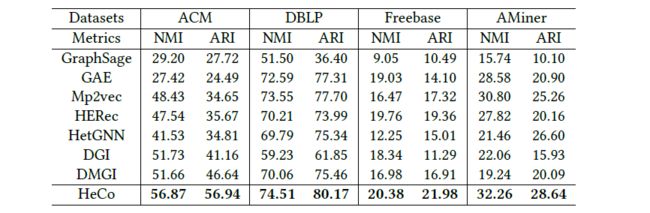
3.2 节点聚类
3.3 模型扩展

3.4 协同趋势

由上图可看出,网络模式和元路径两种视图间呈现出协同优化趋势。例如在ACM中,PAP的注意力值更高,相应的A类型邻居的注意力值更高;在AMiner中,PRP的注意力值更高,相应的R类型邻居的注意力值更高。
参考文献
[1] Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In ICLR.
[2] Hongyi Zhang, Moustapha Cissé, Yann N. Dauphin, and David Lopez-Paz. 2018. mixup: Beyond Empirical Risk Minimization. In ICLR.
[3] Yannis Kalantidis, Mert Bülent Sariyildiz, Noé Pion, Philippe Weinzaepfel, and Diane Larlus. 2020. Hard Negative Mixing for Contrastive Learning. In NeurIPS.
本期责任编辑:杨成
本期编辑:刘佳玮
北邮 GAMMA Lab 公众号
主编:石川
责任编辑:王啸、杨成
编辑:刘佳玮
长按下图并点击“识别图中二维码”
即可关注北邮 GAMMA Lab 公众号

我知道你在看哟

点击“阅读原文”查看更多精彩