【模糊神经网络】基于模糊神经网络的倒立摆轨迹跟踪控制
临近春节没啥事做,突然想起前两年未完成的模糊神经网络,当时是学了一段时间,但是到最后矩阵求偏导那块始终不对,最后也不了了之了,趁最近有空,想重新回顾回顾,看看会不会产生新的想法。经过不断尝试后,竟然达到了想要的效果,所以简要记录一下留个笔记。以下内容只讲干货,不玩虚的。
0 引言
模糊神经网络结合了模糊控制与神经网络两者的优点,不仅具备对非线性、时变、模型不完全系统的控制,同时还具备很好的自学习和自适应能力。模糊神经网络主要用于模型控制以及函数逼近等领域。
1 倒立摆模型
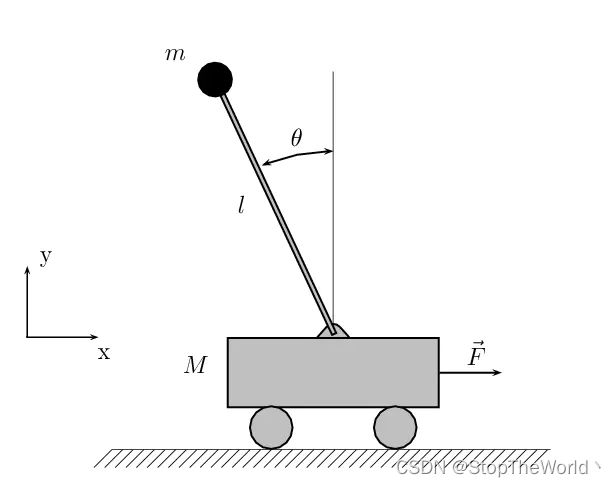
被控对象为单级倒立摆,其动力学方程为 x ˙ 1 = x 2 x ˙ 2 = f ( x ) + g ( x ) u \dot{x}_1=x_2 \\ \dot{x}_2=f\left( \boldsymbol{x} \right) +g\left( \boldsymbol{x} \right) u x˙1=x2x˙2=f(x)+g(x)u其中, f ( x ) = g sin x 1 − m l x 2 2 cos x 1 sin x 1 / ( m c + m ) l ( 4 / 3 − m cos 2 x 1 / ( m c + m ) ) f\left( \boldsymbol{x} \right) =\frac{g\sin x_1-mlx_{2}^{2}\cos x_1\sin x_1/\left( m_c+m \right)}{l\left( 4/3-m\cos ^2x_1/\left( m_c+m \right) \right)} f(x)=l(4/3−mcos2x1/(mc+m))gsinx1−mlx22cosx1sinx1/(mc+m); g ( x ) = cos x 1 / ( m c + m ) l ( 4 / 3 − m cos 2 x 1 / ( m c + m ) ) g\left( \boldsymbol{x} \right) =\frac{\cos x_1/\left( m_c+m \right)}{l\left( 4/3-m\cos ^2x_1/\left( m_c+m \right) \right)} g(x)=l(4/3−mcos2x1/(mc+m))cosx1/(mc+m), x 1 x_1 x1 和 x 2 x_2 x2 分别为摆角和摆速, g g g 为重力加速度, m c m_c mc 为小车质量, m m m 摆的质量, l l l 为摆长的一半, u u u 为控制输入。
2 控制器设计
2.1 模糊神经网络结构
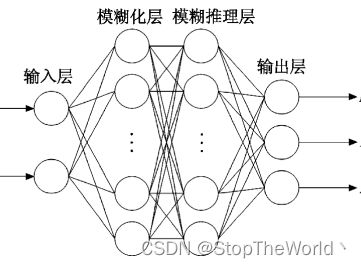
第一层:输入层。输入层为双输入,分别为系统偏差 e e e 和系统偏差变化率 e ˙ \dot{e} e˙,然后通过激活函数 f 1 ( x ) f_1\left( x \right) f1(x)输出到模糊化层。 f 1 ( x i ) = x i f_1\left( x_i \right) =x_i f1(xi)=xi 第二层:模糊化层。本层的激活函数即隶属函数,采用逼近能力较好的高斯函数 f 2 ( i , j ) = exp [ − ( x i − c i j ) 2 2 σ i j 2 ] f_2\left( i,j \right) =\exp \left[ -\frac{\left( x_i-c_{ij} \right) ^2}{2\sigma _{ij}^{2}} \right] f2(i,j)=exp[−2σij2(xi−cij)2] 其中, i = 1 , 2 ; j = 1 , 2 , . . . n ; i=1,2;j=1,2,...n; i=1,2;j=1,2,...n; c i j c_{ij} cij 和 σ i j \sigma _{ij} σij 分别为高斯函数的中心和基宽。
第三层:模糊推理层。本层使用的激活函数为 φ ( j ) = ∏ j = 1 N f 2 ( i , j ) f 3 ( j ) = φ ( j ) ∑ j = 1 N φ ( j ) \varphi \left( j \right) =\prod_{j=1}^N{f_2\left( i,j \right)} \\ f_3\left( j \right) =\frac{\varphi \left( j \right)}{\sum_{j=1}^N{\varphi \left( j \right)}} φ(j)=j=1∏Nf2(i,j)f3(j)=∑j=1Nφ(j)φ(j)其中, N = ∏ i = 1 n n i N=\prod_{i=1}^n{n_i} N=∏i=1nni,为神经元和。
第四层:输出层。本层主要是输出模型控制量 u u u 。 f 4 ( i ) = ω ⋅ f 3 = ∑ j = 1 N w ( i , j ) ⋅ f 3 ( j ) f_4\left( i \right) =\boldsymbol{\omega }\cdot f_3=\sum_{j=1}^N{\boldsymbol{w}\left( i,j \right) \cdot f_3\left( j \right)} f4(i)=ω⋅f3=j=1∑Nw(i,j)⋅f3(j)其中, ω \boldsymbol{\omega } ω 为模糊推理层与输出层的连接权矩阵。
2.2 模糊神经网络的训练算法
LM算法结合高斯牛顿算法和梯度下降法,兼具局部收敛法和全局搜索的优点。但是,由于LM算法的计算复杂度和存储容量会随着训练样本数目的增加而增加,为了解决该问题,利用IALM算法优化所有的参数。参数向量 Θ ( t ) \boldsymbol{\varTheta }\left( t \right) Θ(t) 的更新规则如下: Θ ( t + 1 ) = Θ ( t ) − ( Ψ ( t ) + η ( t ) I ) − 1 Ω ( t ) \boldsymbol{\varTheta }\left( t+1 \right) =\boldsymbol{\varTheta }\left( t \right) -\left( \boldsymbol{\varPsi }\left( t \right) +\eta \left( t \right) \boldsymbol{I} \right) ^{-1}\boldsymbol{\varOmega }\left( t \right) Θ(t+1)=Θ(t)−(Ψ(t)+η(t)I)−1Ω(t)其中, Θ ( t ) = [ ω ( t ) , c ( t ) , σ ( t ) ] T \boldsymbol{\varTheta }\left( t \right) =\left[ \boldsymbol{\omega }\left( t \right) , \boldsymbol{c}\left( t \right) , \boldsymbol{\sigma }\left( t \right) \right] ^{\mathrm{T}} Θ(t)=[ω(t),c(t),σ(t)]T 为参数向量, I \boldsymbol{I} I 为用于矩阵求逆时避免奇异的单位矩阵, Ψ ( t ) \boldsymbol{\varPsi }\left( t \right) Ψ(t) 为准海森(quasi-Hessian)矩阵, Ω ( t ) \boldsymbol{\varOmega }\left( t \right) Ω(t) 为梯度向量。自适应学习率 η ( t ) \boldsymbol{\eta }\left( t \right) η(t) 的调整规则如下: η ( t ) = β m ∥ e ( t ) ∥ + ( 1 − β m ) ∥ Ω ( t ) ∥ \boldsymbol{\eta }\left( t \right) =\beta _m\left\| \boldsymbol{e}\left( t \right) \right\| +\left( 1-\beta _m \right) \left\| \boldsymbol{\varOmega }\left( t \right) \right\| η(t)=βm∥e(t)∥+(1−βm)∥Ω(t)∥其中, β m ( 0 < β m < 1 ) \beta _m\left( 0<\beta _m<1 \right) βm(0<βm<1) 为预设的常量, Ψ ( t ) \boldsymbol{\varPsi }\left( t \right) Ψ(t) 和 Ω ( t ) \boldsymbol{\varOmega }\left( t \right) Ω(t) 分别为所有样本的子矩阵 ψ p ( t ) \boldsymbol{\psi }_p\left( t \right) ψp(t) 和子向量 ω p ( t ) \boldsymbol{\omega }_p\left( t \right) ωp(t) 的累加,即 Ψ ( t ) = ∑ p = 1 P ψ p ( t ) Ω ( t ) = ∑ p = 1 P ω p ( t ) \boldsymbol{\varPsi }\left( t \right) =\sum_{p=1}^P{\boldsymbol{\psi }_p\left( t \right)} \\ \boldsymbol{\varOmega }\left( t \right) =\sum_{p=1}^P{\boldsymbol{\omega }_p\left( t \right)} Ψ(t)=p=1∑Pψp(t)Ω(t)=p=1∑Pωp(t)其中,子矩阵 ψ p ( t ) \boldsymbol{\psi }_p\left( t \right) ψp(t) 和子向量 ω p ( t ) \boldsymbol{\omega }_p\left( t \right) ωp(t) 分别定义为 ψ p ( t ) = J ˙ p T ( t ) J ˙ P ( t ) Ω ( t ) = J ˙ p T ( t ) e P ( t ) \boldsymbol{\psi }_p\left( t \right) =\dot{J}_{p}^{\mathrm{T}}\left( t \right) \dot{J}_P\left( t \right) \\ \boldsymbol{\varOmega }\left( t \right) =\dot{J}_{p}^{\mathrm{T}}\left( t \right) e_P\left( t \right) ψp(t)=J˙pT(t)J˙P(t)Ω(t)=J˙pT(t)eP(t)其中, e P ( t ) e_P\left( t \right) eP(t) 为对于第 p p p 个样本,期望输出和网络实际输出之间的误差 e P ( t ) = y d p ( t ) − y p ( t ) , p = 1 , 2 , . . . P e_P\left( t \right) =y_{d}^{p}\left( t \right) -y^p\left( t \right) , p=1,2,...P eP(t)=ydp(t)−yp(t),p=1,2,...P, J ˙ p ( t ) \dot{J}_p\left( t \right) J˙p(t) 为 J a c o b i a n \mathrm{Jacobian} Jacobian 矩阵的行向量,即 J ˙ p ( t ) = [ ∂ e p ∂ w 1 , . . . , ∂ e p ∂ w r , ∂ e p ∂ c 11 , . . . , ∂ e p ∂ c i j , . . . , ∂ e p ∂ c n r , ∂ e p ∂ σ 11 , . . . , ∂ e p ∂ σ i j , . . . , ∂ e p ∂ σ n r ] \dot{J}_p\left( t \right) =\left[ \frac{\partial e_p}{\partial w_1},...,\frac{\partial e_p}{\partial w_r},\frac{\partial e_p}{\partial c_{11}},...,\frac{\partial e_p}{\partial c_{ij}},...,\frac{\partial e_p}{\partial c_{nr}},\frac{\partial e_p}{\partial \sigma _{11}},...,\frac{\partial e_p}{\partial \sigma _{ij}},...,\frac{\partial e_p}{\partial \sigma _{nr}} \right] J˙p(t)=[∂w1∂ep,...,∂wr∂ep,∂c11∂ep,...,∂cij∂ep,...,∂cnr∂ep,∂σ11∂ep,...,∂σij∂ep,...,∂σnr∂ep]根据梯度下降学习算法的更新规则, J a c o b i a n \mathrm{Jacobian} Jacobian 矩阵行向量的元素可表示为 ∂ e p ( t ) ∂ w j ( t ) = − h j ( t ) ∂ e p ( t ) ∂ c i j ( t ) = − w j ( t ) ∑ k ≠ j r φ k ( t ) ( ∑ k = 1 r φ k ( t ) ) 2 ∏ k ≠ i n μ k j ( t ) ∂ μ i j ( t ) ∂ c i j ( t ) ∂ e p ( t ) ∂ σ i j ( t ) = − w j ( t ) ∑ k ≠ j r φ k ( t ) ( ∑ k = 1 r φ k ( t ) ) 2 ∏ k ≠ i n μ k j ( t ) ∂ μ i j ( t ) ∂ σ i j ( t ) \frac{\partial e_p\left( t \right)}{\partial w_j\left( t \right)}=-h_j\left( t \right) \\ \frac{\partial e_p\left( t \right)}{\partial c_{ij}\left( t \right)}=-w_j\left( t \right) \frac{\sum_{k\ne j}^r{\varphi _k\left( t \right)}}{\left( \sum_{k=1}^r{\varphi _k\left( t \right)} \right) ^2}\prod_{k\ne i}^n{\mu _{kj}\left( t \right) \frac{\partial \mu _{ij}\left( t \right)}{\partial c_{ij}\left( t \right)}} \\ \frac{\partial e_p\left( t \right)}{\partial \sigma _{ij}\left( t \right)}=-w_j\left( t \right) \frac{\sum_{k\ne j}^r{\varphi _k\left( t \right)}}{\left( \sum_{k=1}^r{\varphi _k\left( t \right)} \right) ^2}\prod_{k\ne i}^n{\mu _{kj}\left( t \right) \frac{\partial \mu _{ij}\left( t \right)}{\partial \sigma _{ij}\left( t \right)}} ∂wj(t)∂ep(t)=−hj(t)∂cij(t)∂ep(t)=−wj(t)(∑k=1rφk(t))2∑k=jrφk(t)k=i∏nμkj(t)∂cij(t)∂μij(t)∂σij(t)∂ep(t)=−wj(t)(∑k=1rφk(t))2∑k=jrφk(t)k=i∏nμkj(t)∂σij(t)∂μij(t)其中, ∂ μ i j ( t ) ∂ c i j ( t ) = 2 ( x i ( t ) − c i j ( t ) ) exp ( − ( x i ( t ) − c i j ( t ) ) 2 / σ i j 2 ( t ) ) σ i j 2 ( t ) ∂ μ i j ( t ) ∂ σ i j ( t ) = 2 ( x i ( t ) − c i j ( t ) ) 2 exp ( − ( x i ( t ) − c i j ( t ) ) 2 / σ i j 2 ( t ) ) σ i j 3 ( t ) \frac{\partial \mu _{ij}\left( t \right)}{\partial c_{ij}\left( t \right)}=\frac{2\left( x_i\left( t \right) -c_{ij}\left( t \right) \right) \exp \left( -\left( x_i\left( t \right) -c_{ij}\left( t \right) \right) ^2/\sigma _{ij}^{2}\left( t \right) \right)}{\sigma _{ij}^{2}\left( t \right)} \\ \frac{\partial \mu _{ij}\left( t \right)}{\partial \sigma _{ij}\left( t \right)}=\frac{2\left( x_i\left( t \right) -c_{ij}\left( t \right) \right) ^2\exp \left( -\left( x_i\left( t \right) -c_{ij}\left( t \right) \right) ^2/\sigma _{ij}^{2}\left( t \right) \right)}{\sigma _{ij}^{3}\left( t \right)} ∂cij(t)∂μij(t)=σij2(t)2(xi(t)−cij(t))exp(−(xi(t)−cij(t))2/σij2(t))∂σij(t)∂μij(t)=σij3(t)2(xi(t)−cij(t))2exp(−(xi(t)−cij(t))2/σij2(t)) 至此,就是IALM算法的所有公式,根据以上步骤,便可编写出模糊神经网络各层的程序以及参数向量的学习算法,控制器程序也就得到了。
IALM算法相比LM算法来说,可以直接计算准海森矩阵 Ψ ( t ) \boldsymbol{\varPsi }\left( t \right) Ψ(t)和梯度向量 Ω ( t ) \boldsymbol{\varOmega }\left( t \right) Ω(t),不需要执行 J a c o b i a n \mathrm{Jacobian} Jacobian 矩阵的乘法,从而降低了算法计算复杂度,并且自适应学习率 η ( t ) \boldsymbol{\eta }\left( t \right) η(t) 也有助于加快学习速度和提高泛化能力。
3 模型搭建与仿真
仿真目的:使用模糊神经网络控制器控制倒立摆完成轨迹跟踪运动。
在Simulink中搭建如下图所示的系统模型:
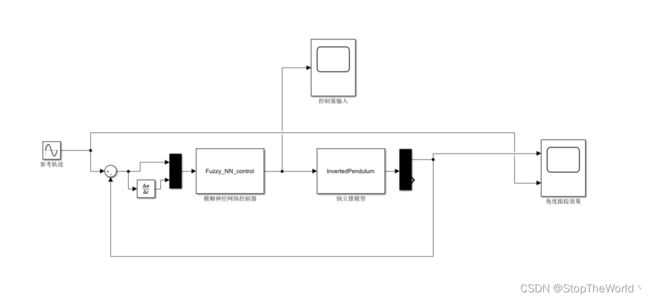
参数设置:取 x 1 = θ x_1=\theta x1=θ ,期望轨迹为 θ d ( t ) = 0.1 sin ( t ) \theta _{\mathrm{d}}\left( t \right) =0.1\sin \left( t \right) θd(t)=0.1sin(t) ,系统的初始状态为 [ π / 60 , 0 ] \left[ \pi /60, 0 \right] [π/60,0] ,网络初始权值取随机值,宽度取2,中心取-2至2 。模糊神经网络控制器的输入为误差和误差变化率,输出为控制量。
仿真结果
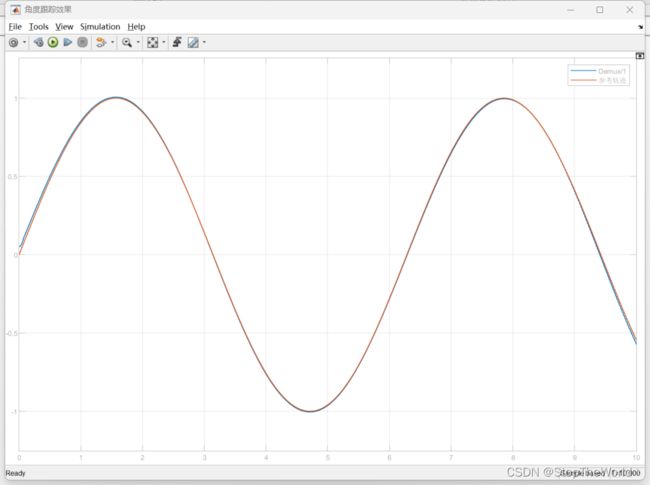
角度跟踪效果
角度跟踪误差
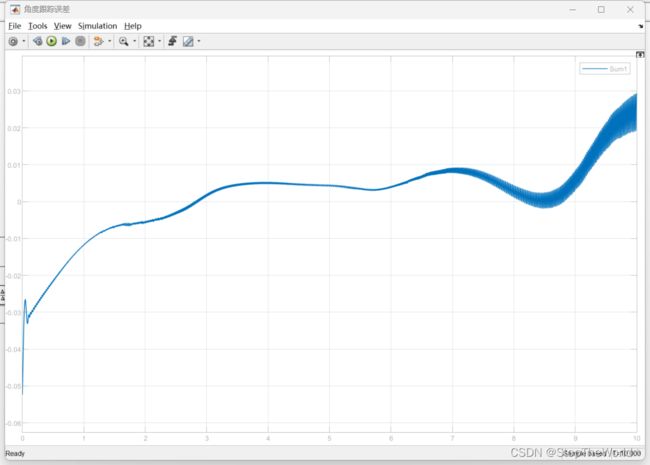
仿真分析
根据仿真结果可得,角度跟踪效果良好,角度跟踪误差在1e-2数量级,较好的完成轨迹跟踪的目的,因此可得,模糊神经网络控制器设计成功。
4 总结
模糊神经网络控制器的仿真程序比较复杂,涉及到很多数学运算,尤其是矩阵运算以及各种函数求导,在编写代码的时候要特别注意矩阵的维度问题。
回想前两年学习的过程,我突然想到最开始我想用李雅普诺夫稳定性来更新神经网络权值,但最后始终有一个矩阵求偏导问题解决不了,而这次我用的梯度下降法来更新神经网络,各个矩阵求导公式也比较清晰,所以能够完成复现。
模糊神经网络仿真初见成效,也算是解决了历史遗留问题,心里舒服多了。
5 参考文献
[1] 周红标,张钰,柏小颖,等. 基于自适应模糊神经网络的非线性系统模型预测控制[J]. 化工学报,2020,71(7):3201-3212. DOI:10.11949/0438-1157.20191531.
[2] 陶征勇,童仲志,侯远龙,等. 基于模糊神经网络的破障武器PID控制[J]. 电光与控制,2020,27(9):99-104. DOI:10.3969/j.issn.1671-637X.2020.09.020.
[3] 张璐,张嘉成,韩红桂,等. 基于模糊神经网络的污水处理生化除磷过程控制[J]. 化工学报,2020,71(3):1217-1225. DOI:10.11949/0438-1157.20191514.
[4] 徐智浩,李胜,张瑞雷,等. 基于LuGre摩擦模型的机械臂模糊神经网络控制[J]. 控制与决策,2014(6):1097-1102. DOI:10.13195/j.kzyjc.2013.0510.